【算法】图的最小生成树(Prim算法)
2017-09-02 12:06
295 查看
写在前面:从今年1月到现在,准备考研大概也有半年多了,前一阵子因为准备腾讯的简历花了几天,还不知道鹅厂给不给我笔试的机会,就当一次职场实践了。准备考研给我的感觉跟考证完全不一样,考证没有名额的限制,只要你过线,就发给你证;考研就不同了,一群人抢那几个名额,过线还不一定顶用,更何况现在一堆的名师啊,机构啊做宣传,划重点,现在独自默默看书的我有压力,感觉学习就变味了TAT。。。完全成了应试。。。这样以来,学习真的就有了捷径么?
回归正题,今天要介绍的是图的最小生成树,也叫做最小代价。最小生成树是针对无向图而言的。临时百度科普了一下应用,百科上举的一个例子是在各个地区之间铺设光缆,并保证各城市连通。学过数据通信的童鞋应该知道,光纤铺设的成本是相对双绞线啥的要更高。我们可以这样想,各城市可以看成一个一个顶点;架设在城市之间的光缆可以看作是边;这些光缆有的长,有的短,自然每一段的总价就不同了,这个价格,就可以看作是权值。为了省钱,降低成本,是不是要寻找一个路径,攘括了所有的城市,并且费用最少呢?这就是最小生成树了。
我感觉学习算法最重要的是要清楚它是怎么做的,一步一步做,把自己想象成计算机,而不是人类。
下面,我们就来看看最小生成树的Prim算法是怎么做的。
主要思想:以顶点为主线,构成生成树。把图的顶点分成两类,一类是生成树中的点(类A),另一类是图余下的点(类B)。从与类A中的点相邻接的,属于类B的点中,选择权值最小的边,把它加入到生成树中,直到图中所有顶点被加入类A。
我们今天要实现的目标是:计算最小生成树的和
所使用图的存储结构:邻接矩阵
所使用的其他数据结构:int vset
//n为图的顶点个数,用于标识某个点是否被处理。1已被处理;0未被处理
int lowcost
//n为图的顶点个数,用于存储与最小生成树顶点所邻接的边的最小权值
int v //指向候选顶点
好,我们开始,以下都是手画,画的不好还请见谅。
1、图的结构和邻接矩阵
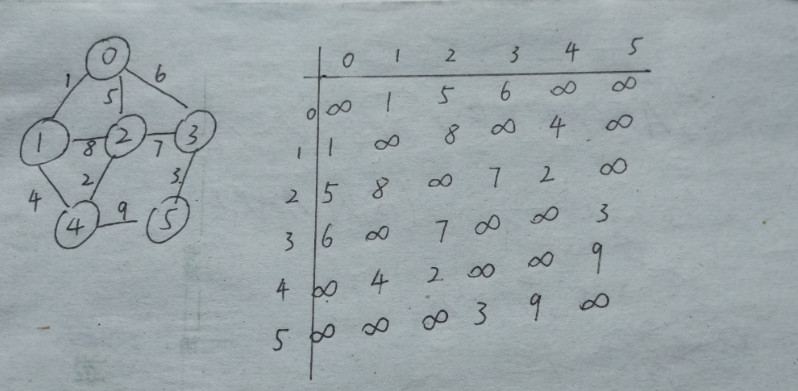
2、vset数组初始化为0,lowcost数组初始化为邻接矩阵第0行的内容。(这里的数组下标与图的顶点编号相对应)
3、vset[0] = 1 ,并且让v = 0,即指向编号为0的顶点
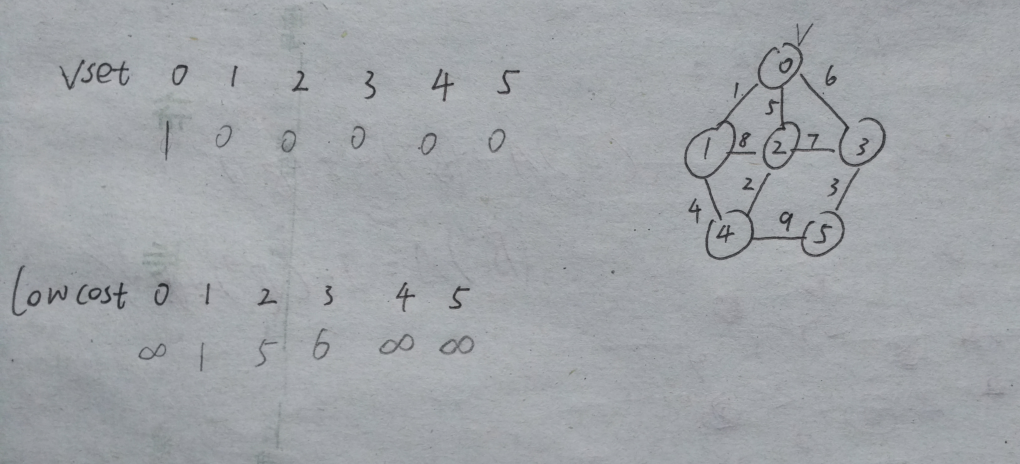
4、由于已经处理了一个顶点了,所以还需要操作n-1次。(n为图的顶点个数)
5、寻找lowcost数组的最小值(寻找的时候,要先看一下当前操作的这个顶点编号,即lowcost的数组下标,在vset数组中是否为0。比如,0,在vset数组中已经为1,所以不访问) 显然为1,用变量k指向它。
6、把v的值变为1,即v = 1;并把vset[1] = 1,把编号为1的顶点加进来,红笔表示最小生成树的边
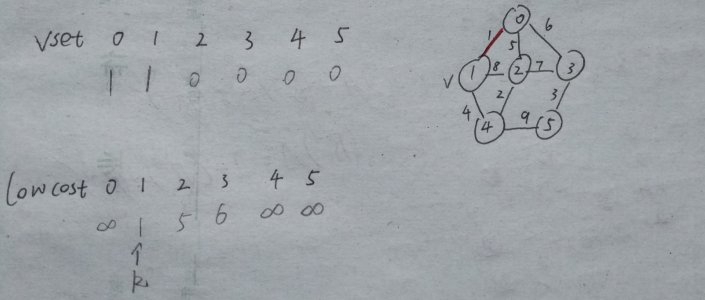
7、扫描邻接矩阵的第v行,这里为1,如果发现有比lowcost当前值小的,即更新。同样要注意【5】中的附加条件。
下图红框中的即为更新后的

8、重复【5】【6】【7】直到vset数组全为1
最后变为
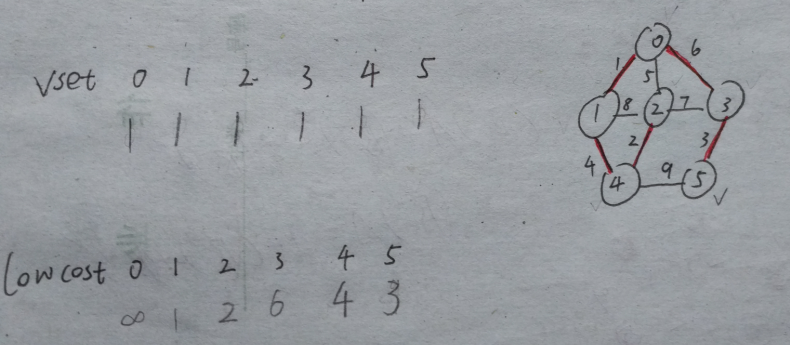
算法结束。
接下来,就是C语言代码了
其中,上面的代码中用p指向最小值所在位置,
Graph g中包含 int table[Max][Max]
//邻接矩阵,Max为先前定义的最大值
int n , e//n为图顶点个数,e为图的边数
这里是图的顶点连续的情况,数组下标即为顶点编号,最大限度利用数据结构
回归正题,今天要介绍的是图的最小生成树,也叫做最小代价。最小生成树是针对无向图而言的。临时百度科普了一下应用,百科上举的一个例子是在各个地区之间铺设光缆,并保证各城市连通。学过数据通信的童鞋应该知道,光纤铺设的成本是相对双绞线啥的要更高。我们可以这样想,各城市可以看成一个一个顶点;架设在城市之间的光缆可以看作是边;这些光缆有的长,有的短,自然每一段的总价就不同了,这个价格,就可以看作是权值。为了省钱,降低成本,是不是要寻找一个路径,攘括了所有的城市,并且费用最少呢?这就是最小生成树了。
我感觉学习算法最重要的是要清楚它是怎么做的,一步一步做,把自己想象成计算机,而不是人类。
下面,我们就来看看最小生成树的Prim算法是怎么做的。
主要思想:以顶点为主线,构成生成树。把图的顶点分成两类,一类是生成树中的点(类A),另一类是图余下的点(类B)。从与类A中的点相邻接的,属于类B的点中,选择权值最小的边,把它加入到生成树中,直到图中所有顶点被加入类A。
我们今天要实现的目标是:计算最小生成树的和
所使用图的存储结构:邻接矩阵
所使用的其他数据结构:int vset
//n为图的顶点个数,用于标识某个点是否被处理。1已被处理;0未被处理
int lowcost
//n为图的顶点个数,用于存储与最小生成树顶点所邻接的边的最小权值
int v //指向候选顶点
好,我们开始,以下都是手画,画的不好还请见谅。
1、图的结构和邻接矩阵
2、vset数组初始化为0,lowcost数组初始化为邻接矩阵第0行的内容。(这里的数组下标与图的顶点编号相对应)
3、vset[0] = 1 ,并且让v = 0,即指向编号为0的顶点
4、由于已经处理了一个顶点了,所以还需要操作n-1次。(n为图的顶点个数)
5、寻找lowcost数组的最小值(寻找的时候,要先看一下当前操作的这个顶点编号,即lowcost的数组下标,在vset数组中是否为0。比如,0,在vset数组中已经为1,所以不访问) 显然为1,用变量k指向它。
6、把v的值变为1,即v = 1;并把vset[1] = 1,把编号为1的顶点加进来,红笔表示最小生成树的边
7、扫描邻接矩阵的第v行,这里为1,如果发现有比lowcost当前值小的,即更新。同样要注意【5】中的附加条件。
下图红框中的即为更新后的
8、重复【5】【6】【7】直到vset数组全为1
最后变为
算法结束。
接下来,就是C语言代码了
int Prim(Graph g)
{
int sum = 0, v;
int vset[Max];
info lowcost[Max];//保存最小生成树的顶点是谁拉进来的
int i;
//init
for(i = 0 ; i < Max ; i++)
{
vset[i] = 0;
}
for(i = 1 ; i <= g->n ; i++)
{
lowcost[i].data = g->table[1][i];
lowcost[i].from = 1;
}
vset[1] = 1;
//main
for(i = 1 ; i <= g->n-1 ; i++)
{
int k , min = Max , p = 0;
//find min weight & position
for(k = 1 ; k <= g->n ; k++)
{
if(lowcost[k].data < min && vset[k] == 0)
{
min = lowcost[k].data;
p = k;
}
}
//add
sum += min;
//update lowcost array
v = p;
for(k = 1 ; k <= g->n ; k++)
{
if(vset[k] == 0 && g->table[v][k] < lowcost[k].data)
{
lowcost[k].data = g->table[v][k];
lowcost[k].from = v;
}
}
vset[v] = 1;
}
return sum;
}其中,上面的代码中用p指向最小值所在位置,
Graph g中包含 int table[Max][Max]
//邻接矩阵,Max为先前定义的最大值
int n , e//n为图顶点个数,e为图的边数
这里是图的顶点连续的情况,数组下标即为顶点编号,最大限度利用数据结构

相关文章推荐
- 最小生成树算法之Prim算法
- 构造最小生成树的算法——Prim算法
- 数据结构与算法16:最小生成树普利姆prim算法
- 最小生成树算法---普里姆Prim算法
- 最小生成树算法(一)--对prim算法的理解
- 算法java实现--贪心算法--最小生成树问题--Prim算法
- 最小生成树算法-Prim算法
- 最小生成树算法(类Prim算法的笨办法)
- 最小生成树算法---普里姆Prim算法
- 最小生成树 Kruskal 算法 和 Prim算法
- 算法——最小生成树:Kruskal算法、Prim算法
- 算法(11)最小生成树(prim算法)
- 【算法导论】最小生成树(prim算法)
- 最小生成树算法(类Prim算法的笨办法)
- [算法与数据结构] - No.9 图论(2)- 最小生成树Prim算法与Kruskal算法
- 【算法导论】最小生成树(prim算法)
- 十二、图的算法入门--(2)最小生成树---Prim算法实现
- 图基本算法 最小生成树 Prim算法(邻接表/邻接矩阵+优先队列STL)
- 普里姆算法(Prim算法求最小生成树)
- POJ 3026 Borg Maze 图论 prim算法(最小生成树)+BFS算法(广度优先搜索)