scrapy爬取途牛网站旅游数据
2017-08-20 00:00
176 查看
描述:采取了scrapy框架对途牛网旅游数据进行了爬取,刚开始练手,所以只爬了四个字段用作测试,分别是景点名称、景点位置、景点开放时间、景点描述,爬取结果存的是json格式。
部分数据:

部分代码:
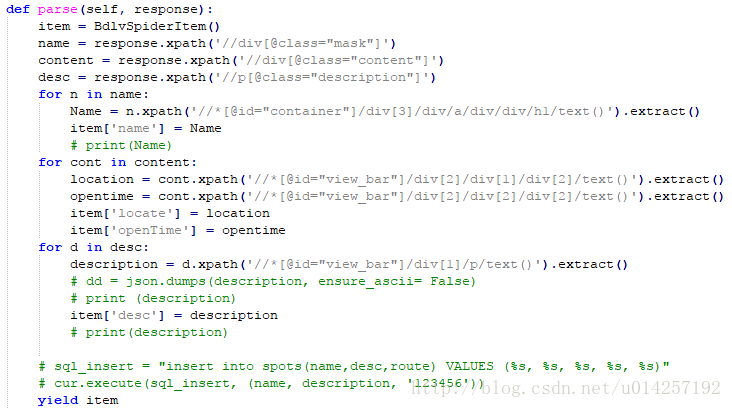
遇到的问题:start_urls是不能动态添加URL的,这个还需要研究,这里只是简单把所有待爬取的网址全扔进了start_urls里面,这是可行的,但是对网址的预处理就很耗时间了。然后是对汉字编码的处理,在scrapy中一开始传到json中的数据总是/uxxx类型的,这需要在pipeline.py、setting.py中都进行修改,具体修改如下:
在pipelines.py中,修改代码如下:
在settings.py中,添加如下代码:
其中,BdlvSpiderPipeline是pipelines.py中的类名。
部分数据:
部分代码:
遇到的问题:start_urls是不能动态添加URL的,这个还需要研究,这里只是简单把所有待爬取的网址全扔进了start_urls里面,这是可行的,但是对网址的预处理就很耗时间了。然后是对汉字编码的处理,在scrapy中一开始传到json中的数据总是/uxxx类型的,这需要在pipeline.py、setting.py中都进行修改,具体修改如下:
在pipelines.py中,修改代码如下:
def __init__(self):
self.file = codecs.open('items.json', 'wb', encoding='utf-8')
#
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
#
def spider_closed(self, spider):
self.file.close()在settings.py中,添加如下代码:
ITEM_PIPELINES = {
'bdlv_spider.pipelines.BdlvSpiderPipeline': 800,
}其中,BdlvSpiderPipeline是pipelines.py中的类名。

相关文章推荐
- 一个网站的诞生02--用Scrapy抓取数据
- Scrapy爬取电商网站京东奶粉商品价格数据-附各种问题解决
- python爬取携程和蚂蜂窝的景点评论数据\python爬取携程评论数据\python旅游网站评论数
- 大数据下的旅游网站:Hopper为你推荐最爱的景点
- 使用Scrapy爬取一个网站的数据
- 用scrapy爬取网站数据,以api方式
- 使用scrapy爬取网站的商品数据
- Scrapy爬取makepolo网站数据深入详解
- Scrapy:抓取返回数据格式为JSON的网站内容
- Python3 大型网络爬虫实战 004 — scrapy 大型静态商城网站爬虫项目编写及数据写入数据库实战 — 实战:爬取淘宝
- python爬取携程和蚂蜂窝的景点评论数据\python爬取携程评论数据\python旅游网站评论数据爬虫
- Scrapy:抓取返回数据格式为JSON的网站内容
- 爬取携程和蚂蜂窝的景点评论数据\携程评论数据爬取\旅游网站数据爬取
- Scrapy爬虫抓取网站数据
- 利用scrapy将爬到的数据保存到mysql(防止重复)
- DEDECMS网站数据备份还原教程
- 【大数据部落】用R进行网站评论文本挖掘聚类
- 网站生成静态页面攻略2:数据采集
- 【精华阅读】目的性越强,你的网站/应用数据分析越有价值
- Scrapy爬虫-大数据爬取时内存过大的解决办法(转)