阿里云-学生考试成绩预测
2017-08-30 10:13
295 查看
(本文数据为实验用例)
母亲是老师反而会对孩子的学习成绩造成不利影响?能上网的家庭,孩子通常能取得较好的成绩?影响孩子成绩的最大因素居然是母亲的学历?本文通过机器挖掘算法和中学真实的学生数据为您揭秘影响中学生学业的关键因素有哪些。
本文的数据采集于某中学在校生的家庭背景数据以及在校行为数据。通过逻辑回归算法生成离线模型和学业指标评估报告,并且可以对学生的期末成绩进行预测。同时,生成在线预测API,可以通过API把训练好的离线模型应用到在线的业务场景中。
数据集由25个特征和一个打标数据构成,
具体字段如下:
数据截图:
首先,实验流程图:
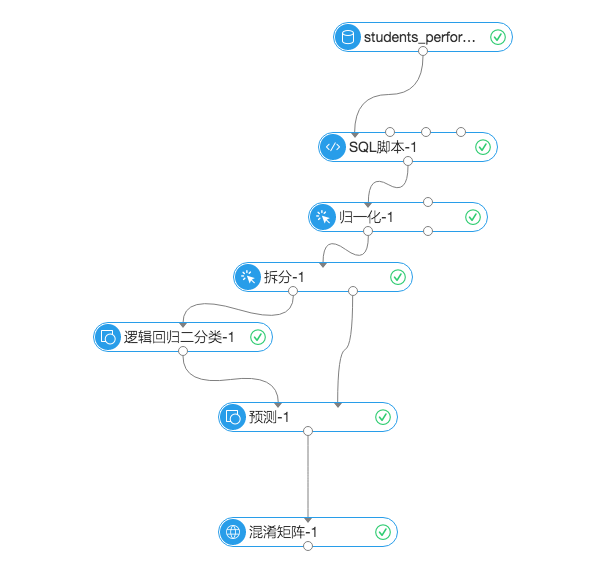
数据自上到下流入,先后经历了数据数据预处理、拆分、训练、预测与评估。
这里SQL脚本主要处理的逻辑是将文本数据结构化。比如说源数据分别有yes和no的情况,我们可以通过0表示yes,1表示no将文本数据量化。一些多种类的文本型字段,比如说Mjob,我们可以结合业务场景来抽象,比如说如果工作是teacher就表示为1,不是teacher表示为0,抽象后这个特征的意义就是表示工作是否与教育相关。对于目标列,我们按照大于18分设为1,其它为0,拟在通过训练,找出可以预测分数的模型。
去量纲,将所有的字段都转换成0~1之间,去除字段间大小不均衡带来的影响。结果图:
将数据集按照8:2拆分,百分之八十用来训练模型,剩下的用来预测。
通过逻辑回归算法训练生成离线模型。具体算法详情可以https://en.wikipedia.org/wiki/Logistic_regression
通过混淆矩阵可以查看模型预测的准确率。
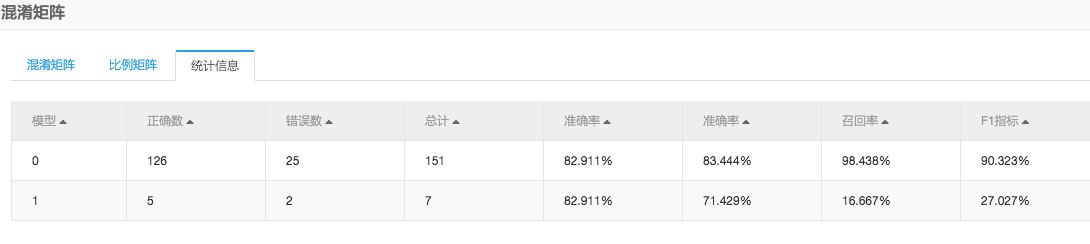
可以看到预测准确率为82.911%。根据逻辑回归算法的特性,我们可以通过模型系数挖掘出一些比较有意思的信息,首先查看模型:
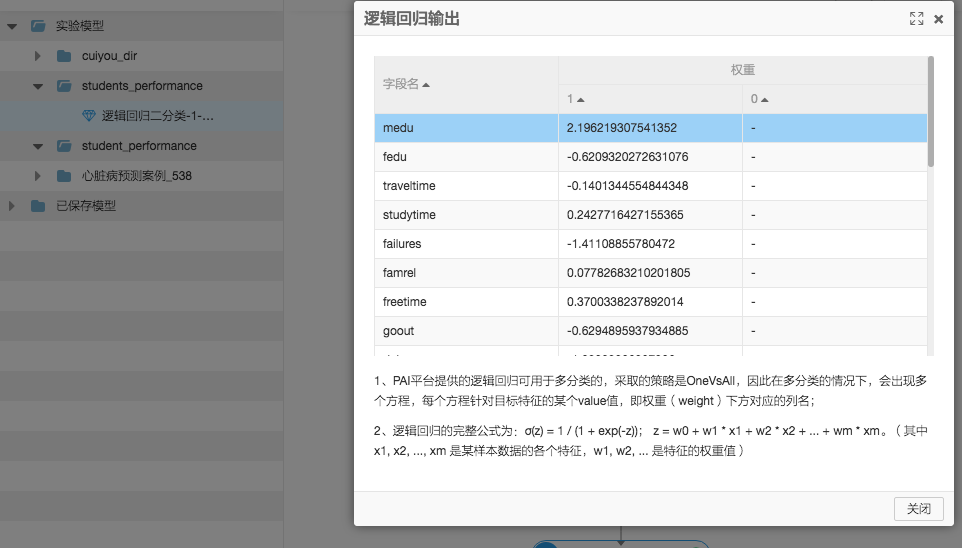
根据逻辑回归算法的算法特性,权重越大表示特征对于结果的影响越大,权重是正数表示对结果1(期末高分)正相关,权重负数表示负相关。于是我们可以挑选几个权重较大的特征进行分析。
以上结论只是从实验的很小的数据集得到的结论,仅供参考。
生成离线模型之后,可以将离线模型部署到线上,通过调用restful-api来进行在线预测。
右键模型-》在线部署模型-》选择cpu、memory-》部署完成
部署成功后显示
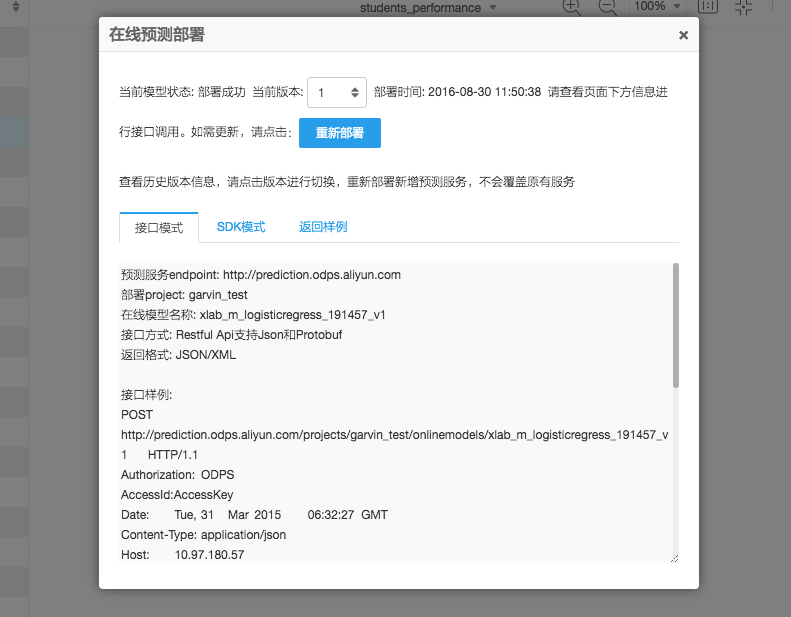
之后在API调试页即可通过填写body信息调用API,并拿到预测结果。
参与讨论:云栖社区公众号
免费体验:阿里云数加机器学习平台
联系我们: aohai.lb@alibaba-inc.com
往期文章:
【玩转数据系列一】人口普查统计案例
【玩转数据系列二】机器学习应用没那么难,这次教你玩心脏病预测
【玩转数据系列三】利用图算法实现金融行业风控
【玩转数据系列四】听说啤酒和尿布很配?本期教你用协同过滤做推荐
【玩转数据系列五】农业贷款发放预测
【玩转数据系列六】文本分析算法实现新闻自动分类
一、背景
母亲是老师反而会对孩子的学习成绩造成不利影响?能上网的家庭,孩子通常能取得较好的成绩?影响孩子成绩的最大因素居然是母亲的学历?本文通过机器挖掘算法和中学真实的学生数据为您揭秘影响中学生学业的关键因素有哪些。本文的数据采集于某中学在校生的家庭背景数据以及在校行为数据。通过逻辑回归算法生成离线模型和学业指标评估报告,并且可以对学生的期末成绩进行预测。同时,生成在线预测API,可以通过API把训练好的离线模型应用到在线的业务场景中。
二、数据集介绍
数据集由25个特征和一个打标数据构成,具体字段如下:
| 字段名 | 含义 | 类型 | 描述 |
|---|---|---|---|
| sex | 性别 | string | F是女,M表示男 |
| address | 住址 | string | U表示城市,R表示乡村 |
| famsize | 家庭成员数 | string | LE3表示少于三人,GT3多于三人 |
| pstatus | 是否与父母住在一起 | string | T住在一起,A分开 |
| medu | 母亲的文化水平 | string | 从0~4逐步增高 |
| fedu | 父亲的文化水平 | string | 从0~4逐步增高 |
| mjob | 母亲的工作 | string | 分为教师相关、健康相关、服务业 |
| fjob | 父亲的工作 | string | 分为教师相关、健康相关、服务业 |
| guardian | 学生的监管人 | string | mother,father or other |
| traveltime | 从家到学校需要的时间 | double | 以分钟为单位 |
| studytime | 每周学习时间 | double | 以小时为单位 |
| failures | 挂科数 | double | 挂科次数 |
| schoolsup | 是否有额外的学习辅助 | string | yes or no |
| fumsup | 是否有家教 | string | yes or no |
| paid | 是否有相关考试学科的辅助 | string | yes or no |
| activities | 是否有课外兴趣班 | string | yes or no |
| higher | 是否有向上求学意愿 | string | yes or no |
| internet | 家里是否联网 | string | yes or no |
| famrel | 家庭关系 | double | 从1~5表示关系从差到好 |
| freetime | 课余时间量 | double | 从1~5从少到多 |
| goout | 跟朋友出去玩的频率 | double | 从1~5从少到多 |
| dalc | 日饮酒量 | double | 从1~5从少到多 |
| walc | 周饮酒量 | double | 从1~5从少到多 |
| health | 健康状况 | double | 从1~5从状态差到好 |
| absences | 出勤量 | double | 0到93次 |
| g3 | 期末成绩 | double | 20分制 |
三、离线训练
首先,实验流程图:数据自上到下流入,先后经历了数据数据预处理、拆分、训练、预测与评估。
1.SQL脚本-数据预处理
select (case sex when 'F' then 1 else 0 end) as sex,
(case address when 'U' then 1 else 0 end) as address,
(case famsize when 'LE3' then 1 else 0 end) as famsize,
(case Pstatus when 'T' then 1 else 0 end) as Pstatus,
Medu,
Fedu,
(case Mjob when 'teacher' then 1 else 0 end) as Mjob,
(case Fjob when 'teacher' then 1 else 0 end) as Fjob,
(case guardian when 'mother' then 0 when 'father' then 1 else 2 end) as guardian,
traveltime,
studytime,
failures,
(case schoolsup when 'yes' then 1 else 0 end) as schoolsup,
(case fumsup when 'yes' then 1 else 0 end) as fumsup,
(case paid when 'yes' then 1 else 0 end) as paid,
(case activities when 'yes' then 1 else 0 end) as activities,
(case higher when 'yes' then 1 else 0 end) as higher,
(case internet when 'yes' then 1 else 0 end) as internet,
famrel,
freetime,
goout,
Dalc,
Walc,
health,
absences,
(case when G3>14 then 1 else 0 end) as finalScore
from ${t1};这里SQL脚本主要处理的逻辑是将文本数据结构化。比如说源数据分别有yes和no的情况,我们可以通过0表示yes,1表示no将文本数据量化。一些多种类的文本型字段,比如说Mjob,我们可以结合业务场景来抽象,比如说如果工作是teacher就表示为1,不是teacher表示为0,抽象后这个特征的意义就是表示工作是否与教育相关。对于目标列,我们按照大于18分设为1,其它为0,拟在通过训练,找出可以预测分数的模型。
2.归一化
去量纲,将所有的字段都转换成0~1之间,去除字段间大小不均衡带来的影响。结果图:
3.拆分
将数据集按照8:2拆分,百分之八十用来训练模型,剩下的用来预测。
4.逻辑回归
通过逻辑回归算法训练生成离线模型。具体算法详情可以https://en.wikipedia.org/wiki/Logistic_regression
5.结果分析和评估
通过混淆矩阵可以查看模型预测的准确率。可以看到预测准确率为82.911%。根据逻辑回归算法的特性,我们可以通过模型系数挖掘出一些比较有意思的信息,首先查看模型:
根据逻辑回归算法的算法特性,权重越大表示特征对于结果的影响越大,权重是正数表示对结果1(期末高分)正相关,权重负数表示负相关。于是我们可以挑选几个权重较大的特征进行分析。
| 字段名 | 含义 | 权重 | 分析 |
|---|---|---|---|
| mjob | 母亲的工作 | -0.7998341777833717 | 母亲是老师对于孩子考高分是不利的 |
| fjob | 父亲工作 | 1.422595764037065 | 如果父亲是老师,对于孩子取得好的成绩是非常有利的 |
| internet | 家里是否联网 | 1.070938672974736 | 家里联网不但不会影响成绩,还会促进孩子的学习 |
| medu | 母亲的文化水平 | 2.196219307541352 | 母亲的文化水平高低对于孩子的影响是最大的,母亲文化越高孩子学习越好。 |
四、在线预测部署
生成离线模型之后,可以将离线模型部署到线上,通过调用restful-api来进行在线预测。
1.部署
右键模型-》在线部署模型-》选择cpu、memory-》部署完成部署成功后显示
之后在API调试页即可通过填写body信息调用API,并拿到预测结果。
四、其它
参与讨论:云栖社区公众号免费体验:阿里云数加机器学习平台
联系我们: aohai.lb@alibaba-inc.com
往期文章:
【玩转数据系列一】人口普查统计案例
【玩转数据系列二】机器学习应用没那么难,这次教你玩心脏病预测
【玩转数据系列三】利用图算法实现金融行业风控
【玩转数据系列四】听说啤酒和尿布很配?本期教你用协同过滤做推荐
【玩转数据系列五】农业贷款发放预测
【玩转数据系列六】文本分析算法实现新闻自动分类

相关文章推荐
- 阿里云-学生考试成绩预测
- [双语阅读]研究:学生沉迷社交网站 考试成绩差
- R语言学习笔记:分析学生的考试成绩
- 脚本-if 根据学生考试成绩判断学生的优劣成绩
- 已知某学生三科考试成绩,试求此学生考试成绩总和及平均分,要求平均分保留2位小数。
- 设计程序,用一个二维数组存放5个学生的4门功课的考试成绩,求每个学生的平均成绩。
- 【OC复合题】之定义一个学生类,需要有姓名,年龄,考试成绩三个成员属性,创建5个对象,属性可以任意值。(Objective-C)
- 20151017数组计算学生考试成绩
- >如果有年纪为S2的学生,就查询参加S2学科考试的学员学号,科目编号,考试成绩,考试时间
- /*3.使用二维数组存储班上五个学生三门功课的考试成绩,要求输出每一个学生的总分、平均分、最高分、最低分。
- 2.请把学生名与考试分数录入到Map中,并按分数显示前三名成绩学员的名字。
- 对学生考试成绩的处理
- 给出n个学生的考试成绩表,每条记录由学号、姓名和分数和名次组成,设计算法完成下列操作: (1)设计一个显示对学生信息操作的菜单函数如下所示: *************************
- 【机器学习PAI实践八】用机器学习算法评估学生考试成绩
- 请把学生名与考试分数录入到Map中,并按分数显示前三名成绩学员的名字
- 在一个长度为10的整型数组里面,保存了班级10个学生的考试成绩。要求编写5个函数,分别实现计算考试的总分,最高分,最低分,平均分和考试成绩降序排序
- js实现往表格动态添加学生的学号、姓名、语数英的考试成绩和总分(总分不是填写),实现行与行之的颜色相间,高光的效果
- 根据成绩用Logistic Regression预测学生是否被高校录取--Python版
- vb.net ---- 学生考试成绩统计生成系统.txt
- 6.对学生成绩进行统计计算,参加考试的有6名学生,考试成绩分别为94.5,89.0,79.5,64.5,81.5,73.5,显示考试的总分和平均分,之后显示大于考试平均分的成绩信息。请写出实现上述功能