跟我一起hadoop(1)-hadoop2.6安装与使用
2017-08-12 16:24
253 查看
http://www.cnblogs.com/skyme/p/4606138.html
伪分布式
hadoop的三种安装方式:Local (Standalone) Mode
Pseudo-Distributed Mode
Fully-Distributed Mode
安装之前需要
$ sudo apt-get install ssh$ sudo apt-get install rsync
详见:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
伪分布式配置
Configuration修改下边:
etc/hadoop/core-site.xml:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
etc/hadoop/hdfs-site.xml:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
配置ssh
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
如果想运行在yarn上
需要执行下边的步骤:
Configure parameters as follows:
etc/hadoop/mapred-site.xml:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
etc/hadoop/yarn-site.xml:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
Start ResourceManager daemon and NodeManager daemon:
$ sbin/start-yarn.sh
Browse the web interface for the ResourceManager; by default it is available at:
ResourceManager - http://localhost:8088/
Run a MapReduce job.
When you're done, stop the daemons with:
$ sbin/stop-yarn.sh
输入:
http://localhost:8088/
可以看到

启动yarn后
Format the filesystem:
$ bin/hdfs namenode -format
Start NameNode daemon and DataNode daemon:
$ sbin/start-dfs.sh
The hadoop daemon log output is written to the $HADOOP_LOG_DIR directory (defaults to
$HADOOP_HOME/logs).
Browse the web interface for the NameNode; by default it is available at:
NameNode - http://localhost:50070/
输入后得到:
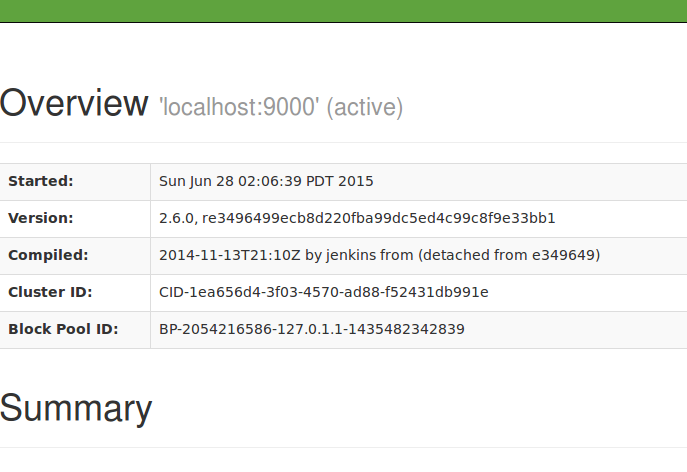
然后执行测试
Make the HDFS directories required to execute MapReduce jobs:
$ bin/hdfs dfs -mkdir /user $ bin/hdfs dfs -mkdir /user/<username>
Copy the input files into the distributed filesystem:
$ bin/hdfs dfs -put etc/hadoop input
Run some of the examples provided:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep input output 'dfs[a-z.]+'
Examine the output files:
Copy the output files from the distributed filesystem to the local filesystem and examine them:
$ bin/hdfs dfs -get output output $ cat output/*
or
View the output files on the distributed filesystem:
$ bin/hdfs dfs -cat output/*
看运行的情况:
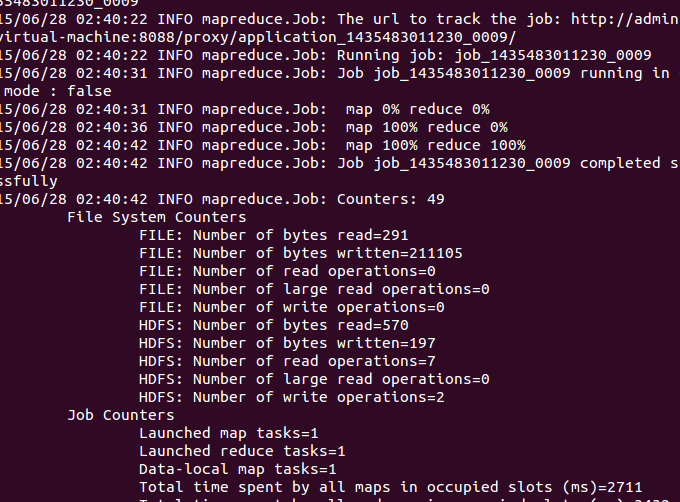
查看结果
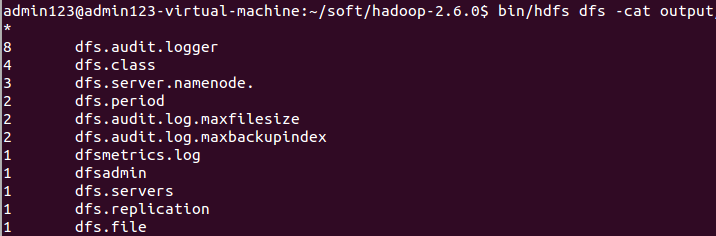
测试执行成功,可以编写本地代码了。
eclipse hadoop2.6插件使用
下载源码:git clone https://github.com/winghc/hadoop2x-eclipse-plugin.git
下载过程:

编译插件:
cd src/contrib/eclipse-plugin
ant jar -Dversion=2.6.0 -Declipse.home=/usr/local/eclipse -Dhadoop.home=/usr/local/hadoop-2.6.0 //路径根据自己的配置
复制编译好的jar到eclipse插件目录,重启eclipse
配置 hadoop 安装目录
window ->preference -> hadoop Map/Reduce -> Hadoop installation directory
配置Map/Reduce 视图
window ->Open Perspective -> other->Map/Reduce -> 点击“OK”
windows → show view → other->Map/Reduce Locations-> 点击“OK”
控制台会多出一个“Map/Reduce Locations”的Tab页
在“Map/Reduce Locations” Tab页 点击图标<大象+>或者在空白的地方右键,选择“New Hadoop location…”,弹出对话框“New hadoop location…”,配置如下内容:将ha1改为自己的hadoop用户

注意:MR Master和DFS Master配置必须和mapred-site.xml和core-site.xml等配置文件一致。
打开Project Explorer,查看HDFS文件系统。
新建Map/Reduce任务
File->New->project->Map/Reduce Project->Next
编写WordCount类:记得先把服务都起来
/**
*
*/
package com.zongtui;
/**
* ClassName: WordCount <br/>
* Function: TODO ADD FUNCTION. <br/>
* date: Jun 28, 2015 5:34:18 AM <br/>
*
* @author zhangfeng
* @version
* @since JDK 1.7
*/
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount {
public static class Map extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}user/admin123/input/hadoop是你上传在hdfs的文件夹(自己创建),里面放要处理的文件。ouput1放输出结果
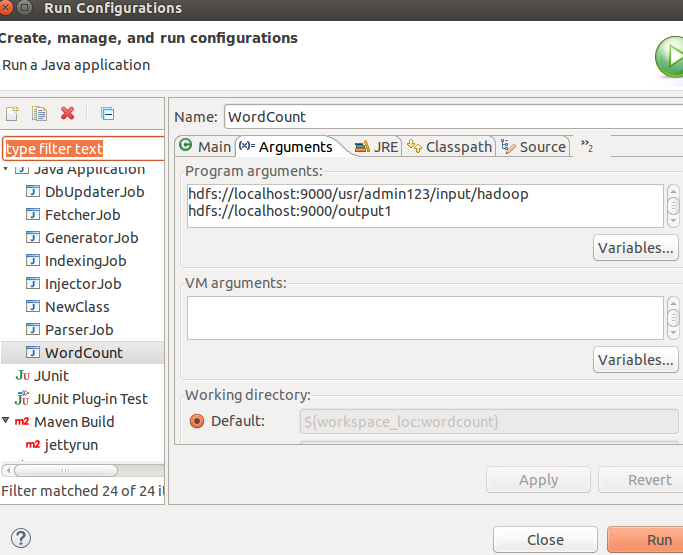
将程序放在hadoop集群上运行:右键-->Runas -->Run on Hadoop,最终的输出结果会在HDFS相应的文件夹下显示。至此,ubuntu下hadoop-2.6.0 eclipse插件配置完成。
遇到异常
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/output already exists at org.apache.hadoop.mapred.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:132) at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:564) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:432) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293) at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:562) at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:557) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:557) at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:548) at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:833) at com.zongtui.WordCount.main(WordCount.java:83)
1、改变输出路径。
2、删除重新建。
运行完成后看结果:
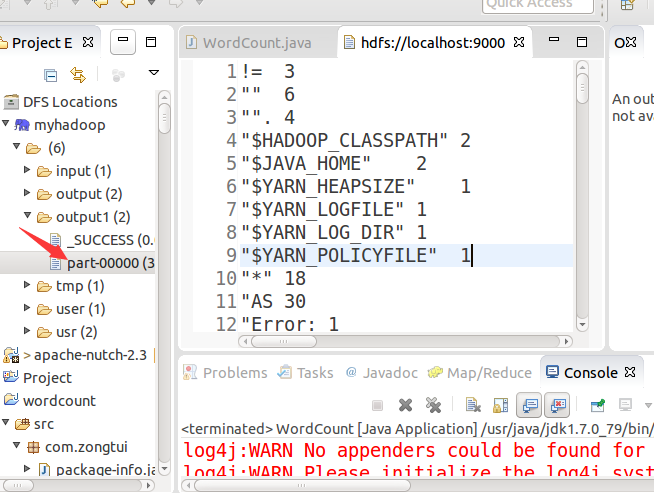

相关文章推荐
- 跟我一起hadoop的(1)-hadoop2.6安装与使用
- 跟我一起hadoop(1)-hadoop2.6安装与使用
- Hadoop2.6+jdk8的安装部署(1)——使用jar包安装部署【详细】
- hadoop2.6伪分布式安装和使用(centos7)
- Hadoop2.6+jdk8的安装部署(1)——使用jar包安装部署【详细】
- hadoop学习--安装使用
- 在VMWare Workstation上使用RedHat Linux安装和配置Hadoop群集环境01_虚拟机的安装
- hadoop工具hive安装使用
- hadoop-0.20.2安装及简单使用
- hadoop安装配置:使用cloudrea
- 使用FreeBSD的ports安装hadoop
- [置顶] CentOS 安装 hadoop hbase 使用 cloudera 版本。(一)
- 配置文件、虚拟机-如何使用vagrant在虚拟机安装hadoop集群-by小雨
- hadoop-0.20.2安装及简单使用 ubuntu
- VMware中使用CentOS安装并测试Hadoop
- 如何使用vagrant在虚拟机安装hadoop集群
- 如何使用vagrant在虚拟机安装hadoop集群
- VMWare Workstation上使用RedHat Linux安装和配置Hadoop群集环境03_配置虚拟机之间SSH无密码登录
- 在VMWare Workstation上使用RedHat Linux安装和配置Hadoop群集环境03_配置虚拟机之间SSH无密码登录
- hadoop安装及使用