Python爬虫,爬取百度百科词条
2017-09-03 20:03
756 查看
看了慕课网的一个网络爬虫教程。模仿着写了一个简单的爬取百度百科的例子。
(1)安装Beautifulsoup4
Beautifulsoup是Python的一个网页解析库,使用起来很方便。http://cuiqingcai.com/1319.html这个链接是介绍如何使用。这个库是需要安装的,进入Pthon安装目录下面的Scripts目录,执行pip install beautifulsoup进行安装。
(2)爬虫具体实现
爬虫分为5个模块,调度模块、网页下载模块、网页解析模块、URL管理模块、输出模块。
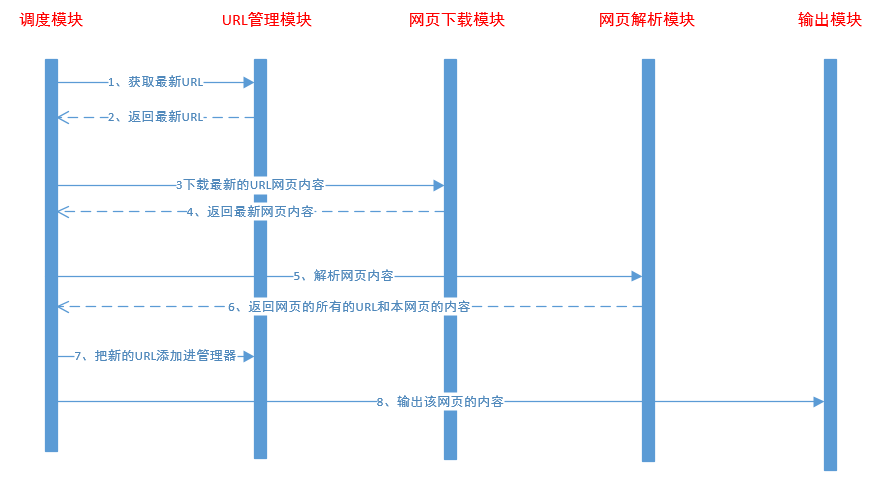
URL管理模块,负责保存最新的网页URL,每次取出最新的URL进行爬取。
#coding=utf8
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
#添加新的url
def _add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
#批量添加url
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self._add_new_url(url)
#是否有新的url
def has_new_url(self):
return len(self.new_urls) != 0
#获取新的url
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
URL下载模块,负责把网页的内容下载下来,使用urllib2库进行下载。
#coding utf8
import urllib2
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib2.urlopen(url);
if response.getcode == 200:
return None
return response.read()
URL解析模块,使用Beautifulsoup把当前网页的其他链接和网页简介解析出来。
# coding:utf-8
import urlparse
from bs4 import BeautifulSoup
import re
class HtmlParser(object):
def parser(self, page_url, html_content):
if page_url is None or html_content is None:
return
soup = BeautifulSoup(html_content, "html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
links = soup.find_all('a', href=re.compile(r'/item/'))
for link in links:
new_url = link["href"]
new_url_full = urlparse.urljoin(page_url, new_url)
new_urls.add(new_url_full)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
res_data['url'] = page_url
# <dd class="lemmaWgt-lemmaTitle-title"> <h1>Python</h1>
title_node = soup.find('dd', class_="lemmaWgt-lemmaTitle-title").find('h1')
res_data['title'] = title_node.get_text()
# <div class="lemma-summary" label-module="lemmaSummary">
summary_node = soup.find("div", class_="lemma-summary")
res_data['summary'] = summary_node.get_text()
return res_data
输出模块,负责把解析的网页内容保存起来。
#coding=utf-8
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self,data):
if data is None:
return
self.datas.append(data)
def outpute_html(self):
fout = open("outputer.html",'w')
fout.write("<html>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s<td>" % data['url'])
fout.write("<td>%s<td>" % data['title'].encode('utf-8'))
fout.write("<td>%s<td>" % data['summary'].encode('utf-8'))
fout.write("</tr>")
fout.write("</html>")
fout.write("</body>")
fout.write("</table>")
最后是调度模块,把各个模块之间的功能调度起来
#coding:utf8
import url_manager
import html_downloader
import html_outputer
import html_parser
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser();
self.outputer = html_outputer.HtmlOutputer()
pass
def craw(self, root_url):
self.urls._add_new_url(root_url)
count = 1;
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print new_url
#得到url的内容
html_content = self.downloader.download(new_url)
#得到url的内容和url
new_urls,new_data = self.parser.parser(new_url,html_content)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
except:
print "splider failed"
if (count == 10):
break
count = count + 1;
self.outputer.outpute_html()
if __name__ == "__main__":
root_url = "https://baike.baidu.com/item/Python/407313"
obj_splider = SpiderMain()
obj_splider.craw(root_url)
工程目录如下:
源码路径如下,感兴趣的朋友可以去下载:
https://github.com/HelloKittyNII/Spider/tree/master/baike_spider
(1)安装Beautifulsoup4
Beautifulsoup是Python的一个网页解析库,使用起来很方便。http://cuiqingcai.com/1319.html这个链接是介绍如何使用。这个库是需要安装的,进入Pthon安装目录下面的Scripts目录,执行pip install beautifulsoup进行安装。
(2)爬虫具体实现
爬虫分为5个模块,调度模块、网页下载模块、网页解析模块、URL管理模块、输出模块。
URL管理模块,负责保存最新的网页URL,每次取出最新的URL进行爬取。
#coding=utf8
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
#添加新的url
def _add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
#批量添加url
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self._add_new_url(url)
#是否有新的url
def has_new_url(self):
return len(self.new_urls) != 0
#获取新的url
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
URL下载模块,负责把网页的内容下载下来,使用urllib2库进行下载。
#coding utf8
import urllib2
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib2.urlopen(url);
if response.getcode == 200:
return None
return response.read()
URL解析模块,使用Beautifulsoup把当前网页的其他链接和网页简介解析出来。
# coding:utf-8
import urlparse
from bs4 import BeautifulSoup
import re
class HtmlParser(object):
def parser(self, page_url, html_content):
if page_url is None or html_content is None:
return
soup = BeautifulSoup(html_content, "html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
links = soup.find_all('a', href=re.compile(r'/item/'))
for link in links:
new_url = link["href"]
new_url_full = urlparse.urljoin(page_url, new_url)
new_urls.add(new_url_full)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
res_data['url'] = page_url
# <dd class="lemmaWgt-lemmaTitle-title"> <h1>Python</h1>
title_node = soup.find('dd', class_="lemmaWgt-lemmaTitle-title").find('h1')
res_data['title'] = title_node.get_text()
# <div class="lemma-summary" label-module="lemmaSummary">
summary_node = soup.find("div", class_="lemma-summary")
res_data['summary'] = summary_node.get_text()
return res_data
输出模块,负责把解析的网页内容保存起来。
#coding=utf-8
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self,data):
if data is None:
return
self.datas.append(data)
def outpute_html(self):
fout = open("outputer.html",'w')
fout.write("<html>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s<td>" % data['url'])
fout.write("<td>%s<td>" % data['title'].encode('utf-8'))
fout.write("<td>%s<td>" % data['summary'].encode('utf-8'))
fout.write("</tr>")
fout.write("</html>")
fout.write("</body>")
fout.write("</table>")
最后是调度模块,把各个模块之间的功能调度起来
#coding:utf8
import url_manager
import html_downloader
import html_outputer
import html_parser
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser();
self.outputer = html_outputer.HtmlOutputer()
pass
def craw(self, root_url):
self.urls._add_new_url(root_url)
count = 1;
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print new_url
#得到url的内容
html_content = self.downloader.download(new_url)
#得到url的内容和url
new_urls,new_data = self.parser.parser(new_url,html_content)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
except:
print "splider failed"
if (count == 10):
break
count = count + 1;
self.outputer.outpute_html()
if __name__ == "__main__":
root_url = "https://baike.baidu.com/item/Python/407313"
obj_splider = SpiderMain()
obj_splider.craw(root_url)
工程目录如下:
源码路径如下,感兴趣的朋友可以去下载:
https://github.com/HelloKittyNII/Spider/tree/master/baike_spider

相关文章推荐
- Python3_第一个简单爬虫开发_爬取百度百科1000个词条_参照慕课网教程实现
- Python3爬虫之四简单爬虫架构【爬取百度百科python词条网页】
- Python 爬虫实例(爬百度百科词条)
- Python爬虫----实例: 抓取百度百科Python词条相关1000个页面数据
- Python开发爬虫爬取百度百科词条信息(源码下载)
- 实践项目十:爬取百度百科Python词条相关1000个页面数据(慕课简单爬虫实战)
- Python爬虫爬取百度百科词条
- python爬虫-百度百科词条
- 用Python进行简单的爬虫(从Python百度百科中提取词条)
- python爬虫-百度百科词条
- python爬虫爬取词条百度百科
- python爬虫-百度百科词条
- 简单的python爬虫(爬取百度百科词条)
- Python简单爬虫开发的学习笔记整理(爬取百度百科词条)
- python爬虫-百度百科词条
- Python基础爬虫实战实例----爬取1000个Python百度百科词条及相关词条的标题和简介
- Java爬虫爬取python百度百科词条及相关词条页面
- 使用python实现简单的百度百科词条爬虫
- 慕课爬虫实战 爬取百度百科Python词条相关1000个页面数据
- Python爬虫完整案例 - 爬取百度百科词条信息