spark中reduce和reduceByKey的区别
2017-08-19 00:00
567 查看
首先我们先讲讲两个函数在功能上的作用与区别是什么,然后我们再深入讨论两个函数在内部机理有什么不同。
具体过程,RDD有1 2 3 4 5 6 7 8 9 10个元素,
1+2=3
3+3=6
6+4=10
10+5=15
15+6=21
21+7=28
28+8=36
36+9=45
45+10=55
那么讲到这里,差不多函数功能已经明了了,而reduceByKey的是如何运行的呢?下面这张图就清楚了揭示了其原理:
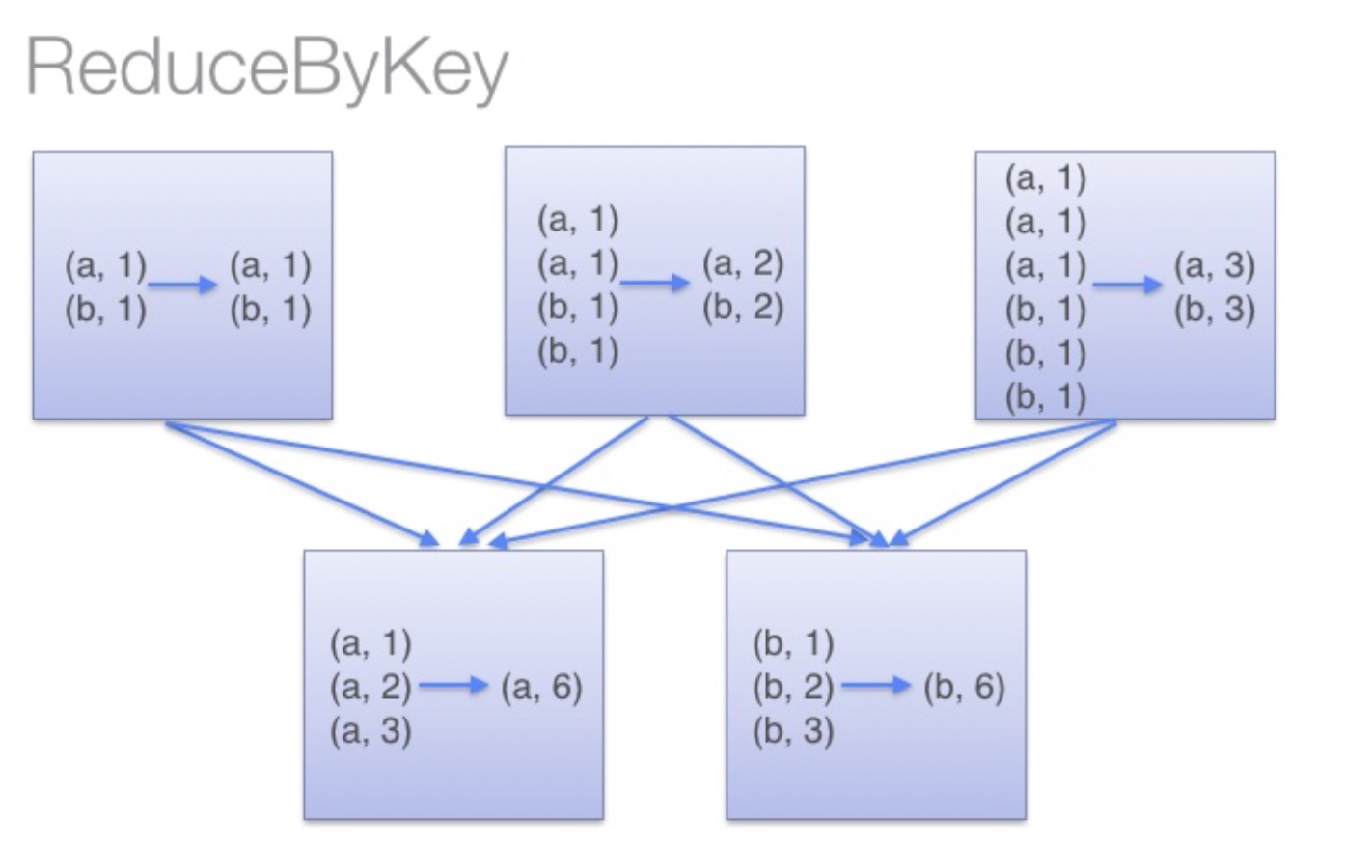
亦即,它会在数据搬移以前,提前进行一步reduce操作。
可以实现同样功能的还有GroupByKey函数,但是,groupbykey函数并不能提前进行reduce,也就是说,上面的处理过程会翻译成这样:
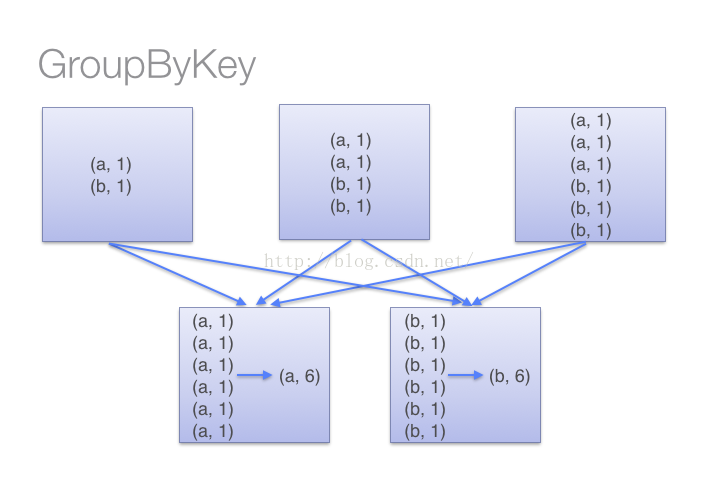
所以在处理大规模应用的时候,应该使用reduceByKey函数。
reduce(binary_function)
reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。具体过程,RDD有1 2 3 4 5 6 7 8 9 10个元素,
1+2=3
3+3=6
6+4=10
10+5=15
15+6=21
21+7=28
28+8=36
36+9=45
45+10=55
reduceByKey(binary_function)
reduceByKey就是对元素为KV对的RDD中Key相同的元素的Value进行binary_function的reduce操作,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。那么讲到这里,差不多函数功能已经明了了,而reduceByKey的是如何运行的呢?下面这张图就清楚了揭示了其原理:
亦即,它会在数据搬移以前,提前进行一步reduce操作。
可以实现同样功能的还有GroupByKey函数,但是,groupbykey函数并不能提前进行reduce,也就是说,上面的处理过程会翻译成这样:
所以在处理大规模应用的时候,应该使用reduceByKey函数。

相关文章推荐
- 【转载】Spark中:reduceByKey和groupByKey区别与用法
- 【Spark系列2】reduceByKey和groupByKey区别与用法
- 【Spark系列2】reduceByKey和groupByKey区别与用法
- 在Spark中关于groupByKey与reduceByKey的区别
- Spark中groupBy groupByKey reduceByKey的区别
- 请教Spark 中 combinebyKey 和 reduceByKey的传入函数参数的区别?
- Spark groupByKey,reduceByKey,sortByKey算子的区别
- Spark中groupByKey与reduceByKey算子之间的区别
- reduce 与 reduceByKey 区别
- reduce 与 reduceByKey 区别
- Spark API编程动手实战-04-以在Spark 1.2版本实现对union、groupByKey、join、reduce、lookup等操作实践
- Spark RDD/Core 编程 API入门系列之map、filter、textFile、cache、对Job输出结果进行升和降序、union、groupByKey、join、reduce、look
- <转>Sparkstreaming reduceByKeyAndWindow(_+_, _-_, Duration, Duration) 的源码/原理解析
- Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四)
- 转载:reduceByKey和groupByKey区别与用法
- reduceByKey和groupByKey区别与用法
- reduce 与 reduceByKey 区别
- reduce 与 reduceByKey 区别
- 深入理解Spark算子之 reduceByKey
- spark 的transformations之bykey的区别