cbow&&skipgram详细
2017-08-21 12:54
218 查看
前面:关于层次huffman树和负例采样也要知道的,这里就不详细写了
来源于:https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247485159&idx=1&sn=819152633c53fcae5334d031a05f7bf3&chksm=ebb43e33dcc3b725631e997132b41d34d982304c1ceb356c16b1559f92c69e6c55df009f1f8d&mpshare=1&scene=1&srcid=0823UQXmYFaNd8R09gid8c5G&key=2ae3330fddc8e50eea1a6f1a446dba6e22c4df1547f80f06454dd7dc257c3408b3fd8a793df2daef0814ffdddb04ea449089262bab967b869d44bf709cdc4f3bd471051cf0ca48d048749f03c88cd7b8&ascene=0&uin=MjM3NzI2MTEwMQ%3D%3D&devicetype=iMac+MacBookPro13%2C1+OSX+OSX+10.12+build(16A2323a)&version=12010210&nettype=WIFI&fontScale=100&pass_ticket=J6Qss31QuwUPuaYSQ2EvC0g2tE7VXzNVNeiaNQVW%2BuvqPag3hk1vixMvx3RfwnfU
一个单词,神经网络理解不了,需要人转换成数字再喂给它。最naive的方式就是one-hot,但是太过于稀疏,不好。所以在改进一下,把one-hot进一步压缩成一个dense vector。
word2vec算法就是根据上下文预测单词,从而获得词向量矩阵。
预测单词的任务只是一个幌子,我们需要的结果并不是预测出来的单词,而是通过预测单词这个任务,不断更新着的参数矩阵weights。
预测任务由一个简单的三层神经网络来完成,其中有两个参数矩阵V与U,V∈RDh*|W|,U∈R|W|*Dh。
V是输入层到隐藏层的矩阵,又被称为look-up table(因为,输入的是one-hot向量,一个one-hot向量乘以一个矩阵相当于取了这个矩阵的其中一列。将其中的每一列看成是词向量)
U是隐藏层到输出层的矩阵,又被称为word representation matrix(将其中的每一行看成是词向量)
最后需要的词向量矩阵是将两个词向量矩阵相加 =V+UT,然后每一列就是词向量。
2两种实现方法
输入:一个中心词(center word,x∈R|W|*1)
参数:一个look up table V∈RDh*|W|,一个word representation matrix U∈R|W|*Dh

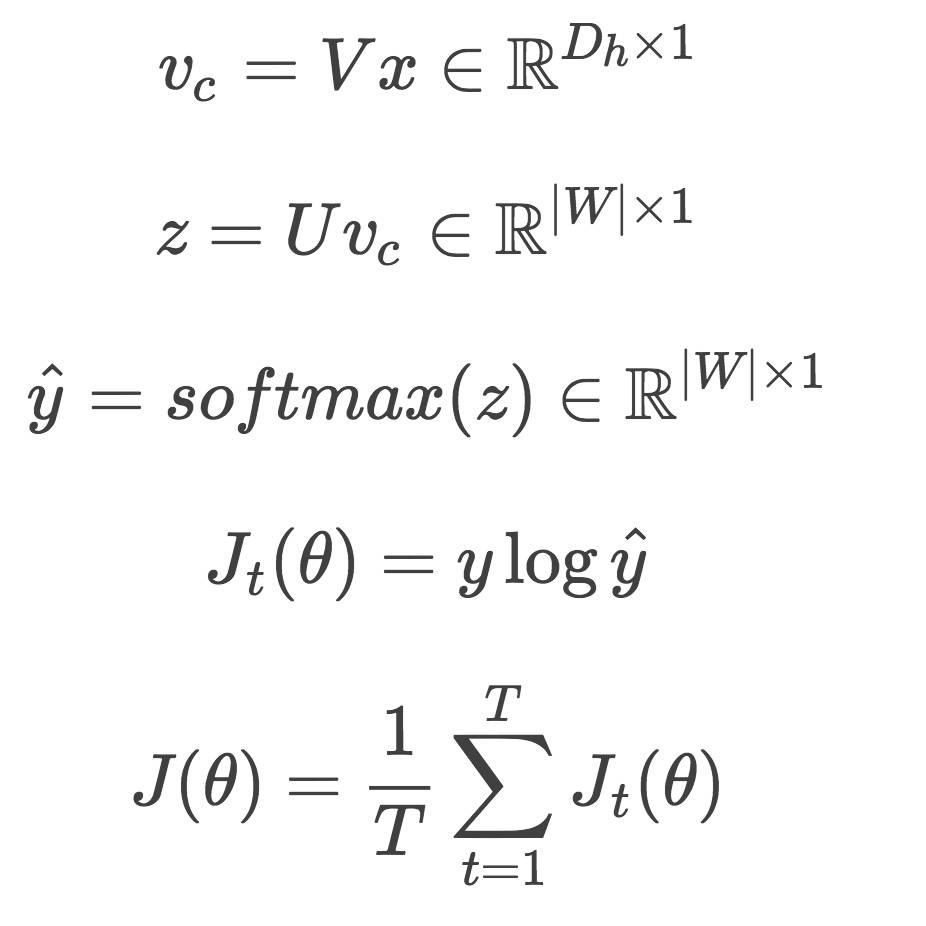
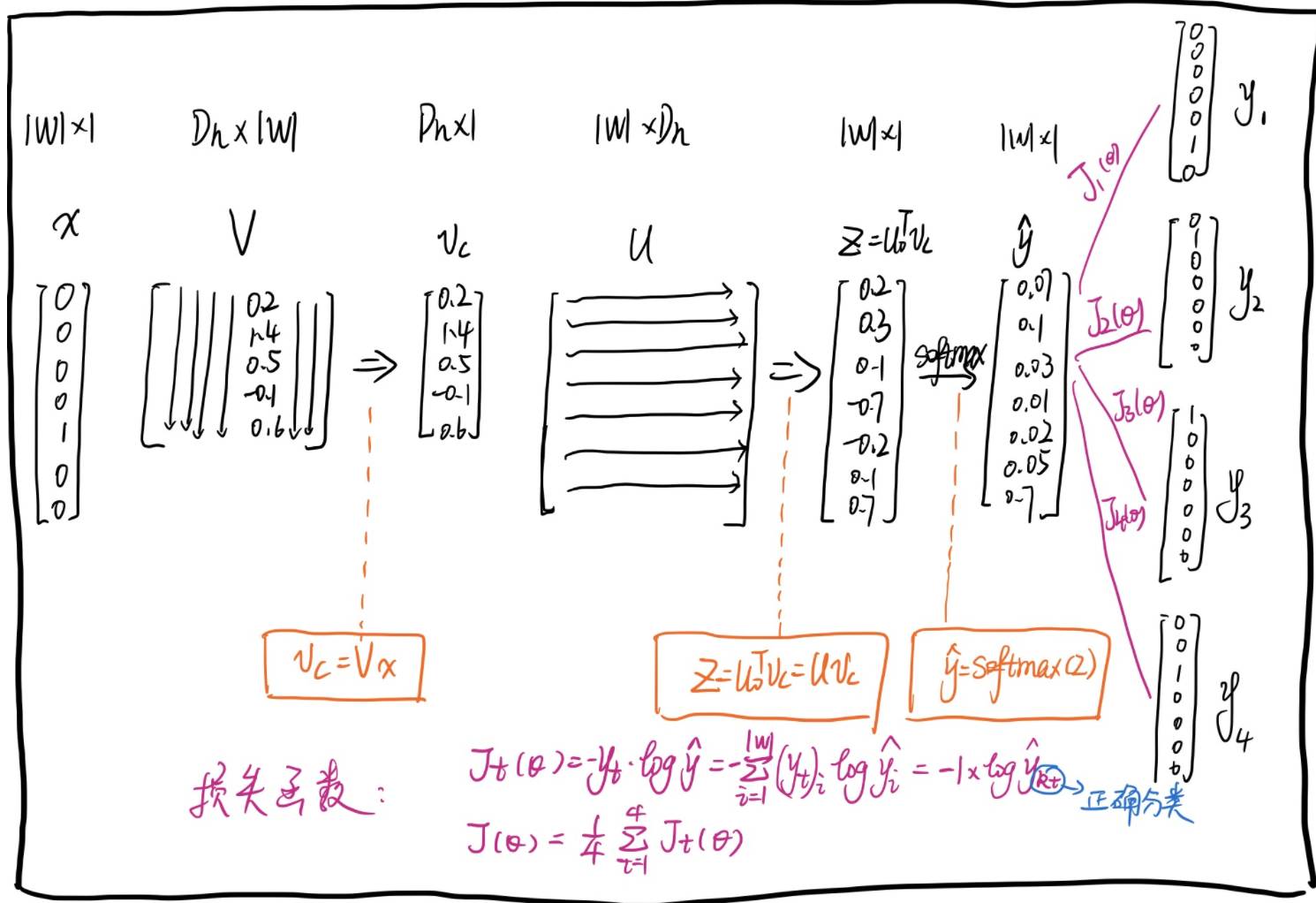
Skip-Gram步骤图:

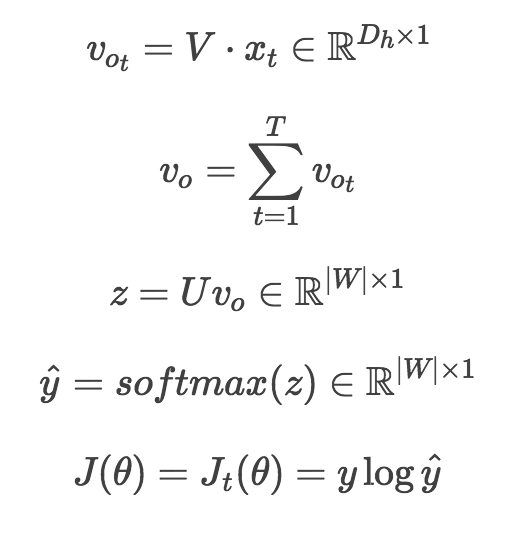
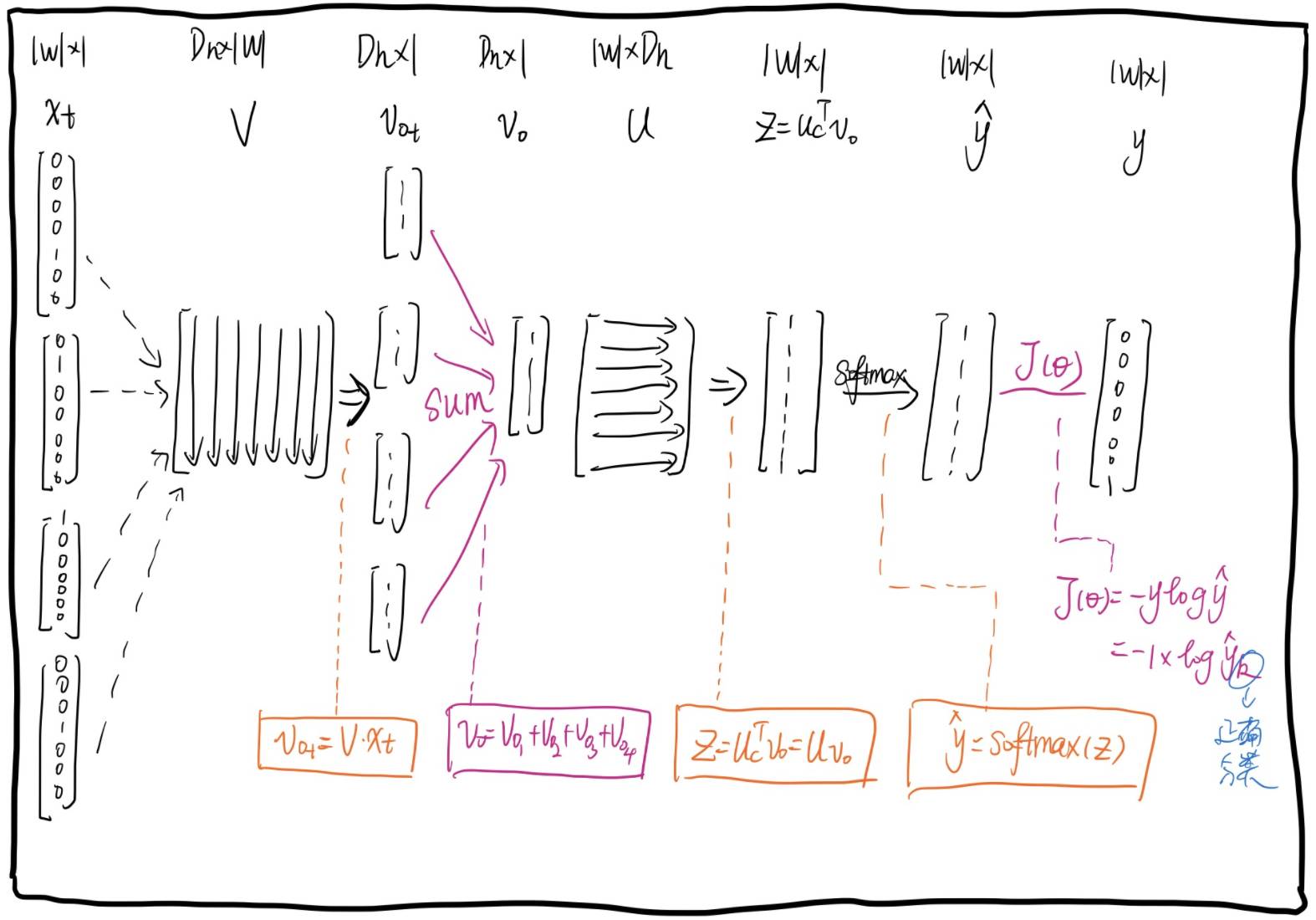
CBOW步骤图:
来源于:https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247485159&idx=1&sn=819152633c53fcae5334d031a05f7bf3&chksm=ebb43e33dcc3b725631e997132b41d34d982304c1ceb356c16b1559f92c69e6c55df009f1f8d&mpshare=1&scene=1&srcid=0823UQXmYFaNd8R09gid8c5G&key=2ae3330fddc8e50eea1a6f1a446dba6e22c4df1547f80f06454dd7dc257c3408b3fd8a793df2daef0814ffdddb04ea449089262bab967b869d44bf709cdc4f3bd471051cf0ca48d048749f03c88cd7b8&ascene=0&uin=MjM3NzI2MTEwMQ%3D%3D&devicetype=iMac+MacBookPro13%2C1+OSX+OSX+10.12+build(16A2323a)&version=12010210&nettype=WIFI&fontScale=100&pass_ticket=J6Qss31QuwUPuaYSQ2EvC0g2tE7VXzNVNeiaNQVW%2BuvqPag3hk1vixMvx3RfwnfU
一个单词,神经网络理解不了,需要人转换成数字再喂给它。最naive的方式就是one-hot,但是太过于稀疏,不好。所以在改进一下,把one-hot进一步压缩成一个dense vector。
word2vec算法就是根据上下文预测单词,从而获得词向量矩阵。
预测单词的任务只是一个幌子,我们需要的结果并不是预测出来的单词,而是通过预测单词这个任务,不断更新着的参数矩阵weights。
预测任务由一个简单的三层神经网络来完成,其中有两个参数矩阵V与U,V∈RDh*|W|,U∈R|W|*Dh。
V是输入层到隐藏层的矩阵,又被称为look-up table(因为,输入的是one-hot向量,一个one-hot向量乘以一个矩阵相当于取了这个矩阵的其中一列。将其中的每一列看成是词向量)
U是隐藏层到输出层的矩阵,又被称为word representation matrix(将其中的每一行看成是词向量)
最后需要的词向量矩阵是将两个词向量矩阵相加 =V+UT,然后每一列就是词向量。
2两种实现方法
2.1. Skip-Gram
训练任务:根据中心词,预测出上下文词输入:一个中心词(center word,x∈R|W|*1)
参数:一个look up table V∈RDh*|W|,一个word representation matrix U∈R|W|*Dh
Skip-Gram步骤图:
2.2. CBOW
与Skip-Gram相反,是通过完成上下文词预测中心词的任务来训练词向量的。CBOW步骤图:

相关文章推荐
- CBOW and Skip-gram model
- Word2vec基础介绍(四):CBOW和skip-gram模型
- 自己动手写word2vec (四):CBOW和skip-gram模型
- NLP|Skip-Gram模型介绍(讲解十分详细)
- CBOW and Skip-gram model
- V4L2 API详解 <二> Camera详细设置
- linux学习之旅(四)&& 管道详细
- 【Unity&DragonBone】(代码分析)创建骨骼选择动画详细
- 详细讲述 SQL SERVER&nb…
- 异常详细信息: System.Web.HttpRequestValidationException: 从客户端(fck_content="<span style="bac...")中检测到有潜在危
- Word2Vec教程 - Skip-Gram模型
- BossPrefs&nbsp;v1.62详细教程及技巧
- C语言第二天课堂笔记<详细+注释>
- HTML元素详细介绍之Audio&Video(一)
- HTML<marquee>标签的详细使用介绍
- 详细解读Volley(三)—— ImageLoader & NetworkImageView
- 易语言"发送消息()"_SendMessage详细说明
- 443端口 (HTTPS) && 计算机常用端口号一览功用详细说明
- Android:这是一份全面 &amp; 详细的Retrofit 2.0 源码分析指南
- 这是网友发的一道很常见的面试题, for(foo('A');foo('B')&&(i<2);foo('C')) ,其实考的就是for (初始化语句; 判断条件; 循环条件) ,现在详细解析一下!