RabbitMQ+HAProxy构建高可用消息队列
2017-08-27 12:39
766 查看
用RabbitMQ的集群、镜像队列+HAProxy构建一个高可用的消息队列。
现在有三台ubuntu服务器,ip分别是 192.168.56.111,192.168.56.112,192.168.56.113
如果没有这么多主机,本项目用到四个主机,可参考:http://blog.csdn.net/qq_34039315/article/details/77527082
服务器端安装配置rabbitmq,可参考:http://blog.csdn.net/qq_34039315/article/details/77587623
设置ubuntu02、ubuntu03的cookie为这个值,需要临时修改权限才能添加进去
可以看到成功修改了节点属性
ubuntu01执行:
erlang是通过主机名来连接服务,必须保证各个主机名之间可以ping通。可以通过编辑/etc/hosts来手工添加主机名和IP对应关系。如果主机名ping不通,rabbitmq服务启动会失败。
如果queue是非持久化queue,则如果创建queue的那个节点失败,发送方和接收方可以创建同样的queue继续运作。但如果是持久化queue,则只能等创建queue的那个节点恢复后才能继续服务。
在集群元数据有变动的时候需要有disk node在线,但是在节点加入或退出的时候所有的disk node必须全部在线。如果没有正确退出disk node,集群会认为这个节点当掉了,在这个节点恢复之前不要加入其它节点。
RabbitMQ只要求集群中至少有一个磁盘节点,其他节点都可以是内存节点。当节点加入或者离开集群时,它们必须要将变更通知到至少一个磁盘节点。如果只有一个磁盘节点,磁盘节点奔溃后,集群可以继续路由消息(即保持运行),但是直到该节点恢复之前,无法更改任何东西。通常在集群中设置两个磁盘节点。
在集群中的任意一台主机上执行:
这行命令在vhost名称为/test创建了一个策略,策略名称为ha-allqueue,策略模式为 all 即复制到所有节点,包含新增节点,策略正则表达式为 “^” 表示所有匹配所有队列名称。
配置镜像队列后,其中1台节点失败,队列内容是不会丢失,如果整个集群重启,会恢复在disc中的持久化消息。
当然我们推荐第三种方式了:
在一台新的主机上:192.168.56.114
修改为如下:
然后看到相关信息即为成功
2、打开:http://192.168.56.114:8004 同样也可以看到rabbitmq的web控制台,因为配置文件也绑定了这个
3、发送rabbitmq消息:
此时,向192.168.56.114:5672即可成功,我用的rabbitmq+spring测试:
具体可参考:http://blog.csdn.net/qq_34039315/article/details/77484292

上图中是三个节点的RabbitMQ集群,Exchange A的metadata信息在所有节点上是一致的,queue的完整信息则只在它创建的那个节点上。每个RabbitMQ节点通常以“rabbit@”表示,所以hostname在运行RabbitMQ的节点中很重要。注意:如果更改了hostname,需要重置RabbitMQ内部的数据库,否则服务无法工作。
通常我们将这些信息保存到磁盘上,也就是查询RabbitMQ状态时的“disc”方式,以便集群重启时可以根据保存的metadata信息重建exchange等。
对于exchange来讲,它的所有信息就是一个exchange名字加上一个查询表。查询表中记录了所有的queue binding。当message被发送到exchange时,client连接的channel对routing key进行比对,根据binding进行正确的转发。
对于Queue来讲,虽然它的metadata在每个节点上都有,但只有在它被创建的那个RabbitMQ 节点上才具有完整的信息:比如state/contents等,这个node被称为此queue的owner node。其他节点只知道这个queue的metadata信息和一个指向queue的owner node的指针。
如果一个client访问RabbitMQ的节点上没有需要的queue的完整信息,RabbitMQ将根据这个指针将请求转发到owner node。所以一个客户端最好一直只和一个节点连接,这样效率高一点。
Mnesia是RabbitMQ中的数据库,它是内嵌在Erlang中的no-SQL数据库。Exchange/Queue/Binding等的metadata信息都保存在mnesia的数据库文件中。关于RabbitMQ的集群信息也保存在这里。Rabbitmqctl的reset操作实际上就是清空了mnesia数据库所在目录的内容。
集群配置
主要参考官网:http://www.rabbitmq.com/clustering.html现在有三台ubuntu服务器,ip分别是 192.168.56.111,192.168.56.112,192.168.56.113
如果没有这么多主机,本项目用到四个主机,可参考:http://blog.csdn.net/qq_34039315/article/details/77527082
服务器端安装配置rabbitmq,可参考:http://blog.csdn.net/qq_34039315/article/details/77587623
1、三台机器都需要在/etc/hosts里面输入相关的IP和机器名对应关系
192.168.56.111 ubuntu01 192.168.56.112 ubuntu02 192.168.56.113 ubuntu03
2、设置同一cookie
查看mq1的cookie$ sudo cat /var/lib/rabbitmq/.erlang.cookie #RFHZQHILNIHDGGKQYYNG
设置ubuntu02、ubuntu03的cookie为这个值,需要临时修改权限才能添加进去
$ sudo rabbitmqctl stop $ sudo chmod 777 /var/lib/rabbitmq/.erlang.cookie $ sudo echo 'RFHZQHILNIHDGGKQYYNG' > /var/lib/rabbitmq/.erlang.cookie $ sudo chmod 400 /var/lib/rabbitmq/.erlang.cookie # 后台启动服务 $ sudo rabbitmq-server –detached&
3、ubuntu02、ubuntu03加入集群
$ sudo rabbitmqctl stop_app $ sudo rabbitmqctl join_cluster rabbit@ubuntu01 $ sudo rabbitmqctl start_app
4、查看状态
可以看到3个节点都是采用disc模式的$ sudo rabbitmqctl cluster_status
Cluster status of node rabbit@ubuntu03
[{nodes,[{disc,[rabbit@ubuntu01,rabbit@ubuntu02,rabbit@ubuntu03]}]},
{running_nodes,[rabbit@ubuntu01,rabbit@ubuntu02,rabbit@ubuntu03]},
{cluster_name,<<"rabbit@ubuntu02">>},
{partitions,[]},
{alarms,[{rabbit@ubuntu01,[]},{rabbit@ubuntu02,[]},{rabbit@ubuntu03,[]}]}]5、修改ubuntu02节点为ram模式
$ sudo rabbitmqctl stop_app
$ sudo rabbitmqctl change_cluster_node_type ram
$ sudo rabbitmqctl start_app
$ sudo rabbitmqctl cluster_status
Cluster status of node rabbit@ubuntu02
[{nodes,[{disc,[rabbit@ubuntu03,rabbit@ubuntu01]},{ram,[rabbit@ubuntu02]}]},
{running_nodes,[rabbit@ubuntu01,rabbit@ubuntu03,rabbit@ubuntu02]},
{cluster_name,<<"rabbit@ubuntu02">>},
{partitions,[]},
{alarms,[{rabbit@ubuntu01,[]},{rabbit@ubuntu03,[]},{rabbit@ubuntu02,[]}]}]可以看到成功修改了节点属性
6、ubuntu03退出集群(仅作尝试)
ubuntu03执行:$ sudo rabbitmqctl stop_app $ sudo rabbitmqctl reset $ sudo rabbitmqctl start_app
ubuntu01执行:
$ sudo rabbitmqctl forget_cluster_node rabbit@ubuntu03
注意事项
cookie在所有节点上必须完全一样,同步时一定要注意。、erlang是通过主机名来连接服务,必须保证各个主机名之间可以ping通。可以通过编辑/etc/hosts来手工添加主机名和IP对应关系。如果主机名ping不通,rabbitmq服务启动会失败。
如果queue是非持久化queue,则如果创建queue的那个节点失败,发送方和接收方可以创建同样的queue继续运作。但如果是持久化queue,则只能等创建queue的那个节点恢复后才能继续服务。
在集群元数据有变动的时候需要有disk node在线,但是在节点加入或退出的时候所有的disk node必须全部在线。如果没有正确退出disk node,集群会认为这个节点当掉了,在这个节点恢复之前不要加入其它节点。
RabbitMQ只要求集群中至少有一个磁盘节点,其他节点都可以是内存节点。当节点加入或者离开集群时,它们必须要将变更通知到至少一个磁盘节点。如果只有一个磁盘节点,磁盘节点奔溃后,集群可以继续路由消息(即保持运行),但是直到该节点恢复之前,无法更改任何东西。通常在集群中设置两个磁盘节点。
RabbitMQ镜像配置
在上述的集群中,如果某个节点挂掉,整个集群还是可以正常工作的,但是挂掉的那个节点的消息就清空了。这种情况在生产环境中是不可接受的,所以需要用到镜像功能,也就是主从配置。在集群中的任意一台主机上执行:
$ sudo rabbitmqctl set_policy -p /test ha-allqueue "^" '{"ha-mode":"all"}'这行命令在vhost名称为/test创建了一个策略,策略名称为ha-allqueue,策略模式为 all 即复制到所有节点,包含新增节点,策略正则表达式为 “^” 表示所有匹配所有队列名称。
配置镜像队列后,其中1台节点失败,队列内容是不会丢失,如果整个集群重启,会恢复在disc中的持久化消息。
HAProxy负载均衡
上述操作已经建立起一个高可用的消息队列了,那么客户端怎么连接呢?1、客户端可以连接集群中的任意一个节点,如果一个节点故障,客户端自行重新连接到其他的可用节点;(不推荐,对客户端不透明) 2、通过动态DNS,较短的ttl 3、HAProxy负载均衡
当然我们推荐第三种方式了:
在一台新的主机上:192.168.56.114
1、安装HAProxy(本次安装了1.6.3版本):
$ sudo apt-get update $ sudo apt-get install haproxy $ haproxy -v #查看版本
2、修改配置文件
配置文件路径:/etc/haproxy/haproxy.cfg修改为如下:
##############全局配置######################## global log 127.0.0.1 local0 log 127.0.0.1 local1 notice chroot /var/lib/haproxy #改变当前工作目录 stats socket /run/haproxy/admin.sock mode 660 level admin #创建监控所用的套接字目录 stats timeout 30s #超时时间 user haproxy #默认用户 group haproxy #默认用户组 daemon #创建一个守护进程 # Default SSL material locations ca-base /etc/ssl/certs crt-base /etc/ssl/private # Default ciphers to use on SSL-enabled listening sockets. # For more information, see ciphers(1SSL). This list is from: # https://hynek.me/articles/hardening-your-web-servers-ssl-ciphers/ ssl-default-bind-ciphers ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:ECDH+3DES:DH+3DES:RSA+AESGCM:RSA+AES:RSA+3DES:!aNULL:!MD5:!DSS ssl-default-bind-options no-sslv3 #################默认配置##################### defaults log global mode http #默认的模式 tcp|http|health 可选,tcp是4层,http是7层,health至返回OK option httplog #http日志模式 option dontlognull # 启用该项,日志中将不会记录空连接。所谓空连接就是在上游的负载均衡器 # 或者监控系统为了探测该 服务是否存活可用时,需要定期的连接或者获取某 # 一固定的组件或页面,或者探测扫描端口是否在监听或开放等动作被称为空连接; # 官方文档中标注,如果该服务上游没有其他的负载均衡器的话,建议不要使用 # 该参数,因为互联网上的恶意扫描或其他动作就不会被记录下来 timeout connect 5000 #连接超时时间 timeout client 50000 #客户端连接超时时间 timeout server 50000 #服务端连接超时时间 errorfile 400 /etc/haproxy/errors/400.http errorfile 403 /etc/haproxy/errors/403.http errorfile 408 /etc/haproxy/errors/408.http errorfile 500 /etc/haproxy/errors/500.http errorfile 502 /etc/haproxy/errors/502.http errorfile 503 /etc/haproxy/errors/503.http errorfile 504 /etc/haproxy/errors/504.http #################################################################### listen http_front bind 0.0.0.0:1080 #监听端口 mode http stats refresh 30s #统计页面自动刷新时间 stats uri /haproxy?stats #统计页面url stats realm Haproxy Manager #统计页面密码框上提示文本 stats auth admin:admin #统计页面用户名和密码设置 #stats hide-version #隐藏统计页面上HAProxy的版本信息 ###############我把RabbitMQ的管理界面也放在HAProxy后面了################# listen rabbitmq_admin bind 0.0.0.0:8004 server node1 192.168.56.111:15672 server node2 192.168.56.112:15672 server node3 192.168.56.113:15672 #################################################################### listen rabbitmq_cluster bind 0.0.0.0:5672 option tcplog mode tcp timeout client 3h timeout server 3h option clitcpka balance roundrobin #负载均衡算法(#banlance roundrobin 轮询,balance source 保存session值,支持static-rr,leastconn,first,uri等参数) #balance url_param userid #balance url_param session_id check_post 64 #balance hdr(User-Agent) #balance hdr(host) #balance hdr(Host) use_domain_only #balance rdp-cookie #balance leastconn #balance source //ip server node1 192.168.56.111:5672 check inter 5s rise 2 fall 3 #check inter 2000 是检测心跳频率,rise 2是2次正确认为服务器可用,fall 3是3次失败认为服务器不可用 server node2 192.168.56.112:5672 check inter 5s rise 2 fall 3 server node3 192.168.56.113:5672 check inter 5s rise 2 fall 3
3、重新启动HAProxy
$ sudo service haproxy restart
4、验证
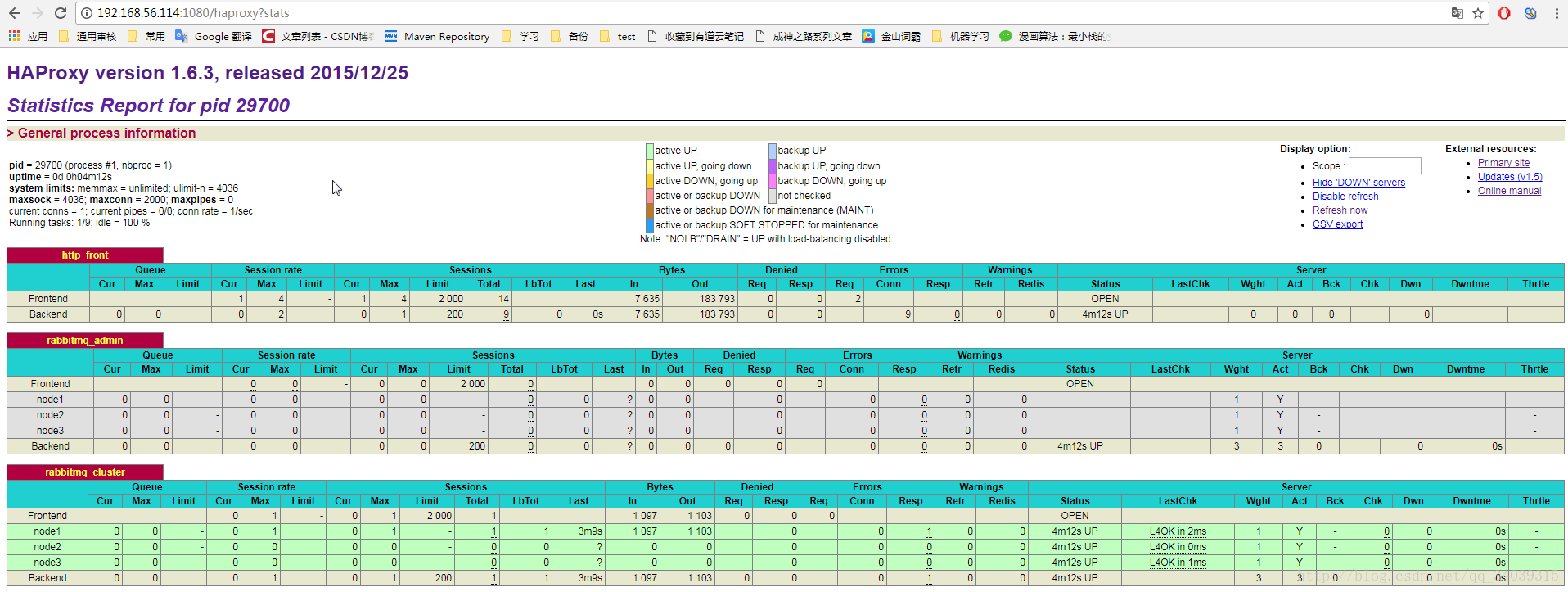
1、打开url:http://192.168.56.114:1080/haproxy?stats 帐号密码:admin/admin然后看到相关信息即为成功
2、打开:http://192.168.56.114:8004 同样也可以看到rabbitmq的web控制台,因为配置文件也绑定了这个
3、发送rabbitmq消息:
此时,向192.168.56.114:5672即可成功,我用的rabbitmq+spring测试:
具体可参考:http://blog.csdn.net/qq_34039315/article/details/77484292
集群知识
如何选择RabbitMQ的消息保存方式?
RabbitMQ对于queue中的message的保存方式有两种方式:disc和ram。如果采用disc,则需要对exchange/queue/delivery mode都要设置成durable模式。Disc方式的好处是当RabbitMQ失效了,message仍然可以在重启之后恢复。而使用ram方式,RabbitMQ处理message的效率要高很多,ram和disc两种方式的效率比大概是3:1。所以如果在有其它HA手段保障的情况下,选用ram方式是可以提高消息队列的工作效率的。当消息发送的速率超过了RabbitMQ的处理能力时该怎么办?
RabbitMQ会自动减慢这个连接的速率,让client端以为网络带宽变小了,发送消息的速率会受限,从而达到流控的目的。 使用”rabbitmqctl list_connections”查看连接,如果状态为“flow”,则说明这个连接处于flow-control 状态。RabbitMQ集群结构
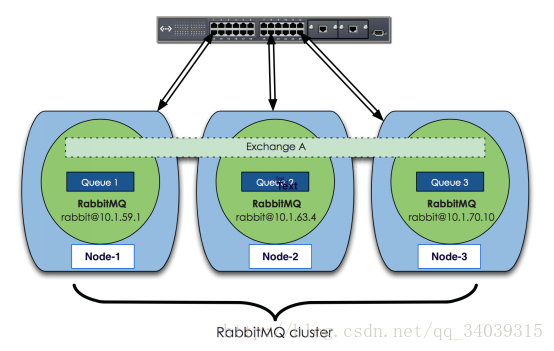
RabbitMQ基于Erlang编写,天然支持clustering。集群是保证可靠性的一种方式,同时可以通过水平扩展以达到增加消息吞吐能力的目的.上图中是三个节点的RabbitMQ集群,Exchange A的metadata信息在所有节点上是一致的,queue的完整信息则只在它创建的那个节点上。每个RabbitMQ节点通常以“rabbit@”表示,所以hostname在运行RabbitMQ的节点中很重要。注意:如果更改了hostname,需要重置RabbitMQ内部的数据库,否则服务无法工作。
数据流动
RabbitMQ维护着四种类型的metadata: queue/exchange/binding/vhost,在集群中这些信息被同步到每个节点,因此当用户访问任何一个节点时,通过rabbitmqctl查询到的queue/user/exchange等信息都是相同的。通常我们将这些信息保存到磁盘上,也就是查询RabbitMQ状态时的“disc”方式,以便集群重启时可以根据保存的metadata信息重建exchange等。
对于exchange来讲,它的所有信息就是一个exchange名字加上一个查询表。查询表中记录了所有的queue binding。当message被发送到exchange时,client连接的channel对routing key进行比对,根据binding进行正确的转发。
对于Queue来讲,虽然它的metadata在每个节点上都有,但只有在它被创建的那个RabbitMQ 节点上才具有完整的信息:比如state/contents等,这个node被称为此queue的owner node。其他节点只知道这个queue的metadata信息和一个指向queue的owner node的指针。
如果一个client访问RabbitMQ的节点上没有需要的queue的完整信息,RabbitMQ将根据这个指针将请求转发到owner node。所以一个客户端最好一直只和一个节点连接,这样效率高一点。
Mnesia是RabbitMQ中的数据库,它是内嵌在Erlang中的no-SQL数据库。Exchange/Queue/Binding等的metadata信息都保存在mnesia的数据库文件中。关于RabbitMQ的集群信息也保存在这里。Rabbitmqctl的reset操作实际上就是清空了mnesia数据库所在目录的内容。

相关文章推荐
- RabbitMQ .NET消息队列使用入门(一)【简单示例】
- 利用rabbit_mq队列消息实现对一组主机进行命令下发
- RabbitMQ .NET消息队列使用入门(二)【多个队列间消息传输】
- 消息队列选型[首选Kafka](备选:RabbitMQ/NSQ/RocketMQ/disque/Kafka)
- rabbitmq plugins rabbitmq_delayed_message_exchange消息队列延迟消息插件
- 消息队列选型[首选Kafka](备选:RabbitMQ/NSQ/RocketMQ/disque/Kafka)
- Spring Boot + RabbitMQ 实现消息队列场景
- RabbitMQ .NET消息队列使用入门(二)【多个队列间消息传输】
- haproxy + rabbitmq + keepalived的高可用环境搭建
- 集群与负载均衡系列(6)——消息队列之rabbitMQ+spring-boot+spring amqp发送可靠的消息
- RabbitMQ .NET消息队列使用入门(三)【MVC实现RPC例子】
- spring boot Rabbitmq集成,延时消息队列实现
- RabbitMQ+PHP 消息队列环境配置
- RabbitMQ .NET消息队列使用入门(一)【简单示例】
- zookeeper + LevelDB + ActiveMQ实现消息队列高可用
- RabbitMQ .NET消息队列使用详解
- RabbitMQ+PHP 消息队列环境配置
- 消息队列系列(三):.Rabbitmq Trace的使用
- 高可用消息队列服务构建-RABBITMQ