中国大学排名爬虫
2017-08-29 21:21
465 查看

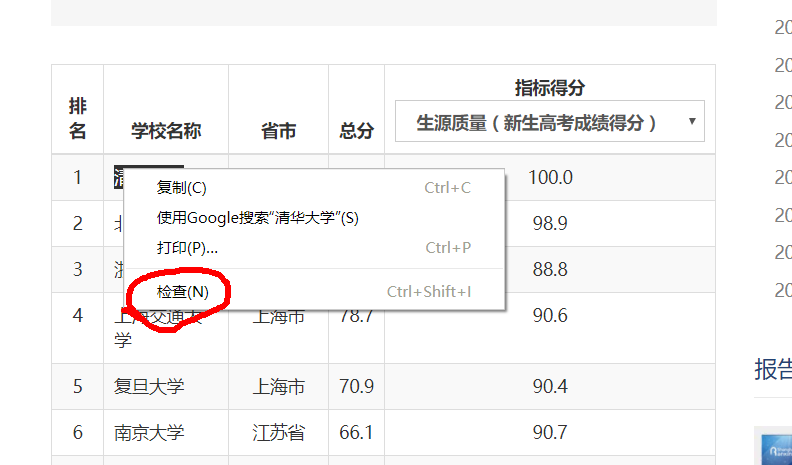
首先,进入中国大学排名网站 点我
按F12,选中了 清华大学 四个字,右键点击 检查
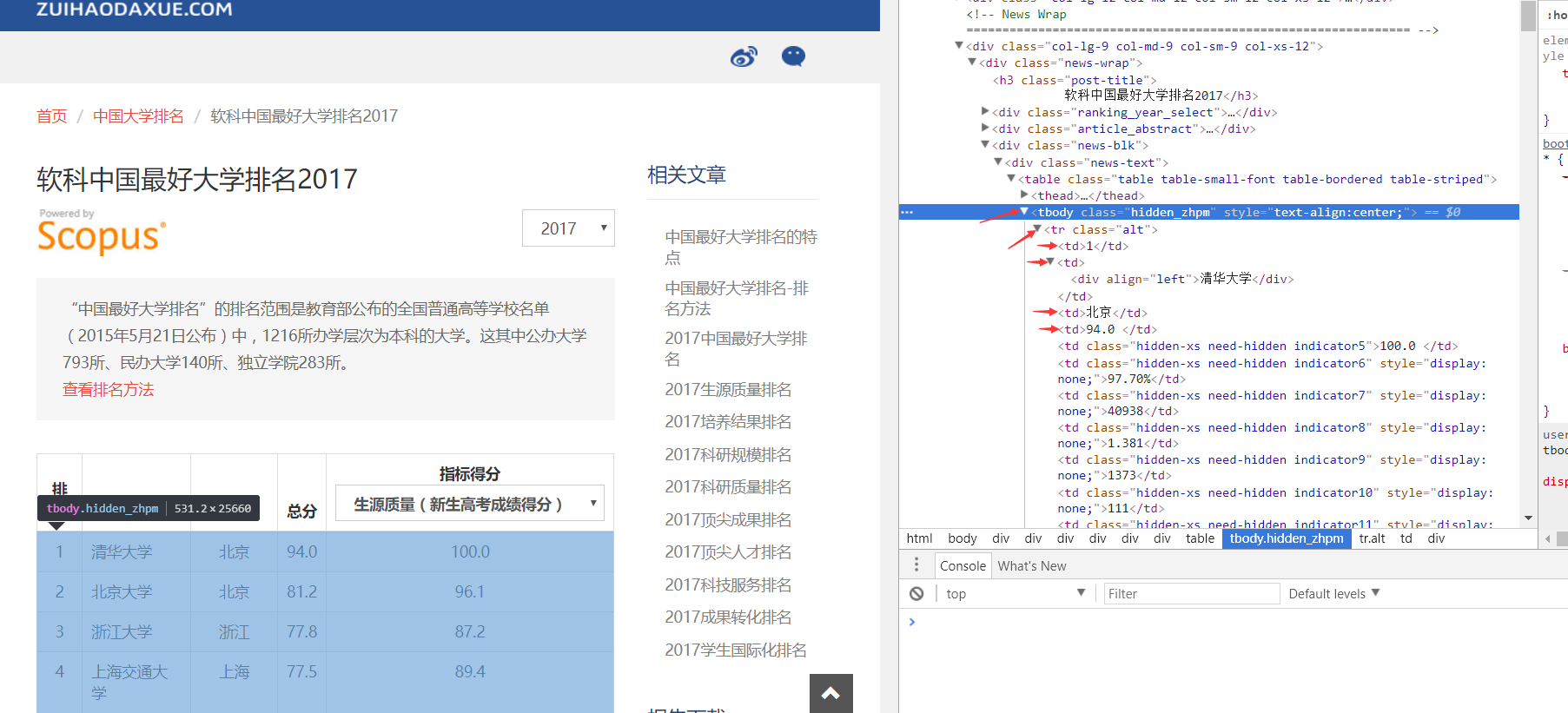
我们想要的信息在 tbody标签,children tr标签,chilren chilren td 标签下
因此可以用循环遍历tr,用列表储存tr标签下的信息
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])注意,得分在tds**列表**的第3个。isinstance函数是判断tr标签是不是符合 bs4.element.Tag(排除其他没用的信息)
主要的函数写出来,其他问题不大。
提取html的函数(套路)
def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return ""
讲所需要的信息放在一个列表的函数(核心)
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children: if isinstance(tr, bs4.element.Tag): tds = tr('td') ulist.append([tds[0].string, tds[1].string, tds[3].string])
接下来是把列表里的信息打印出来
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))最后写个主函数
def main(): uinfo = [] url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html' html = getHTMLText(url) fillUnivList(uinfo, html) printUnivList(uinfo, 20) # 20 univs
ps:将2016改成2017发现报错。。。。。迷
完整代码:
#CrawUnivRankingA.py
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children: if isinstance(tr, bs4.element.Tag): tds = tr('td') ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num): print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分")) for i in range(num): u=ulist[i] print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main(): uinfo = [] url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html' html = getHTMLText(url) fillUnivList(uinfo, html) printUnivList(uinfo, 20) # 20 univs
main()
运行结果为:
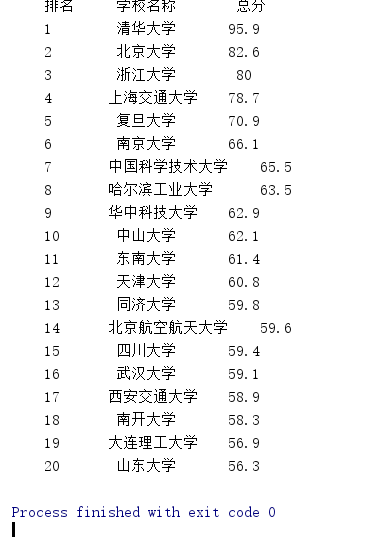
发现不对齐,强迫症不能忍啊。。。。
下面是中文对齐问题
出现这种原因是:中文字符宽度不够用时,用西文字符填充;中西文字占用宽度不同
另开个贴来记录
修改后的代码:
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children: if isinstance(tr, bs4.element.Tag): tds = tr('td') ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main(): uinfo = [] url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html' html = getHTMLText(url) fillUnivList(uinfo, html) printUnivList(uinfo, 20) # 20 univs
main()
运行结果:

总结:
1.熟记套路
2.对于排版format还是不是很懂,继续加油ヾ(◍°∇°◍)ノ゙

相关文章推荐
- python爬虫由浅入深7--基于中国大学排名的定向爬虫
- Python网络爬虫与信息提取-Day10-(实例)中国大学排名定向爬虫
- python爬虫定向爬取中国大学排名
- python爬虫学习 之 定向爬取 中国大学排名
- requests‐bs4路线实现中国大学排名定向爬虫
- 中国大学排名爬虫
- 爬虫实例(二)——中国大学排名爬虫
- 第一个简单的python爬虫:爬取ATP男子网球世界排名
- 2012年中国大学最新排名
- 使用Python爬取中国大学排名,并格式化对其输出内容
- 中国大学排名定向爬取实例
- 中国大学就业排名后的思考
- 用py来爬取中国大学排名
- 爬虫获取CSDN用户的排名
- 爬虫实例(中国大学排名前10)
- 爬虫实战(1)最好大学网大学排名
- python 爬虫 大众点评美食排名
- Python爬虫实战:2017中国最好大学排名
- 用python爬虫爬取饿了么外卖店铺排名
- 定向爬虫实例之中国大学排名定向爬虫