使用tf.contrib.learn记录和监控基础知识
2017-08-16 12:06
513 查看
使用tf.contrib.learn记录和监控基础知识
培训模型时,实时跟踪和评估进度通常很有价值。在本教程中,您将学习如何使用TensorFlow的日志记录功能和MonitorAPI来对用于分类虹膜的神经网络分类器的进行中的训练进行审核。本教程基于tf.contrib.learn快速入门中开发的代码,因此如果您尚未完成该教程,您可能需要首先探索它,特别是如果您正在寻找tf.contrib.learn上的介绍/刷新基本。
建立
对于本教程,您将基于tf.contrib.learn快速入门的以下代码 :from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import numpy as np
import tensorflow as tf
# Data sets
IRIS_TRAINING = os.path.join(os.path.dirname(__file__), "iris_training.csv")
IRIS_TEST = os.path.join(os.path.dirname(__file__), "iris_test.csv")
def main(unused_argv):
# Load datasets.
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING, target_dtype=np.int, features_dtype=np.float32)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TEST, target_dtype=np.int, features_dtype=np.float32)
# Specify that all features have real-value data
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
# Build 3 layer DNN with 10, 20, 10 units respectively.
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model")
# Fit model.
classifier.fit(x=training_set.data,
y=training_set.target,
steps=2000)
# Evaluate accuracy.
accuracy_score = classifier.evaluate(x=test_set.data,
y=test_set.target)["accuracy"]
print('Accuracy: {0:f}'.format(accuracy_score))
# Classify two new flower samples.
new_samples = np.array(
[[6.4, 3.2, 4.5, 1.5], [5.8, 3.1, 5.0, 1.7]], dtype=float)
y = list(classifier.predict(new_samples, as_iterable=True))
print('Predictions: {}'.format(str(y)))
if __name__ == "__main__":
tf.app.run()将上述代码复制到文件中,并将相应的培训和 测试数据集下载 到同一目录。
在以下部分中,您将逐步更新上述代码以添加日志记录和监视功能。包含所有更新的最终代码可从这里下载。
概观
该tf.contrib.learn快速入门教程走通了如何实现一个神经网络分类器进行分类虹膜例子为三个品种之一。但是当本教程的代码运行时,输出不包含模型训练如何进行的记录跟踪
- 只
Accuracy: 0.933333 Predictions: [1 2]
没有任何记录,模特训练感觉像一个黑盒子; 您不能看到TensorFlow通过梯度下降步骤,了解模型是否正确收敛,或者审核以确定是否 提前停止可能是适当的。
解决这个问题的一种方法是将模型训练分成多个
fit步骤的多个 呼叫,以逐步评估准确性。然而,这不是推荐的做法,因为它大大减慢了模型训练。幸运的是,tf.contrib.learn提供了另一种解决方案:一个 Monitor
API,旨在帮助您在培训进行过程中记录指标并评估您的模型。在以下部分中,您将学习如何在TensorFlow中启用日志记录,设置ValidationMonitor进行流评估,并使用TensorBoard可视化您的指标。
使用TensorFlow启用日志记录
TensorFlow使用五个不同级别的日志消息。在上升的严重程度排列,分别是DEBUG,
INFO,
WARN,
ERROR,和
FATAL。当您在任何这些级别配置日志记录时,TensorFlow将输出与该级别相对应的所有日志消息以及所有级别的严重级别。例如,如果设置了日志记录级别
ERROR,则会收到包含日志输出
ERROR和
FATAL消息,如果设置了一个级别
DEBUG,则会从所有五个级别获取日志消息。
默认情况下,TensorFlow被配置在记录级别
WARN,但是当跟踪模型训练时,您将需要调整级别
INFO,这将在
fit操作正在进行时提供额外的反馈。
将以下行添加到代码的开头(紧随其后
import):
tf.logging.set_verbosity(tf.logging.INFO)
现在运行代码时,会看到如下所示的其他日志输出:
INFO:tensorflow:loss = 1.18812, step = 1 INFO:tensorflow:loss = 0.210323, step = 101 INFO:tensorflow:loss = 0.109025, step = 201
使用
INFO级别日志记录,tf.contrib.learn会在每100个步骤之后自动将训练损失指标输出到stderr。
配置验证监视器进行流评估
记录训练损失有助于了解您的模型是否收敛,但如果您想进一步了解培训中发生的情况怎么办?tf.contrib.learn提供了几个高级别,Monitor您可以附加到您的
fit操作,以进一步跟踪指标和/或调试模型培训期间的低级TensorFlow操作,包括:
| 监控 | 描述 |
|---|---|
CaptureVariable | 在训练的每n个步骤中将指定的变量的值保存到集合中 |
PrintTensor | 在训练的每n个步骤记录指定的张量值 |
SummarySaver | 在训练的每n个步骤中使用一个给定的张量来保存协议缓冲区tf.Summary tf.summary.FileWriter |
ValidationMonitor | 在训练的每n个步骤记录一组指定的评估指标,如果需要,在某些条件下实现提前停止 |
评估每N步
对于虹膜神经网络分类器,在记录训练损失时,您可能还需要同时对测试数据进行评估,以了解该模型的泛化程度。您可以通过配置ValidationMonitor测试数据(
test_set.data和
test_set.target)并设置通过评估的频率来实现此目的
every_n_steps。的默认值
every_n_steps就是
100; 这里,设定
every_n_steps为
50每50个步骤进行模型训练后评估:
validation_monitor = tf.contrib.learn.monitors.ValidationMonitor( test_set.data, test_set.target, every_n_steps=50)
将此代码放在实例化的行之前
classifier。
ValidationMonitor依靠保存的检查点执行评估操作,因此您需要修改
classifier添加
tf.contrib.learn.RunConfig包含的 实例化
save_checkpoints_secs,该参数指定在培训期间在检查点保存之间经过多少秒。由于虹膜数据集相当小,因此快速训练,设置
save_checkpoints_secs为1(每秒保存检查点)是有意义的,以确保足够数量的检查点:
classifier = tf.contrib.learn.DNNClassifier( feature_columns=feature_columns, hidden_units=[10, 20, 10], n_classes=3, model_dir="/tmp/iris_model", config=tf.contrib.learn.RunConfig(save_checkpoints_secs=1))
注意:该
model_dir参数指定
/tmp/iris_model要存储的模型数据的显式目录(); 这个目录路径比以前更容易引用,而不是自动生成的。每次运行代码时,任何现有的数据
/tmp/iris_model将被加载,并且模型训练将在上一次运行中停止运行(例如,在每个
fit操作期间连续运行脚本两次将在训练期间执行4000个步骤 )。从头开始模型训练,
/tmp/iris_model在运行代码之前删除 。
最后,要附加您的
validation_monitor更新
fit呼叫以包括一个
monitors参数,该参数需要在模型训练期间运行的所有显示器列表:
classifier.fit(x=training_set.data, y=training_set.target, steps=2000, monitors=[validation_monitor])
现在,当您重新运行代码时,您应该在日志输出中看到验证度量,例如:
INFO:tensorflow:Validation (step 50): loss = 1.71139, global_step = 0, accuracy = 0.266667 ... INFO:tensorflow:Validation (step 300): loss = 0.0714158, global_step = 268, accuracy = 0.966667 ... INFO:tensorflow:Validation (step 1750): loss = 0.0574449, global_step = 1729, accuracy = 0.966667
使用MetricSpec定制评估指标
默认情况下,如果未指定评估指标,ValidationMonitor则会记录丢失和准确性,但您可以自定义将每50个步骤运行的指标列表。要在每个评估通行证中指定要运行的确切指标,可以
metrics向
ValidationMonitor构造函数添加一个 参数。
metrics采用键/值对的指令,其中每个键是您要为度量标准记录的名称,相应的值是一个
MetricSpec对象。
该
MetricSpec构造函数接受四个参数:
metric_fn。计算和返回指标值的函数。这可以是
tf.contrib.metrics模块中可用的预定义功能 ,例如
tf.contrib.metrics.streaming_precision或
tf.contrib.metrics.streaming_recall。
或者,您可以定义自己的自定义度量函数,它们必须采用
predictions和
labels张量作为参数(
weights也可以选择提供参数)。该函数必须以两种格式之一返回度量值:
一张张量
一对操作
(value_op, update_op),
value_op返回度量值并
update_op执行相应的操作来更新内部模型状态。
prediction_key。包含模型返回的预测的张量的关键。如果模型返回单个张量或具有单个条目的dict,则可以省略此参数。对于一个
DNNClassifier模型,类预测将以关键的张量返回
tf.contrib.learn.PredictionKey.CLASSES。
label_key。包含模型返回的标签的张量的关键字,由模型指定
input_fn。与
prediction_key此相反,如果
input_fn返回单个张量或具有单个条目的dict,则可以省略此参数。在本教程的虹膜示例中,
DNNClassifier没有
input_fn(
x,
y数据直接传递给
fit),因此没有必要提供
label_key。
weights_key。可选。张量的关键(返回
input_fn)包含重量输入
metric_fn。
以下代码创建一个
validation_metrics在模型评估期间定义要记录的三个指标的dict:
"accuracy",
tf.contrib.metrics.streaming_accuracy用作
metric_fn
"precision",
tf.contrib.metrics.streaming_precision用作
metric_fn
"recall",
tf.contrib.metrics.streaming_recall用作
metric_fn
validation_metrics = {
"accuracy":
tf.contrib.learn.MetricSpec(
metric_fn=tf.contrib.metrics.streaming_accuracy,
prediction_key=tf.contrib.learn.PredictionKey.CLASSES),
"precision":
tf.contrib.learn.MetricSpec(
metric_fn=tf.contrib.metrics.streaming_precision,
prediction_key=tf.contrib.learn.PredictionKey.CLASSES),
"recall":
tf.contrib.learn.MetricSpec(
metric_fn=tf.contrib.metrics.streaming_recall,
prediction_key=tf.contrib.learn.PredictionKey.CLASSES)
}在
ValidationMonitor构造函数之前添加上面的代码。然后
ValidationMonitor按照以下方式修改 构造函数,添加一个
metrics参数以记录指定的精度,精度和调用度量
validation_metrics(损失始终记录,不需要明确指定):
validation_monitor = tf.contrib.learn.monitors.ValidationMonitor( test_set.data, test_set.target, every_n_steps=50, metrics=validation_metrics)
重新运行代码,您应该看到日志输出中包含的精度和回调,例如:
INFO:tensorflow:Validation (step 50): recall = 0.0, loss = 1.20626, global_step = 1, precision = 0.0, accuracy = 0.266667 ... INFO:tensorflow:Validation (step 600): recall = 1.0, loss = 0.0530696, global_step = 571, precision = 1.0, accuracy = 0.966667 ... INFO:tensorflow:Validation (step 1500): recall = 1.0, loss = 0.0617403, global_step = 1452, precision = 1.0, accuracy = 0.966667
早期停止与验证监视器
注意,在上述日志输出中,通过步骤600,该模型已经实现了1.0的精确和回调率。这提出了模型训练是否可以从早期停止中受益的问题 。除了记录eval指标之外,
ValidationMonitor还可以通过三个参数来轻松实现提前停止指定条件:
| 帕拉姆 | 描述 |
|---|---|
early_stopping_metric | 度量触发在特定条件下提前停止(例如,丢失或精度)early_stopping_rounds和 early_stopping_metric_minimize。默认是 "loss"。 |
early_stopping_metric_minimize | True如果需要,模型行为是最小化的值 early_stopping_metric; False如果需要,模型行为是最大化的价值 early_stopping_metric。默认是 True。 |
early_stopping_rounds | 设置了若干步骤,在此期间,如果early_stopping_metric不减少(如果 early_stopping_metric_minimize是 True)或增加(如果 early_stopping_metric_minimize是 False),培训将被停止。默认是 None,这意味着早期停止将永远不会发生。 |
ValidationMonitor构造函数进行以下修订,其中指定如果在200步()期间loss(
early_stopping_metric="loss")不减少
early_stopping_metric_minimize=True(
early_stopping_rounds=200),则模型训练将在该点立即停止,并且不完成以下指定的完整的2000个步骤
fit:
validation_monitor = tf.contrib.learn.monitors.ValidationMonitor( test_set.data, test_set.target, every_n_steps=50, metrics=validation_metrics, early_stopping_metric="loss", early_stopping_metric_minimize=True, early_stopping_rounds=200)
重新运行代码,看看模型训练是否早点停止:
... INFO:tensorflow:Validation (step 1150): recall = 1.0, loss = 0.056436, global_step = 1119, precision = 1.0, accuracy = 0.966667 INFO:tensorflow:Stopping. Best step: 800 with loss = 0.048313818872.
实际上,这里的训练在步骤1150停止,表明在过去的200个步骤中,损失没有减少,而总的来说,步骤800相对于测试数据集产生最小的损失值。这表明通过减少步数可以进一步改进模型,进一步校准超参数。
用TensorBoard可视化日志数据
阅读通过ValidationMonitor在培训期间提供大量关于模型性能的原始数据的日志,但也可能有助于查看此数据的可视化,以进一步了解趋势,例如准确性如何随着步数而变化。您可以使用TensorBoard(TensorFlow打包的单独程序)通过将
logdir命令行参数设置为保存模型训练数据的目录(此处)来绘制图形
/tmp/iris_model。在命令行上运行以下命令:
$ tensorboard --logdir = / tmp / iris_model /
在端口6006上启动TensorBoard 39
然后
http://0.0.0.0:
<port_number>在浏览器中 导航到
<port_number>命令行输出中指定的端口(在这里
6006)。
如果您点击准确性字段,您将看到如下图像,其中显示了相对于步数计算的精度:
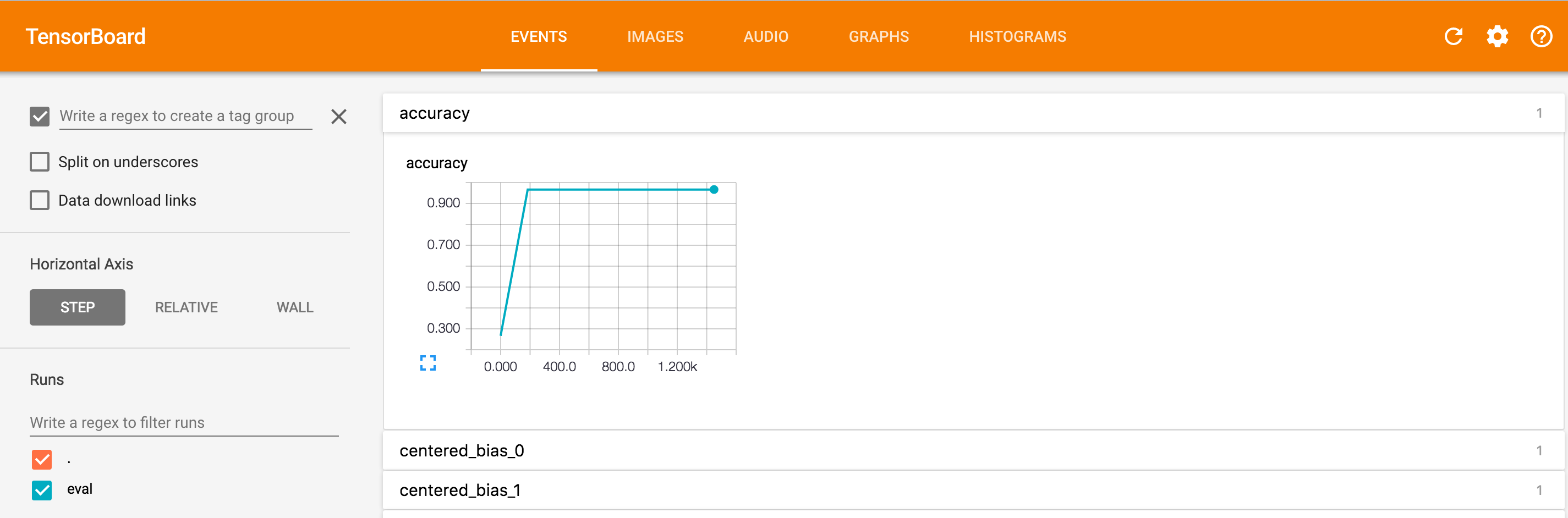
有关使用TensorBoard的更多信息,请参阅TensorBoard:可视化学习和TensorBoard:图形可视化。

相关文章推荐
- learn opencv- 深度学习使用Keras - 基础知识
- TensorFlow高级API(tf.contrib.learn)及可视化工具TensorBoard的使用
- 学习使用tf.contrib.learn框架开发机器学习程序
- 使用tf.contrib.learn构建输入函数
- TensorFlow高级API(tf.contrib.learn)及可视化工具TensorBoard的使用
- ftrace基础知识学习+使用实例 (仅作学习记录)
- ASP.NET2.0中使用数据源控件之基础知识
- SQL Server 索引基础知识(1)--- 记录数据的基本格式
- memcached系列之1:memcached基础知识简介(为什么要使用memcached做缓存服务器)
- SQL Server 索引基础知识(6)----索引的代价,使用场景
- SQL Server 索引基础知识(1)--- 记录数据的基本格式(转自蝈蝈俊.net)
- memcached系列之1:memcached基础知识简介(为什么要使用memcached做缓存服务器)
- Linux基础知识--(04)使用虚拟机安装CentOS 5.3
- memcached系列之1:memcached基础知识简介(为什么要使用memcached做缓存服务器)
- SQL Server 索引基础知识(6)----索引的代价,使用场景(转自蝈蝈俊.net)
- 使用Aspose.Cells的基础知识整理
- SQL Server 索引基础知识(6)----索引的代价,使用场景
- 使用Forms Authentication实现用户注册、登录 (一)基础知识
- SQL Server 索引基础知识(1)--- 记录数据的基本格式 (转)
- XML基础知识学习八(使用XSL来显示XML数据)