机器学习笔记3:支持向量机的SMO高效优化算法
2017-08-15 19:54
861 查看
机器学习笔记3:支持向量机的SMO高效优化算法
1. SMO算法背景
根据上一篇的支持向量机SVM的基础知识介绍,算法的根本目标就是实现对优化目标函数在约束条件下的求解问题。SMO算法表示序列最小优化(Sequential Minimal Optimization),将大优化问题分解为多个小优化问题来求解,小优化问题便于求解,同时对它们进行顺序求解的结果与作为整体求解的结果完全一致,并且SMO算法的求解时间要短很多。SMO算法的目标就是求出一系列的alpha与b,一旦求出这些alpha,就很容易计算出权重向量w并得到分隔超平面。
SMO算法的工作原理是:每次循环中选择两个alpha,增大其中的一个同时减少另外一个,所谓的合适就是两个alpha符合一定的条件,条件之一就是两个alpha必须要在间隔边界之外,而第二个条件则是这两个alpha还没有进行过区间化处理或者不在边界上。
2.简化版SMO算法处理小规模数据集
简化版的SMO算法虽然执行速度较慢,Platt SMO算法中的外循环确定要优化的最佳alpha对,简化版跳过了这个部分,简化版的SMO算法首先在数据集上遍历每一个alpha,然后在剩下的alpha集合中随机选择另一个alpha,从而建立alpha对。这一点非常重要,同时改变两个alpha,因为我们有一个约束条件: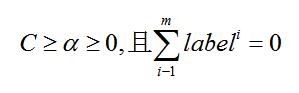
由于改变一个alpha可能会导致该约束条件失效,因此我们同时改变两个alpha。因此,代码整体如下,部分重要部分进行注释。
# coding=utf-8
'''
Date: August 14 2017
Author:Chenhao
Description: simplified SMO Algorithm
'''
from numpy import *
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
#读取文档内数据,数据格式为三列,前两列包含二维数据,第三列为label
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
#用于在区间范围内选择一个整数
#输入函数i代表第一个alpha的下标,m是所有alpha的数目
def selectJrand(i,m):
j=i #we want to select any J not equal to i
while (j==i):
j = int(random.uniform(0,m))
return j
#用于在数值太大的情况下进行调整
#用于调整大于H小于L的alpha值
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
#简化版的SMO算法
def smoSimple(dataMatIn, classLabels, C, toler, maxIter): #五个输入参数对应表示数据集,类别标签,常数C,容错率,退出前最大循环次数
dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose() #将输入数据转化为matrix的形式,将类别标签进行转置
b = 0; m,n = shape(dataMatrix) #将常数b进行初始化,m,n分别表示数据集的行和列
alphas = mat(zeros((m,1))) #将alpha初始化为m行1列的全零矩阵
iter = 0 #该变量用于存储是在没有任何alpha改变的情况下遍历数据集的次数
while (iter < maxIter): #当遍历数据集的次数超过设定的最大次数后退出循环
alphaPairsChanged = 0 #该参数用于记录alpha是否已进行优化,每次循环先将其设为0
for i in range(m): #将数据集中的每一行进行测试
#multiply是numpy中的运算形式,将alpha与标签相乘的结果的转置与对应行的数据相乘再加b
#fxi表示将该点带入后进行计算得到的预测的类别,若Ei=0,则该点就在回归线上
fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i])#if checks if an example violates KKT conditions
#label[i]*Ei代表误差,如果误差很大可以根据对应的alpha值进行优化,同时检查alpha值使其不能等于0或C
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i,m) #随机选取另外一个数作为j,也就是选取另外一行数据
fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat[j]) #采用与上述相同的方式来计算j行的预测误差
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy(); #暂存变量,便于后面对其进行比对
#调整H与L的数值,便于用来控制alpha的范围
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L==H: print "L==H"; continue #continue在python中代表本次循环结束直接运行下一次循环
#eta代表的是alphas[j]的最优修改量,如果eta大于等于0则需要退出for循环的当前迭代过程
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
if eta >= 0: print "eta>=0"; continue
#给alphas[j]赋新值,同时控制alphas[j]的范围在H与L之间
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
alphas[j] = clipAlpha(alphas[j],H,L)
#然后检查alphas[j]是否有轻微改变,如改变很小,就进行下一次循环
if (abs(alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; continue
#将alpha[i]与alpha[j]同时进行改变,改变的数值保持一致,但是改变的方向相反
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
#在完成alpha[i]与alpha[j]的优化之后,给这两个alpha设置一个常数项b
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
if (0 < alphas[i]) and (C > alphas[i]): b = b1
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
else: b = (b1 + b2)/2.0
alphaPairsChanged += 1 #该参数用于记录alpha是否已进行优化
print "iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged) #iter表示遍历的次数
if (alphaPairsChanged == 0): iter += 1
else: iter = 0
print "iteration number: %d" % iter
return b,alphas
def plot():
dataplot = array(dataArr)
n = shape(dataplot)[0]
plotx1 = []; ploty1 = []
plotx2 = []; ploty2 = []
for i in range(n):
if int(labelArr[i]) == 1:
plotx1.append(dataplot[i,0])
ploty1.append(dataplot[i,1])
else:
plotx2.append(dataplot[i, 0])
ploty2.append(dataplot[i, 1])
fig = plt.figure()
ax =fig.add_subplot(111)
ax.scatter(plotx1,ploty1,c='red')
ax.scatter(plotx2,ploty2,c='blue')
plt.show()
dataArr,labelArr = loadDataSet('testSet.txt')
b,alphas = smoSimple(dataArr,labelArr,0.6,0.001,40)
for i in range(100):
if alphas[i]>0.0:
print dataArr[i],labelArr[i]
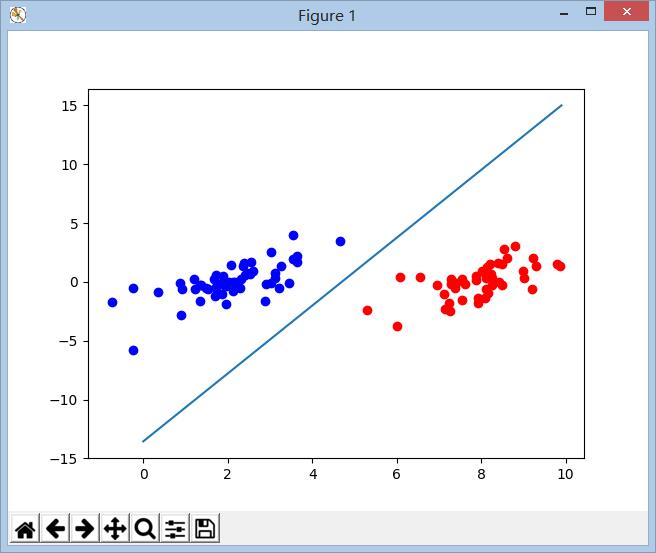
plot()代码运行结果如下:
在alpha大于零的前提下的数据及其label:
[4.658191, 3.507396] -1.0
[3.457096, -0.082216] -1.0
[2.893743, -1.643468] -1.0
[6.080573, 0.418886] 1.0
3.利用完整的Platt SMO算法加速优化
上述的简化版SMO算法在几百个点的小规模数据集上运行是没有问题的,但是在更大的数据集上运行就会导致运行速度变慢。完整版的Platt SMO算法在实现alpha的更改和代数运算的优化环节与简化版的SMO算法一模一样,唯一不同的就是选择alpha方式。Platt SMO算法是通过一个外循环来选择第一个alpha值的,并且其选择过程会在两种方式之间交替:一种方式是在所有数据集上进行单遍扫描,另一种方式则是在非边界alpha中实现单遍扫描,所谓非边界alpha指的是那些不等于边界0或C的alpha值。对整个数据集的扫描相当容易,二实现非边界alpha值的扫描时,首先需要建立这些alpha值的列表,然后对这个表进行遍历。同时,该步骤会跳过那些已知不变的alpha值。
在选择第一个alpha值后,算法会通过一个内循环来选择第二个alpha值,在优化过程中,会通过最大化步长的方式来获得第二个alpha值,在简化版的SMO算法中,我们会在选择j之后计算错误率Ej。但是在这里,我们会建立一个全局的缓存用于保存误差值,并从中选择步长或者说是Ei-Ej最大的alpha值。
下面是在使用Platt SMO算法前需要准备的用于清理代码的数据结构和3个用于对于E进行缓存的辅助函数。前面的数据结构以及辅助函数如下:
# coding=utf-8 #建立一个全局的数据结构用来保存所有重要的数值 #将数据转移到一个结构来实现,省去手工输入麻烦 class optStruct: def __init__(self,dataMatIn, classLabels, C, toler): # Initialize the structure with the parameters self.X = dataMatIn self.labelMat = classLabels self.C = C self.tol = toler #最大循环次数 #m表示数据的行数 self.m = shape(dataMatIn)[0] #初始化为m行1列的全零矩阵 self.alphas = mat(zeros((self.m,1))) self.b = 0 #eCache的第一列表示是否有效的标志位,第二列是实际E值 self.eCache = mat(zeros((self.m,2))) #first column is valid flag #该函数用来计算E值并返回 #k可以表示i或者j的数值 def calcEk(oS, k): fXk = float(multiply(oS.alphas, oS.labelMat).T * (oS.X*oS.X[k,:].T)) + oS.b Ek = fXk - float(oS.labelMat[k]) #数据点代入alpha和b后的值与真实标签的差值表示Ek return Ek #该函数用于选择第二个alpha值或者说是内循环的alpha值,保证每次循环采用最大步长 def selectJ(i, oS, Ei): # this is the second choice -heurstic, and calcs Ej maxK = -1; maxDeltaE = 0; Ej = 0 oS.eCache[i] = [1, Ei] # 将eCache的第一列数据也就是标志位设置为有效,接下来选择合适的alpha使得步长也就是Ei-Ej最大 #构建出一个非零表 validEcacheList = nonzero(oS.eCache[:, 0].A)[0] #将eCache的标志位到处存入到validECacheList中 if (len(validEcacheList)) > 1: for k in validEcacheList: #通过eCache的有效标志位作为判断依据进行循环找到满足步长最大化的alpha if k == i: continue #如果k等于i,跳出循环,避免浪费时间 Ek = calcEk(oS, k) deltaE = abs(Ei - Ek) if (deltaE > maxDeltaE): maxK = k; maxDeltaE = deltaE; Ej = Ek return maxK, Ej else: #这种情况是在第一次循环过程中eCache没有有效值,就采用遍历数据集的方式 j = selectJrand(i, oS.m) Ej = calcEk(oS, j) return j, Ej #将计算误差值缓存到alpha值进行优化之后会用到 def updateEk(oS, k): # after any alpha has changed update the new value in the cache Ek = calcEk(oS, k) oS.eCache[k] = [1, Ek]
各个函数及其解释如上代码片,上面的全局变量的定义及其三个辅助函数的构建目的是为了便于Platt SMO算法的高效执行,下面是完整的Platt SMO算法及其注释。
#Platt SMO算法的内循环部分,确定第二个alpha的值
def innerL(i, oS):
Ei = calcEk(oS, i) #计算第i组数据的误差
#如果计算得到的误差在允许范围之内时
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
#selectJ函数用来选择第二个alpha值来保证步长得到最大
j,Ej = selectJ(i, oS, Ei)
#将alphai与alphaj的旧值存储
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
# 调整H与L的数值,便于用来控制alpha的范围
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print "L==H"; return 0 #如果L=H时,则返回0
# eta代表的是alphas[j]的最优修改量,如果eta大于等于0则需要退出for循环的当前迭代过程
eta = 2.0 * oS.X[i,:]*oS.X[j,:].T - oS.X[i,:]*oS.X[i,:].T - oS.X[j,:]*oS.X[j,:].T
if eta >= 0: print "eta>=0"; return 0
# 计算alphaj的数值,给alphas[j]赋新值,同时控制alphas[j]的范围在H与L之间
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
# 将计算误差进行缓存,便于后面用到
updateEk(oS, j) #added this for the Ecache
# 然后检查alphas[j]是否有轻微改变,如改变很小,就进行下一次循环
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; return 0
# 将alpha[i]与alpha[j]同时进行改变,改变的数值保持一致,但是改变的方向相反
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#update i by the same amount as j
#将Ek存入缓存
updateEk(oS, i) #added this for the Ecache #the update is in the oppostie direction
# 在完成alpha[i]与alpha[j]的优化之后,给这两个alpha设置一个常数项b
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[i,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[i,:]*oS.X[j,:].T
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[j,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[j,:]*oS.X[j,:].T
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else: return 0
#选择第一个Alpha值的外循环
#五个输入参数对应表示数据集,类别标签,常数C,容错率,退出前最大循环次数
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)): #full Platt SMO
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler)
iter = 0 #该变量用于存储是在没有任何alpha改变的情况下遍历数据集的次数
entireSet = True
# 该参数用于记录alpha是否已进行优化,每次循环先将其设为0
alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #go over all
for i in range(oS.m): #开始的for循环在数据集上遍历任意可能的alpha
alphaPairsChanged += innerL(i,oS) #用innerL来选择第二个alpha
print "fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0] #遍历非边界值
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS) #遍历非边界值来确定第二个alpha
print "non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
if entireSet: entireSet = False #toggle entire set loop
elif (alphaPairsChanged == 0): entireSet = True
print "iteration number: %d" % iter
return oS.b,oS.alphas部分运行结果如下:
fullSet, iter: 0 i:0, pairs changed 1
fullSet, iter: 0 i:1, pairs changed 1
fullSet, iter: 0 i:2, pairs changed 1
fullSet, iter: 0 i:3, pairs changed 1
fullSet, iter: 0 i:4, pairs changed 1
…
…(省略一部分)
fullSet, iter: 2 i:94, pairs changed 0
fullSet, iter: 2 i:95, pairs changed 0
fullSet, iter: 2 i:96, pairs changed 0
fullSet, iter: 2 i:97, pairs changed 0
fullSet, iter: 2 i:98, pairs changed 0
fullSet, iter: 2 i:99, pairs changed 0
iteration number: 3
在完成了alpha的计算过程之后,需要通过alpha来计算得到w才可以得到分隔超平面。下面的函数就实现了w的计算。
def calcWs(alphas,dataArr,classLabels): X = mat(dataArr) labelMat = mat(classLabels).transpose() m,n = shape(X) w = zeros((n,1)) for i in range(m): w += multiply(alphas[i]*labelMat[i],X[i,:].T) return w
我们可以添加如下代码,来用第一行数据作为验证。
dataArr,labelArr = loadDataSet('testSet.txt')
b,alphas = smoP(dataArr, labelArr , 0.6 , 0.001 , 40 )
ws = calcWs(alphas,dataArr,labelArr)
print ws
datMat = mat(dataArr)
test = datMat[0]*mat(ws)+b
print test结果如下所示:
ws = [[ 0.65307162]
* [-0.17196128]]*
test = [[-0.92555695]]
第一个label是-1,因此符合验证的结果。进一步的,可以添加代码,将数据及其分隔平面展示出来。
def plot():
dataplot = array(dataArr)
n = shape(dataplot)[0]
plotx1 = []; ploty1 = []
plotx2 = []; ploty2 = []
for i in range(n):
if int(labelArr[i]) == 1:
plotx1.append(dataplot[i,0])
ploty1.append(dataplot[i,1])
else:
plotx2.append(dataplot[i, 0])
ploty2.append(dataplot[i, 1])
fig = plt.figure()
ax =fig.add_subplot(111)
ax.scatter(plotx1,ploty1,c='red')
ax.scatter(plotx2,ploty2,c='blue')
plotx = arange(0.0 , 10.0 , 0.1)
ploty = -(ws_float0*plotx+ b_float)/ws_float1
ax.plot(plotx,ploty)
plt.show()
dataArr,labelArr = loadDataSet('testSet.txt')
b,alphas = smoP(dataArr, labelArr , 0.6 , 0.001 , 40 )
ws = calcWs(alphas,dataArr,labelArr)
print ws
datMat = mat(dataArr)
b_float = float(b[0])
ws_float0 = float(ws[0])
ws_float1 = float(ws[1])
test = datMat[1]*mat(ws)+b
print test
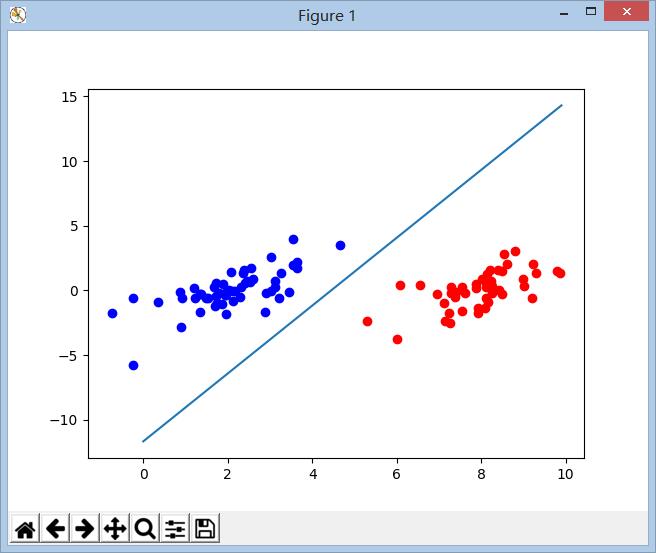
plot()最终分隔的结果如下图所示:
项目的完整代码以及数据源已经上传到我的github上,其中SMO.py是简化版的SMO算法,Platt SMO.py是SMO完整版的算法,就实验结果来看,二者算法的运算速度差距很大,结果在这个实验中差距不大,后面将会用SVM中的算法与核函数原理进行数据预测来验证这个算法的有效性。
项目数据与源代码
August 17 , 2017

相关文章推荐
- 【机器学习】支持向量机(SVM)的优化算法——序列最小优化算法(SMO)概述
- 【机器学习】支持向量机(二)——序列最小最优化(SMO)算法
- 机器学习-python通过序列最小优化算法(SMO)方法编写支持向量机(SVM)
- 七月算法机器学习笔记6 -- 工作流程与模型优化
- 机器学习之支持向量机SVM Support Vector Machine (四) SMO算法
- [机器学习]支持向量机及其应用---手写识别系统(SMO算法)
- 机器学习笔记_ 数值最优化_2:最优化算法
- 机器学习(九):CS229ML课程笔记(5)——支持向量机(SVM),最优间隔分类,拉格朗日对偶性,坐标上升法,SMO
- 机器学习笔记八 - SVM(Support Vector Machine,支持向量机)的剩余部分。即核技法、软间隔分类器、对SVM求解的序列最小化算法以及SVM的一些应用
- 【机器学习笔记】SVM part2: 核函数与SMO算法
- 七月算法机器学习笔记4 凸优化
- 机器学习(七、八):SVM(支持向量机)【最优间隔分类、顺序最小优化算法】
- 王小草【机器学习】笔记--无监督算法之聚类
- 机器学习实战笔记——利用KNN算法改进约会网站的配对效果
- 机器学习笔记KNN算法
- [机器学习]机器学习笔记整理07- KNN算法
- 机器学习整理笔记——使用k-近邻算法对手写识别系统的测试
- 机器学习笔记——支持向量机(IV)软间隔
- 【机器学习笔记之四】Adaboost 算法
- 机器学习实战笔记-利用AdaBoost元算法提高分类性能