场景分类方法汇总
2017-08-27 15:21
555 查看
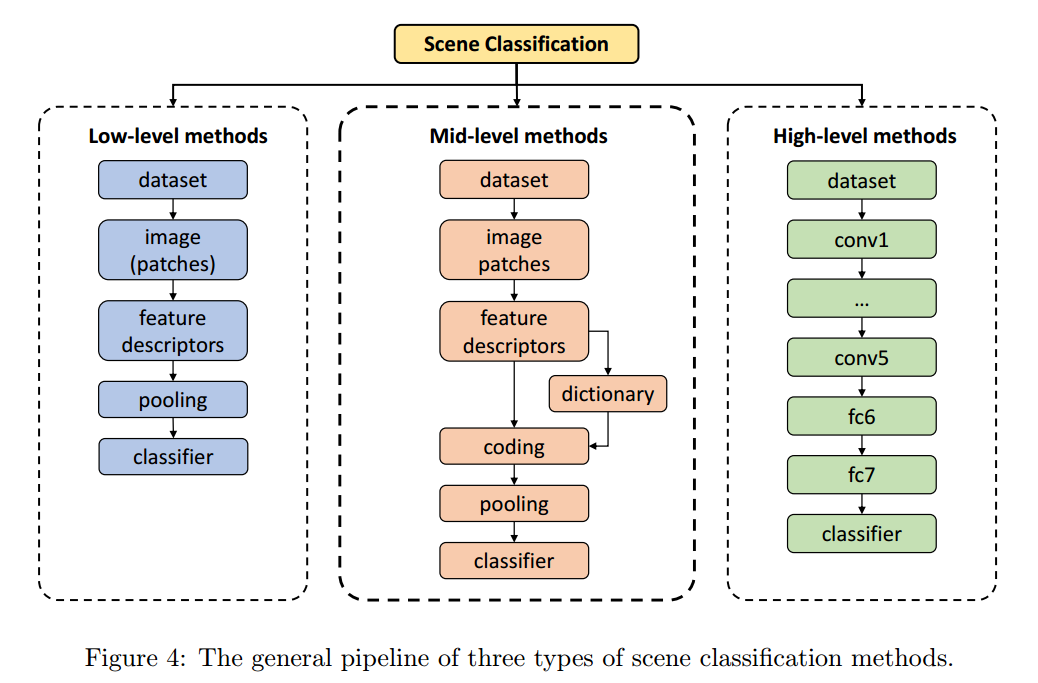
Low-level :
- SIFT : It describes a patch by the histograms of gradients computed over a 4 × 4 spatial
grid. The
gradients are then quantized into eight bins so the final feature vector has a dimension of 128 (4×4×8).
- LBP : Some works adopt LBP to extract texture information from aerial images, see [54,58]. For a
patch, it first compares the pixel to its 8 neighbors: when the neighbor’s value is less than the center
pixel’s, output \1", otherwise, output \0". This gives an 8-bit decimal number to describe the center
pixel. The LBP descriptor is obtained by computing the histogram of the decimal numbers over the
patch and results in a feature vector with 256 dimensions.
- Color histogram : Color histograms (CH) are used for extracting the spectral information of aerial
scenes . In our experiments, color histogram descriptors are computed separately in three
channels of the RGB color space. Each channel is quantized into 32 bins to form a total histogram
feature length of 96 by simply concatenation of the three channels.
- GIST : Unlike aforementioned descriptors that focus on local information, GIST represents the dominant spatial structure of a scene by a set of perceptual dimensions (naturalness, openness, roughness,
expansion, ruggedness) based on the spatial envelope model [61] and thus widely used for describing
scenes . This descriptor is implemented by convolving the gray image with multi-scale (with the
number of S) and multi-direction (with the number of D) Gabor filters on a 4 × 4 spatial grid. By
concatenating the mean vector of each grid, we get the GIST descriptor of an image with 16 × S × D
dimensions.
Mid-Level:
- Bag
of Visual Words (BoVW) model an image by leaving out the spatial information and representing it with the frequencies of local visual words [57].
BoVW model and its variants are widely used
in scene classification .
The visual words are often produced by clustering
local image descriptors to form a dictionary (with a given size K), e.g. using k-means algorithm.
- Spatial Pyramid Matching (SPM) uses a sequence of increasingly coarser grids to build a spatial
pyramid (with L levels) coding of local image descriptors. By concatenating the weighted local image
features in each subregion at different scales, one can get a (4L-31)×K dimension
global feature vector
which is much longer than BoVW with the same size of dictionary (K).
- Locality-constrained Linear Coding (LLC) is an effective coding scheme adapted from sparse coding
methods . It utilizes the locality constraints to code each local descriptor into its localcoordinate system
by modifying the sparsity constraints [70,86]. The final feature can be generated by
max pooling of the projected coordinates with the same size of dictionary.
- Probabilistic Latent Semantic Analysis (pLSA) is a way to improve the BoVW model by topic models. A latent variable called topic is introduced and defined
as the conditional probability distribution
of visual words in the dictionary. It can serve as a connection between the visual words and images.
By describing an image with the distribution of topics (the number of topics is set to be T ), one can
solve the influence of synonym and polysemy meanwhile reduce the feature dimension to be T .
- Latent Dirichlet allocation (LDA) is a generative topic model evolved from pLSA with the main
difference that it adds a Dirichlet prior to describe the latent variable topic instead of the fixed Gaussian
distribution, and is also widely used for scene classification .
As a result, it can handel
the problem of overfitting and also increase the robustness. The dimension of final feature vector is the
same with the number of topics T .
- Improved Fisher kernel (IFK) uses Gaussian Mixture Model (GMM) to encode local image features and achieves
good performance in scene classification. In essence, the feature of an
image got by Fisher vector encoding method is a gradient vector of the log-likelihood. By computing
and concatenating the partial derivatives of the mean and variance of the Gaussian functions, the final
feature vector is obtained with the dimension of 2 × K × F (where F indicates the
dimension of the
local feature descriptors and K denotes the size of the dictionary).
- Vector of Locally Aggregated Descriptors (VLAD) can be seen as a simplification of the IFK
method which aggregates descriptors based on a locality criterion in feature space. It uses the
non-probabilistic k-means clustering to generate the dictionary by taking the place of GMM model
in IFK. When coding each local patch descriptor to its nearest neighbor in the dictionary, the differences between them in each dimension are accumulated and resulting in an image feature vector with
dimension of K × F .
High-Level:
- CaffeNet:
Caffe (Convolutional Architecture for Fast Feature Embedding) is one of the most
commonly used open-source frameworks for deep learning (deep convolutional neural networks in particular). The reference model - CaffeNet, which is almost a replication of ALexNet [88] that
is proposed
12
for the ILSVRC 2012 competition . The main differences are: (1) there is no data argumentation
during training; (2) the order of normalization and pooling are switched. Therefore, it has quite similar
performances to the AlexNet, see [4, 41]. For this reason, we only test CaffeNet in our experiment.
The architecture of CaffeNet comprises 5 convolutional layers, each followed by a pooling layer, and 3
fully connected layers at the end. In our work, we directly use the pre-trained model obtained using
the ILSVRC 2012 dataset [78], and extract the activations from the first fully-connected layer, which
results in a vector of 4096 dimensions for an image.
- VGG-VD-16: To investigate the effect of the convolutional network depth on its accuracy in the largescale image recognition setting, [89] gives a thorough evaluation of networks by increasing
depth using
an architecture with very small (3 × 3) convolution filters, which shows a significant improvement on
the accuracies, and can be generalised well to a wide range of tasks and datasets. In our work, we use
one of its best-performing models, named VGG-VD-16, because of its simpler architecture and slightly
better results. It is composed of 13 convolutional layers and followed by 3 fully connected layers, thus
results in 16 layers. Similarly, we extract the activations from the first fully connected layer as the
feature vectors of the images.
- GoogLeNet: This model [81] won the ILSVRC-2014 competition [78]. Its main novelty lies in the
design of the "Inception modules", which is based on the idea of "network in network" [90]. By using
the Inception modules, GoogLeNet has two main advantages: (1) the utilization of filters of different
sizes at the same layer can maintain multi-scale spatial information; (2) the reduction of the number
of parameters of the network makes it less prone to overfitting and allows it to be deeper and wider.
Specifically, GoogLeNet is a 22-layer architecture with more than 50 convolutional layers distributed
inside the inception modules. Different from the above CNN models, GoogLeNet has only one fully
connected layer at last, therefore, we extract the features of the fully connected layer for testing

相关文章推荐
- 场景分类方法概述
- 【Excel技巧】分类汇总数据单独复制的简便方法
- 【读书笔记】软件工程·实践者的研究方法第7版 第二部分 建模 第6章 需求建模:场景、信息与类分类
- 实现PHP+Mysql无限分类的方法汇总
- 数据SQl分类汇总方法
- 各分类方法应用场景 逻辑回归,支持向量机,随机森林,GBT,深度学习
- <模型汇总_9> 深度学习网络的表达方式汇总及模型分类方法
- 各分类方法应用场景 逻辑回归,支持向量机,随机森林,GBT,深度学习
- 实现PHP+Mysql无限分类的方法汇总
- jlink烧写Nor Flash时出错正确解决方法汇总:PC of target system has unexpected value after programming 分类: HI3531 arm-linux-Ubuntu 2013-12-07 14:54 551人阅读 评论(0) 收藏
- 方法应用场景汇总
- PL/SQL:集合类型 (定义,分类,使用场景,集合方法)
- 对重复数据中的值进行分类汇总的 5 种方法
- Excel操作:如何锁定单元格、有几种方法实现分类汇总
- PHP+Mysql无限分类的方法汇总
- 图像处理------常见二值化方法汇总 分类: 视频图像处理 2015-07-24 14:51 33人阅读 评论(0) 收藏
- [置顶] opencv图像分类方法汇总
- 实现PHP+Mysql无限分类的方法汇总
- 【Excel技巧】分类汇总数据单独复制的简便方法
- SQL Sever和Oracle取分类前N条记录方法汇总