python爬取新浪微博话题的相关数据
2017-08-23 14:37
281 查看
python爬取新浪微博话题的相关数据
python爬取新浪微博话题的相关数据说在前头
过程
第一步 导入模块
第二步 设置代理
第三步 获取网页
第四步 获取url
第五步 解析网页
第六步 写入csv
结语
说在前头
说明: 获取的微博数据主要有昵称,认证,发布日期,微博内容,来源,转发数,点赞数,评论数,用户id,用户关注数,用户粉丝数,用户性别python版本: Python version 3.6.1 |Anaconda custom (64-bit)| (default, May 11 2017, 13:25:24) [MSC v.1900 64 bit (AMD64)]
本人小白~~
最近由于某些原因,我需要从新浪微博的话题上爬取一些数据,折腾了一天,最后终于爬到了想要的数据。
我没有使用爬虫框架(\捂脸) 原因是我…不会使用… 但是自己手写爬虫会更灵活,也让自己熟悉爬虫的很多细节~~
我选择一些我感觉有难度的地方讲,剩下的大家扫一眼代码就行。
过程
第一步 导入模块
需要说明的是,除了经典的BeautifulSoup网页解析库
我使用了神奇的
fake-useragent这个随机生成各种 User-Agent 的库
爬取网页我使用的是
urllib.request库
from bs4 import BeautifulSoup # 解析网页 from fake_useragent import UserAgent # 随机生成User-agent import chardet # 有时会遇到编码问题 需要检测网页编码 import re, urllib.request, socket, time, random, csv, json
socket.setdefaulttimeout(10) #这里对整个socket层设置超时时间。后续文件中如果再使用到socket,不必再设置
第二步 设置代理
我使用的是西刺代理,通过解析网页获取代理池。def get_proxy():
# 报头设置
def header(website):
ua = UserAgent()
headers=("User-Agent", ua.random)
opener = urllib.request.build_opener()
opener.addheaders = [headers]
req = opener.open(website).read()
return req
# 读取网页
proxy_api = 'http://www.xicidaili.com/nn'
data = header(proxy_api).decode('utf-8')
data_soup = BeautifulSoup(data, 'lxml')
data_odd = data_soup.select('.odd')
data_ = data_soup.select('.')
# 解析代理网址 获取ip池(100个)
ip,port = [],[]
for i in range(len(data_odd)):
data_temp = data_odd[i].get_text().strip().split('\n')
while '' in data_temp:
data_temp.remove('')
ip.append(data_temp[0])
port.append(data_temp[1])
for i in range(len(data_)):
data_temp = data_[i].get_text().strip().split('\n')
while '' in data_temp:
data_temp.remove('')
ip.append(data_temp[0])
port.append(data_temp[1])
if len(ip) == len(port):
proxy = [':'.join((ip[i],port[i])) for i in range(len(ip))]
#print('成功获取代理ip与port!')
return proxy
else:
print('ip长度与port长度不一致!')
proxy = get_proxy()第三步 获取网页
实际操作的时候是先看网页,找到url,根据网页特征有针对性地来写函数的,但是这其实就是一个模板,基本的写法就是如下:# 获取微博移动端网页
def get_data(url, proxy_addr):
proxy = urllib.request.ProxyHandler({'http':proxy_addr})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
headers={
"User-Agent": UserAgent().random,
'Cookie': '你的cookie'
}
opener = urllib.request.build_opener()
opener.addheaders = [headers]
data = json.loads(opener.open(url).read()) # 注意这句命令
# data = opener.open(url).read()
# 一般用上面这个就行,但是微博有点特殊,返回的是类似字典的数据,所以就直接包装了,而且可以避开出现编码的问题
time.sleep(2)
yield data # 爬取的数据较多,使用生成器,减少占用内存此外 在调试爬虫的时候,我在爬下来的网页的编码上遇到很大问题,一直提示
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128),然后我用
chardet检测爬下来的网页是何种编码,发现的确是ascii码,并且无论怎样
decode都无法正确显示中文( utf-8 和 gbk 都不行)。
后来我发现有两种解决办法:
- 由于微博手机版的 api 返回的数据是类似 python 嵌套的字典 / json,所以在写爬取网页内容的时候用
json库直接处理包装成字典,然后函数的返回值就正显示中文了。否则,利用函数返回的网页内容再进行处理,就会返回上面的错误了。 实现的命令为:
json.loads(opener.open(url).read())
- 第二种是更一般的,本质的处理方法。URL标准只会允许ascii字符(数字、字母和一部分符号),其他字符(比如汉字)是不符合URL标准的。解决办法是进行URL编码。在python3的
urllib.request库中,
urllib.request.quote可以将不符合URL标准的字符编码成符合URL标准的字符,而相反的操作是
urllib.request.unquote,这个命令可以把符合URL标准的字符解码成其他编码。
urllib.request.quote("http://www.baidu.com")
# 返回结果为 'http%3A//www.baidu.com',很明显冒号':'就经过url编码变成 '%3'我爬取下来的内容是需要解码的,所以我应该使用
urllib.request.unquote命令。
第四步 获取url
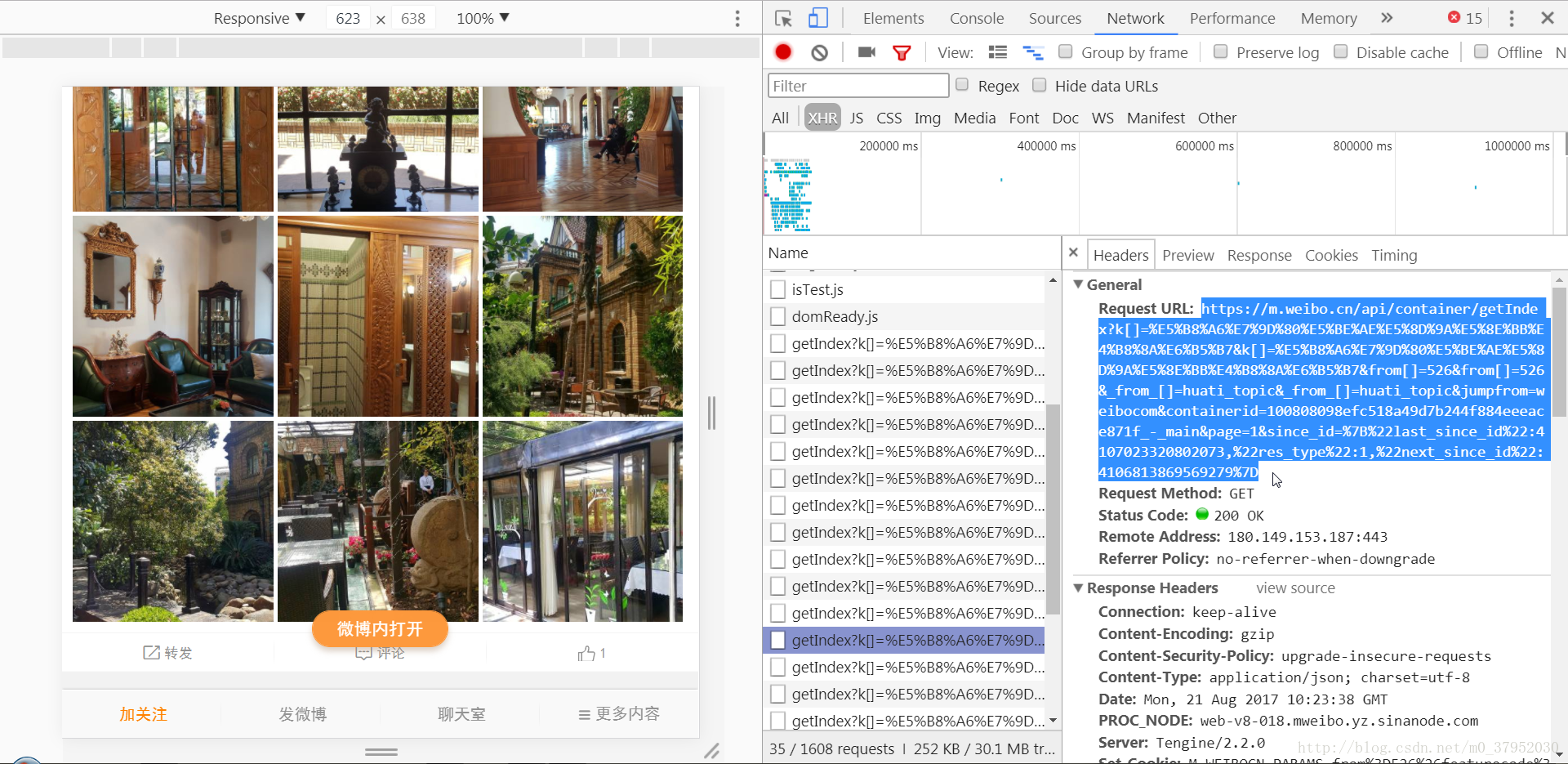
之前我一直用firefox浏览器,但是我打不开微博移动版,然后就去下载chrome浏览器了,我发现对微博移动版真的和友好。比如可以直接在网页版和移动版的微博中切换。
我发现微博的url不能通过传入
page= 数字来翻页,折腾了好久,最后决定手动翻页,复制url链接。
坏处有两个:
- 每次用chrome浏览器
F12调出开发者工具的时候,点最上面的工具栏第二个移动端图标的时候,翻到的页数是不一致的,有多有少,最少爬到200多条,不过我多次刷新尝试之后,可以爬到近1000条内容。
- … emm…碰到翻到很多页的时候,用鼠标去复制粘贴真的很累人…
(有些话题我翻到了50多个url,粘贴到心累)
粘贴下来的url链接就是这么长一串 ↓↓↓
url=['https://m.weibo.cn/api/container/getIndex?k[]=%E5%B8%A6%E7%9D%80%E5%BE%AE%E5%8D%9A%E5%8E%BB%E8%A5%BF%E8%97%8F&k[]=%E5%B8%A6%E7%9D%80%E5%BE%AE%E5%8D%9A%E5%8E%BB%E8%A5%BF%E8%97%8F&from[]=526&from[]=526&_from_[]=huati_topic&_from_[]=huati_topic&jumpfrom=weibocom&containerid=100808994babd45bcf6a67177ccf76defc0224', 'https://m.weibo.cn/api/container/getIndex?k[]=%E5%B8%A6%E7%9D%80%E5%BE%AE%E5%8D%9A%E5%8E%BB%E8%A5%BF%E8%97%8F&k[]=%E5%B8%A6%E7%9D%80%E5%BE%AE%E5%8D%9A%E5%8E%BB%E8%A5%BF%E8%97%8F&from[]=526&from[]=526&_from_[]=huati_topic&_from_[]=huati_topic&jumpfrom=weibocom&containerid=100808994babd45bcf6a67177ccf76defc0224_-_main', 'https://m.weibo.cn/api/container/getIndex?k[]=%E5%B8%A6%E7%9D%80%E5%BE%AE%E5%8D%9A%E5%8E%BB%E8%A5%BF%E8%97%8F&k[]=%E5%B8%A6%E7%9D%80%E5%BE%AE%E5%8D%9A%E5%8E%BB%E8%A5%BF%E8%97%8F&from[]=526&from[]=526&_from_[]=huati_topic&_from_[]=huati_topic&jumpfrom=weibocom&containerid=100808994babd45bcf6a67177ccf76defc0224_-_main&page=1&since_id=%7B%22last_since_id%22:4143222894867825,%22res_type%22:1,%22next_since_id%22:4142783499850575%7D']
其间又有很多曲折!!!
我发现那些乱码的东西其实是你传入的
话题名称,我通过下面的代码可以自由跳转到其他的话题 ~~~
var='带着微博去日本' var=urllib.request.quote(var) url='https://m.weibo.cn/api/container/getIndex?type=all&queryVal='+var+'&featurecode=20000320&luicode=10000011&lfid=106003type%3D1&title='+var+'&containerid=100103type%3D1%26q%3D'+var+'&page=1'
但是…我前面说过,即便修改
page的值,也无法翻到下一页,只能抓到 10-20 条内容
第五步 解析网页
我需要的数据主要是:昵称,认证,发布日期,微博内容,来源,转发数,点赞数,评论数,用户id,用户关注数,用户粉丝数,用户性别screen_name,Id,follow_count,followers_count,gender,verified,text,created_at,source,reposts_count,attitudes_count,comments_count = [],[],[],[],[],[],[],[],[],[],[],[] pattern = "#.*?#" # 我用来清理掉微博内容中插入#话题#的
# 解析网页
for a in range(len(url)):
for data in get_data(url[a], proxy[random.randint(3,50)]):
try:
for i in range(len(data['cards'])):
try:
for j in range(len(data['cards'][i]['card_group'])):
try:
content = re.sub(pattern,'',BeautifulSoup(data['cards'][i]['card_group'][j]['mblog']['text'], "lxml").get_text()).strip()
if content not in text:
try:
screen_name.append(data['cards'][i]['card_group'][j]['mblog']['user']['screen_name'])
Id.append(data['cards'][i]['card_group'][j]['mblog']['user']['id'])
follow_count.append(data['cards'][i]['card_group'][j]['mblog']['user']['follow_count'])
followers_count.append(data['cards'][i]['card_group'][j]['mblog']['user']['followers_count'])
gender.append(data['cards'][i]['card_group'][j]['mblog']['user']['gender'])
verified.append(data['cards'][i]['card_group'][j]['mblog']['user']['verified'])
text.append(content)
created_at.append(data['cards'][i]['card_group'][j]['mblog']['created_at'])
source.append(data['cards'][i]['card_group'][j]['mblog']['source'])
reposts_count.append(data['cards'][i]['card_group'][j]['mblog']['reposts_count'])
attitudes_count.append(data['cards'][i]['card_group'][j]['mblog']['attitudes_count'])
comments_count.append(data['cards'][i]['card_group'][j]['mblog']['comments_count'])
except:
pass
except:
pass
except:
pass
print("已解析%d,未解析%d,共%d链接..." %(a+1, len(url)-a-1, len(url)))
except:
pass
print("All done!")乍一看没有获取网页,其实我写在循环里面了,因为函数用生成器
yield返回了可迭代对象,所以循环起来不卡,而且不算慢。
你会看见许多
try...except...语句,其实一开始我没有写这么多的,我是通过跑了一遍遍渐渐把这个解析函数完善的,跑出来应该没有问题。
缩进的语法在这里就不是辣么实用了,一看走眼就会出错。不过我用的是
jupyter notebook,按住
alt键加上鼠标多行点选的感觉堪比
sublimetext3呢~~
跑出来的结果:

抓取的数据(部分):

当然,也可以获取 话题描述,用户认证描述 之类的数据,具体可以去看 返回的网页字典的键。
嘻嘻&& 我知道你懒,所以给你们找好啦~~
用户的相关信息在
data['cards'][0]['card_group'][0]['mblog']['user']下面。
data['cards'][0].keys() # dict_keys(['card_type', '_appid', '_cur_filter', 'title', 'show_type', 'buttontitle', 'scheme', 'hide_oids', 'card_group']) data['cards'][0]['card_group'][0].keys() # dict_keys(['card_type', 'itemid', 'show_type', 'scheme', 'mblog']) data['cards'][0]['card_group'][0]['mblog'].keys() #dict_keys(['created_at', 'id', 'mid', 'idstr', 'text', 'textLength', 'source', 'favorited', 'thumbnail_pic', 'bmiddle_pic', 'original_pic', 'is_vip_paid_status', 'is_paid', 'mblog_vip_type', 'user', 'picStatus', 'reposts_count', 'comments_count', 'attitudes_count', 'isLongText', 'visible', 'rid', 'mblog_show_union_info', 'is_controlled_by_server', 'timestamp_text', 'expire_after', 'page_info', 'bid', 'pics'])
# 话题描述 description[area[a]]=data['pageInfo']['desc_more'][0] # '阅读1.8亿\u3000讨论7.7万\u3000粉丝2623'
第六步 写入csv
# 数据写入csv
with open('西藏.csv','w',encoding = 'utf-8', newline = '') as f:
w = csv.writer(f)
w.writerow(['screen_name','verified','created_at','text','source','reposts_count',
'attitudes_count','comments_count','Id','follow_count','followers_count','gender'])
with open('西藏.csv', 'a+', encoding = 'utf-8') as f:
w = csv.writer(f, lineterminator='\n')
for i in range(0, len(text)):
try:
w.writerow([screen_name[i],verified[i],created_at[i],text[i],source[i],reposts_count[i],attitudes_count[i],
comments_count[i],Id[i],follow_count[i],followers_count[i],gender[i]])
except Exception as e:
print('第 ', i , text[i],'error: ', e, '\n')
print("成功写入文件!")P.S:
我用Excel打开之后是乱码的:
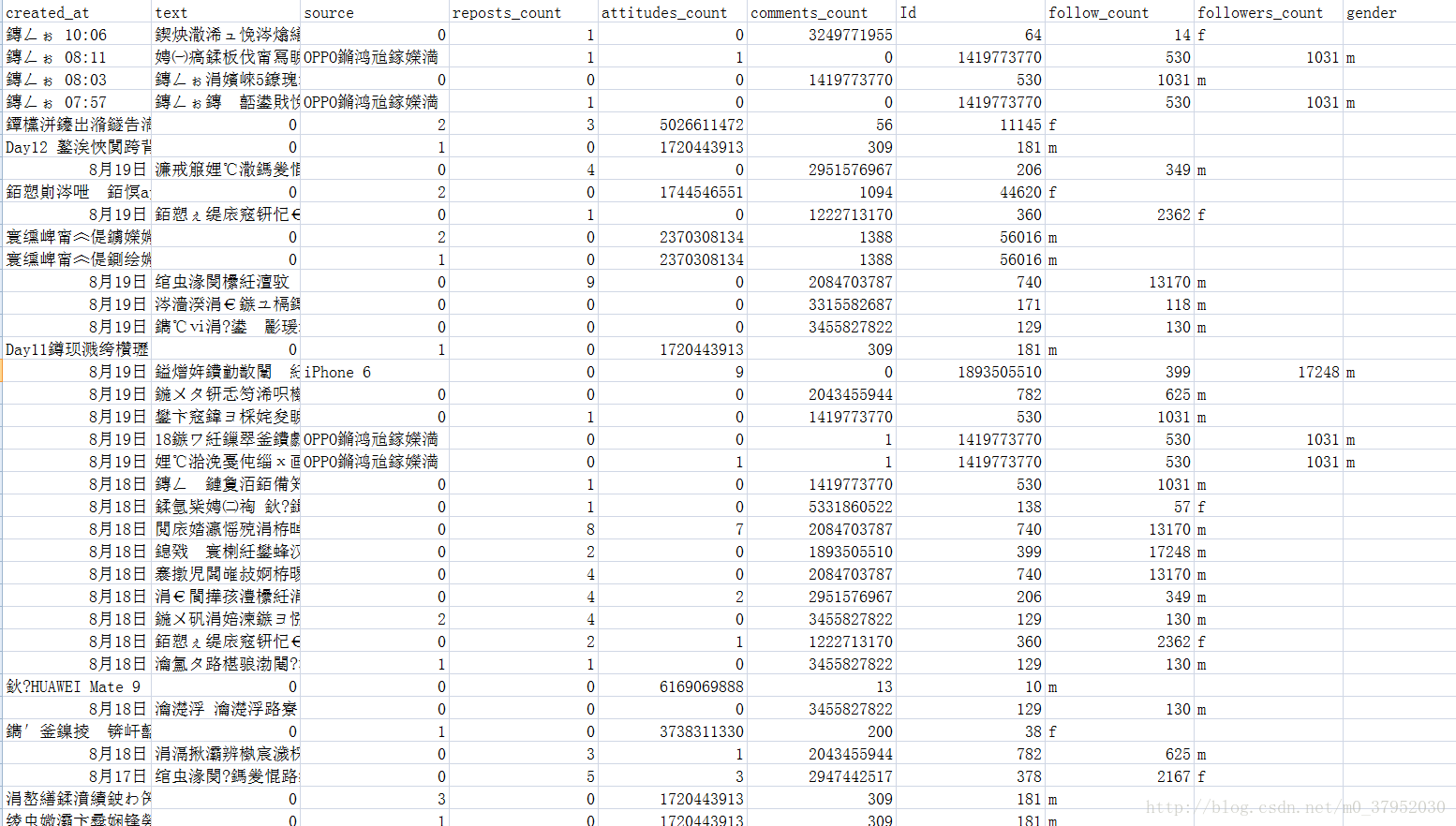
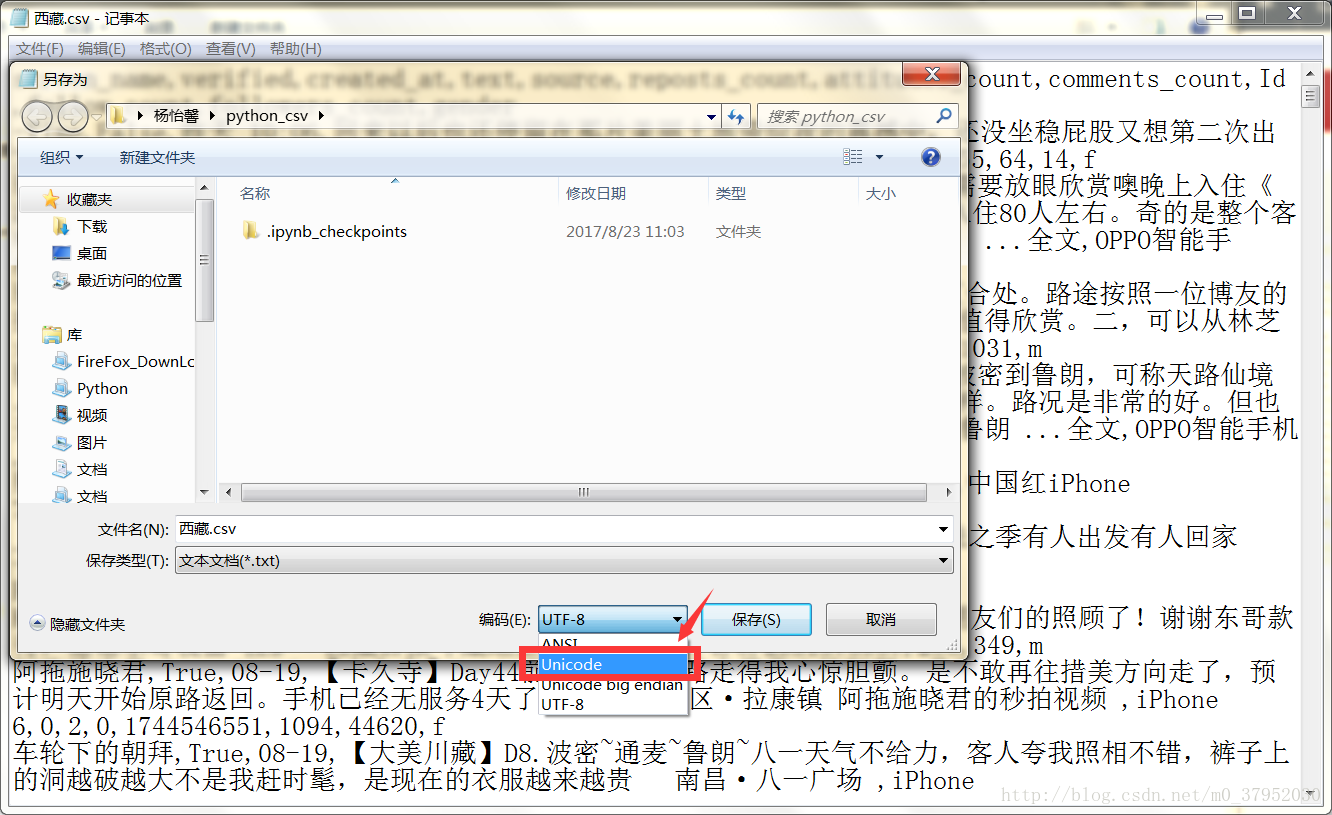
原因是编码问题,解决办法是csv文件用记事本打开,然后
另存为,选择
unicode编码 ↓
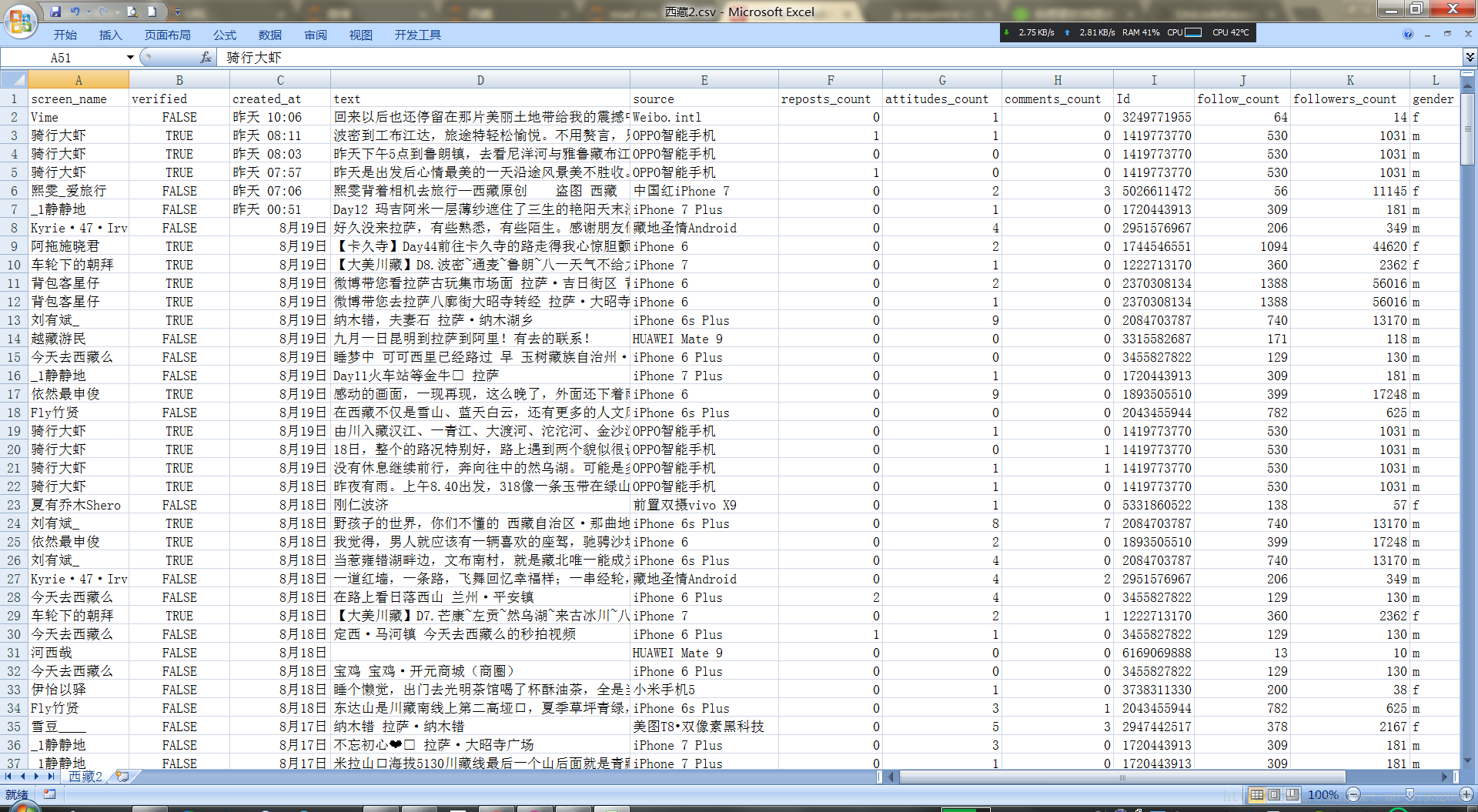
然后再用Excel打开就是
结语
就这样吧 ~~~难得今天有空就洋洋洒洒写了这么多
第一次在这里写文章
也是我第一次写科技类的经验文章
谢谢!

相关文章推荐
- 新浪微博数据挖掘(python)本周人们在讨论的热门话题的提取
- 最新Python相关的就业数据分析!
- Python 获取新浪微博的热门话题 (API)
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
- Python 核心编程笔记_Chapter_5_Note_1 数据类型及相关运算
- 小试牛刀之python实现批量获取主机相关数据
- python数据分析复盘——数据分析相关库之Matplotlib
- python Elasticsearch 遍历相关数据
- 5个数据科学相关的Python库
- Python数据类型和相关函数方法
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
- Python脚本进行主播招募相关数据统计的案例
- Python爬虫数据分析相关资源
- python 扩展相关话题
- Python之数据加密与解密及相关操作(hashlib、hmac、random、base64、pycrypto)
- Python数据分析模块 | pandas做数据分析(三):统计相关函数
- Python知乎热门话题数据的爬取实战
- 编写Python代码——爬取百度百科Python词条相关1000个页面数据【未完慕课】
- [置顶] Python数据相关系数矩阵和热力图轻松实现
- 新浪微博数据挖掘食谱之二: 话题篇 (selenium)