Python数据分析练习:北京、广州PM2.5空气质量分析(1)
2017-08-18 11:20
1381 查看
由于雾霾问题,全社会都很关注空气质量,政府也花了很多钱力图改善空气质量。我们作为城市市民经常要问:我们城市的空气质量到底怎样?这几年我们城市的空气质量是在改善还是恶化?我们城市的空气质量与其他城市相比,是更好还是更差?
官方媒体一般都是说:我们的空气质量在改善,但有数据证明吗?官方数据可信吗?我们心存疑虑。所以,作为数据狗,还是自己动手吧。
PM2.5是最近几年特别热议的空气质量指标,这要归功于美帝大使馆哦。美国驻华使馆和领馆自己检测PM2.5数据并且在官网发布,这才让国人知道了这个指标,后来国内官方也开始公布这个指标了。
言归正传,差点忘了,这是一篇Python技术贴。回到这篇文章的主题:用Python做数据分析。我生活在广州,当然以我大广州为分析目标了。
数据源:美国驻华使馆的空气质量检测数据,http://www.stateair.net/web/historical/1/1.html 包含以下字段:
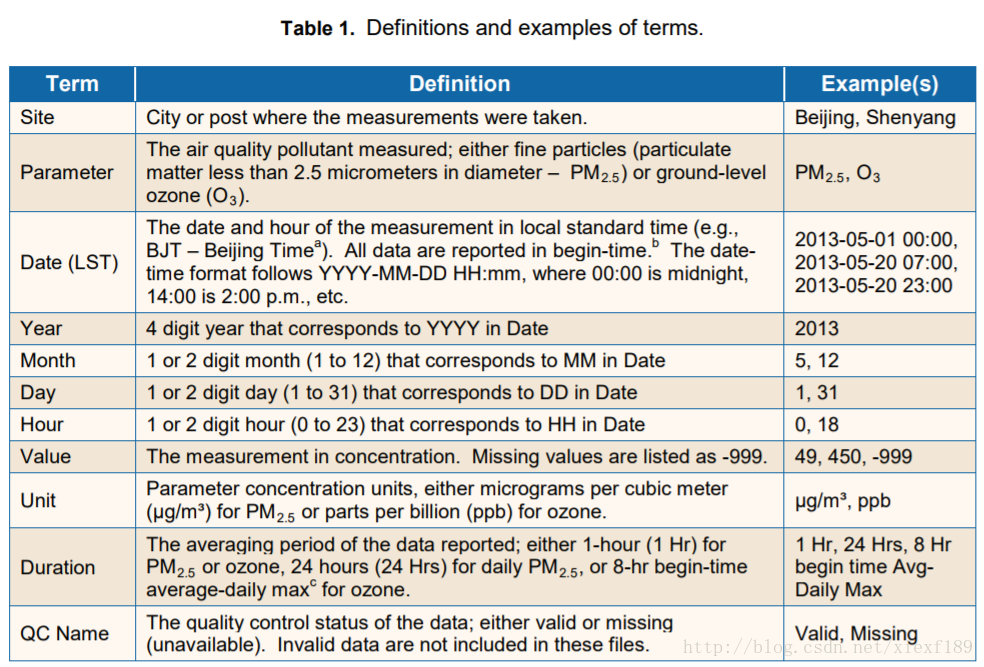
其中,PM2.5数值所代表的空气质量评价如下表1-1所示:

在此基础上,如果指数大于500,就是大家戏称为“爆表”
问题:
一.广州的空气质量总体如何?
二.广州最近两年的空气质量是否有改善?
三.广州北京两地的空气质量对比
这几个问题其实比较大而空,要落实到具体的指标和维度。从我们掌握的以上数据出发,可以从以下几个指标和维度分析:
1.2016年全年来看,空气质量较好(PM2.5<=100)的天数占比是多少?2015年相比2016年的对比?北京与各自的对比如何?
2.2016年全年来看,空气质量最严重(PM2.5>300)的天数占比是多少?2015年相比2016年的对比?北京与各自的对比如何?
3.2016年全年来看,空气质量与季节(月份)的变化关系是什么?
4.2016年与2015年同时间点对比,空气质量较好和较差的次数分别是多少?
5.2016年广州与北京同时间点对比,空气质量较好和较差的次数分别是多少?
通过以上维度分析,可以基本对前面的三大问题得出大致的判断。当然,有兴趣的童鞋可以根据原始数据出发,从更多的维度进行分析哦。
下面就开始进入数据集吧。
从美驻华使馆官网下载了广州、北京两个城市,2015年和2016年的PM2.5数据。分别是这四个文件: Beijing_2015_HourlyPM25_created20160201.csv
Beijing_2016_HourlyPM25_created20170201.csv
Guangzhou_2015_HourlyPM25_created20170201.csv
Guangzhou_2016_HourlyPM25_created20170201.csv
为了简化工作,每个文件只保留这几个字段:Year、Month、Day、Hour、Value和QC name,用Excel删掉其他的字段和文字,千万注意要保留表头哦。
经过大致观察,可以发现以下几点:
数据以csv格式保存,每年1个文件
每个小时一条检测数据
In [1]:
pandas是Python中常用的数据分析工具,包含了大量简便的数据分析处理方法。本文通过这个例子,展现了几个常用的pandas使用方法。
其中,使用pandas可以很方便地从csc文件中读取数据,保存在DataFrame对象中,方法如下:
In [2]:
拿到数据集,并且导入了DataFrame对象后,我们需要对数据进行观察,看看是否有缺失和错误的情况,并且对数据集进行必要的清洗处理,以便后续得到更准确的分析结果。
In [3]:
Out[3]:
In [4]:
Out[4]:
从简要描述中,可以看出Value字段(pm2.5的值)最小值是-999,正常来说,PM2.5的值不会小于零的,这说明有些观测值是缺失或者记录错误。我们可以计算一下其中有多少Value<0的记录:
In [5]:
Out[5]:
全年8000多条数据中,只有97条记录缺失或错误,所以把这97条记录删除,对整个分析影响不大。以下把缺失或错误的记录删除:
In [6]:
再用describe方法看看数据集的概况:
In [7]:
Out[7]:
可以看出,Value字段最小值不再为负数,这样的数据基本可信。
另外,我们还要为数据集增加一个字段,根据前面表1-1的划分方法,把pm2.5的测量值Value,转换为空气质量等级。 首先,我们先写一个函数,通过pm2.5测量值对应的空气质量等级。
In [8]:
Out[8]:
In [9]:
以下使用DataFrame的apply函数,增加一个字段‘Grade’,并且根据‘Value’字段的值,调用前面的转换函数,为‘Grade’字段赋值。
In [10]:
再来看看增加字段后的数据集
In [11]:
Out[11]:
经过以上的处理,我们就把北京2015年的PM2.5数据集处理完成了。对于其他三个表格,我们都采取类似的处理。
In [12]:
In [13]:
Out[13]:
In [14]:
In [15]:
Out[15]:
In [16]:
In [17]:
Out[17]:
好了,我们已经把本次分析所需的数据集全部准备完毕,接下来就是进行数据的分析
<未完待续>
官方媒体一般都是说:我们的空气质量在改善,但有数据证明吗?官方数据可信吗?我们心存疑虑。所以,作为数据狗,还是自己动手吧。
PM2.5是最近几年特别热议的空气质量指标,这要归功于美帝大使馆哦。美国驻华使馆和领馆自己检测PM2.5数据并且在官网发布,这才让国人知道了这个指标,后来国内官方也开始公布这个指标了。
言归正传,差点忘了,这是一篇Python技术贴。回到这篇文章的主题:用Python做数据分析。我生活在广州,当然以我大广州为分析目标了。
数据源:美国驻华使馆的空气质量检测数据,http://www.stateair.net/web/historical/1/1.html 包含以下字段:
其中,PM2.5数值所代表的空气质量评价如下表1-1所示:
在此基础上,如果指数大于500,就是大家戏称为“爆表”
问题:
一.广州的空气质量总体如何?
二.广州最近两年的空气质量是否有改善?
三.广州北京两地的空气质量对比
这几个问题其实比较大而空,要落实到具体的指标和维度。从我们掌握的以上数据出发,可以从以下几个指标和维度分析:
1.2016年全年来看,空气质量较好(PM2.5<=100)的天数占比是多少?2015年相比2016年的对比?北京与各自的对比如何?
2.2016年全年来看,空气质量最严重(PM2.5>300)的天数占比是多少?2015年相比2016年的对比?北京与各自的对比如何?
3.2016年全年来看,空气质量与季节(月份)的变化关系是什么?
4.2016年与2015年同时间点对比,空气质量较好和较差的次数分别是多少?
5.2016年广州与北京同时间点对比,空气质量较好和较差的次数分别是多少?
通过以上维度分析,可以基本对前面的三大问题得出大致的判断。当然,有兴趣的童鞋可以根据原始数据出发,从更多的维度进行分析哦。
下面就开始进入数据集吧。
1. 数据集下载、读取和清洗
从美驻华使馆官网下载了广州、北京两个城市,2015年和2016年的PM2.5数据。分别是这四个文件: Beijing_2015_HourlyPM25_created20160201.csvBeijing_2016_HourlyPM25_created20170201.csv
Guangzhou_2015_HourlyPM25_created20170201.csv
Guangzhou_2016_HourlyPM25_created20170201.csv
为了简化工作,每个文件只保留这几个字段:Year、Month、Day、Hour、Value和QC name,用Excel删掉其他的字段和文字,千万注意要保留表头哦。
经过大致观察,可以发现以下几点:
数据以csv格式保存,每年1个文件
每个小时一条检测数据
首先引入必要的Python包
In [1]:import unicodecsv import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sb %matplotlib inline
从csv文件中读入数据
pandas是Python中常用的数据分析工具,包含了大量简便的数据分析处理方法。本文通过这个例子,展现了几个常用的pandas使用方法。其中,使用pandas可以很方便地从csc文件中读取数据,保存在DataFrame对象中,方法如下:
In [2]:
# 从csv中读取北京2015年pm2.5数据,保存在DataFrame中
df_bj2015 = pd.read_csv('data/Beijing_2015_HourlyPM25_created20160201.csv')
# 重新设定各个字段的名称
df_bj2015.columns=['Year','Month','Day','Hour','Value','QC']
数据探索和清洗
拿到数据集,并且导入了DataFrame对象后,我们需要对数据进行观察,看看是否有缺失和错误的情况,并且对数据集进行必要的清洗处理,以便后续得到更准确的分析结果。In [3]:
# 查看DataFrame中的前几条数据 df_bj2015.head()
Out[3]:
| Year | Month | Day | Hour | Value | QC | |
|---|---|---|---|---|---|---|
| 0 | 2015 | 1 | 1 | 0 | 22 | Valid |
| 1 | 2015 | 1 | 1 | 1 | 9 | Valid |
| 2 | 2015 | 1 | 1 | 2 | 9 | Valid |
| 3 | 2015 | 1 | 1 | 3 | 13 | Valid |
| 4 | 2015 | 1 | 1 | 4 | 10 | Valid |
# DataFrame的简要描述 df_bj2015.describe()
Out[4]:
| Year | Month | Day | Hour | Value | |
|---|---|---|---|---|---|
| count | 8760.0 | 8760.000000 | 8760.000000 | 8760.000000 | 8760.000000 |
| mean | 2015.0 | 6.526027 | 15.720548 | 11.500114 | 71.658904 |
| std | 0.0 | 3.448048 | 8.796749 | 6.922433 | 139.751292 |
| min | 2015.0 | 1.000000 | 1.000000 | 0.000000 | -999.000000 |
| 25% | 2015.0 | 4.000000 | 8.000000 | 5.750000 | 21.000000 |
| 50% | 2015.0 | 7.000000 | 16.000000 | 11.500000 | 53.000000 |
| 75% | 2015.0 | 10.000000 | 23.000000 | 17.250000 | 108.000000 |
| max | 2015.0 | 12.000000 | 31.000000 | 23.000000 | 722.000000 |
In [5]:
len(df_bj2015.ix[df_bj2015.Value<0, :])
Out[5]:
97
全年8000多条数据中,只有97条记录缺失或错误,所以把这97条记录删除,对整个分析影响不大。以下把缺失或错误的记录删除:
In [6]:
# 把错误值置为空值 df_bj2015.loc[df_bj2015.Value<0,'Value']=np.nan # 删除空值记录 df_bj2015.dropna(inplace=True)
再用describe方法看看数据集的概况:
In [7]:
df_bj2015.describe()
Out[7]:
| Year | Month | Day | Hour | Value | |
|---|---|---|---|---|---|
| count | 8663.0 | 8663.000000 | 8663.000000 | 8663.000000 | 8663.000000 |
| mean | 2015.0 | 6.538728 | 15.674939 | 11.494055 | 82.733810 |
| std | 0.0 | 3.448080 | 8.787195 | 6.938605 | 88.556186 |
| min | 2015.0 | 1.000000 | 1.000000 | 0.000000 | 0.000000 |
| 25% | 2015.0 | 4.000000 | 8.000000 | 5.000000 | 21.000000 |
| 50% | 2015.0 | 7.000000 | 16.000000 | 11.000000 | 54.000000 |
| 75% | 2015.0 | 10.000000 | 23.000000 | 18.000000 | 109.000000 |
| max | 2015.0 | 12.000000 | 31.000000 | 23.000000 | 722.000000 |
另外,我们还要为数据集增加一个字段,根据前面表1-1的划分方法,把pm2.5的测量值Value,转换为空气质量等级。 首先,我们先写一个函数,通过pm2.5测量值对应的空气质量等级。
In [8]:
df_bj2015.describe()
Out[8]:
| Year | Month | Day | Hour | Value | |
|---|---|---|---|---|---|
| count | 8663.0 | 8663.000000 | 8663.000000 | 8663.000000 | 8663.000000 |
| mean | 2015.0 | 6.538728 | 15.674939 | 11.494055 | 82.733810 |
| std | 0.0 | 3.448080 | 8.787195 | 6.938605 | 88.556186 |
| min | 2015.0 | 1.000000 | 1.000000 | 0.000000 | 0.000000 |
| 25% | 2015.0 | 4.000000 | 8.000000 | 5.000000 | 21.000000 |
| 50% | 2015.0 | 7.000000 | 16.000000 | 11.000000 | 54.000000 |
| 75% | 2015.0 | 10.000000 | 23.000000 | 18.000000 | 109.000000 |
| max | 2015.0 | 12.000000 | 31.000000 | 23.000000 | 722.000000 |
def get_grade(value): if value <= 50 and value>=0: return 'Good' elif value <= 100: return 'Moderate' elif value <= 150: return 'Unhealthy for Sensi' elif value <= 200: return 'Unhealthy' elif value <= 300: return 'Very Unhealthy' elif value <= 500: return 'Hazardous' elif value > 500: return 'Beyond Index' # 爆表了 else: return None # 输入值无效
以下使用DataFrame的apply函数,增加一个字段‘Grade’,并且根据‘Value’字段的值,调用前面的转换函数,为‘Grade’字段赋值。
In [10]:
df_bj2015.loc[:, 'Grade'] = df_bj2015['Value'].apply(get_grade)
再来看看增加字段后的数据集
In [11]:
df_bj2015.head()
Out[11]:
| Year | Month | Day | Hour | Value | QC | Grade | |
|---|---|---|---|---|---|---|---|
| 0 | 2015 | 1 | 1 | 0 | 22.0 | Valid | Good |
| 1 | 2015 | 1 | 1 | 1 | 9.0 | Valid | Good |
| 2 | 2015 | 1 | 1 | 2 | 9.0 | Valid | Good |
| 3 | 2015 | 1 | 1 | 3 | 13.0 | Valid | Good |
| 4 | 2015 | 1 | 1 | 4 | 10.0 | Valid | Good |
In [12]:
# 从csv中读取北京2016年pm2.5数据,保存在DataFrame中
df_bj2016 = pd.read_csv('data/Beijing_2016_HourlyPM25_created20170201.csv')
# 重新设定各个字段的名称
df_bj2016.columns=['Year','Month','Day','Hour','Value','QC']
# 对错误和缺失值赋为空值
df_bj2016.loc[df_bj2016.Value<0,'Value']=np.nan
# 删除空值记录
df_bj2016.dropna(inplace=True)
#增加空气质量等级字段‘Grade’
df_bj2016.loc[:, 'Grade'] = df_bj2016['Value'].apply(get_grade)In [13]:
df_bj2016.head()
Out[13]:
| Year | Month | Day | Hour | Value | QC | Grade | |
|---|---|---|---|---|---|---|---|
| 0 | 2016 | 1 | 1 | 0 | 231.0 | Valid | Very Unhealthy |
| 1 | 2016 | 1 | 1 | 1 | 239.0 | Valid | Very Unhealthy |
| 2 | 2016 | 1 | 1 | 2 | 205.0 | Valid | Very Unhealthy |
| 3 | 2016 | 1 | 1 | 3 | 167.0 | Valid | Unhealthy |
| 4 | 2016 | 1 | 1 | 4 | 132.0 | Valid | Unhealthy for Sensi |
# 从csv中读取广州2016年pm2.5数据,保存在DataFrame中
df_gz2016 = pd.read_csv('data/Guangzhou_2016_HourlyPM25_created20170201.csv')
# 重新设定各个字段的名称
df_gz2016.columns=['Year','Month','Day','Hour','Value','QC']
# 对错误和缺失值赋为空值
df_gz2016.loc[df_gz2016.Value<0,'Value']=np.nan
# 删除空值记录
df_gz2016.dropna(inplace=True)
#增加空气质量等级字段‘Grade’
df_gz2016.loc[:, 'Grade'] = df_gz2016['Value'].apply(get_grade)In [15]:
df_gz2016.head()
Out[15]:
| Year | Month | Day | Hour | Value | QC | Grade | |
|---|---|---|---|---|---|---|---|
| 0 | 2016 | 1 | 1 | 0 | 55.0 | Valid | Moderate |
| 1 | 2016 | 1 | 1 | 1 | 58.0 | Valid | Moderate |
| 2 | 2016 | 1 | 1 | 2 | 59.0 | Valid | Moderate |
| 3 | 2016 | 1 | 1 | 3 | 58.0 | Valid | Moderate |
| 4 | 2016 | 1 | 1 | 4 | 51.0 | Valid | Moderate |
# 从csv中读取广州2015年pm2.5数据,保存在DataFrame中
df_gz2015 = pd.read_csv('data/Guangzhou_2015_HourlyPM25_created20160201.csv')
# 重新设定各个字段的名称
df_gz2015.columns=['Year','Month','Day','Hour','Value','QC']
# 对错误和缺失值赋为空值
df_gz2015.loc[df_gz2015.Value<0,'Value']=np.nan
# 删除空值记录
df_gz2015.dropna(inplace=True)
#增加空气质量等级字段‘Grade’
df_gz2015.loc[:, 'Grade'] = df_gz2015['Value'].apply(get_grade)In [17]:
df_gz2015.head()
Out[17]:
| Year | Month | Day | Hour | Value | QC | Grade | |
|---|---|---|---|---|---|---|---|
| 0 | 2015 | 1 | 1 | 0 | 38.0 | Valid | Good |
| 1 | 2015 | 1 | 1 | 1 | 40.0 | Valid | Good |
| 2 | 2015 | 1 | 1 | 2 | 40.0 | Valid | Good |
| 3 | 2015 | 1 | 1 | 3 | 34.0 | Valid | Good |
| 4 | 2015 | 1 | 1 | 4 | 42.0 | Valid | Good |
<未完待续>

相关文章推荐
- Python数据分析练习:北京、广州PM2.5空气质量分析(2)
- 【MOOC】Python数据分析与展示-北京理工大学-【第二周】数据分析之展示
- python数据分析与挖掘实战 第九章 拓展练习
- 《python数据分析与挖掘实战》-张良均等 源码code
- 互联网安全分析:Botnet,北京,中国,美国
- 【敏捷个人俱乐部-北京】及【免费敏捷结果线下练习】报名帖
- python数据分析基础0_NumPY
- Python数据分析——csv模块
- python基础练习(二)—— 数据分析包numpy数组操作
- 分析一天1000万北京地铁客流,我们发现...
- 算法设计与分析题目练习四:井字棋(启发式算法)
- 11.LinkedList部分源码分析与练习
- Python数据分析笔记
- 「机器学习」Python数据分析之Numpy
- 软件可行性分析报告的练习
- Matlab数据分析练习-平滑处理
- 广州、北京wlan免费体验指令
- c语言选择结构作业题练习分享第二部分(附答案、考点、难度、分析)
- 30天,App创业从0到1【北京、深圳、广州】
- 算法分析课每周练习 Find Median from Data Stream