Apache Kafka源码剖析:第1篇 网络引擎漫谈(类比法)
2017-08-11 00:00
351 查看
摘要: http://blog.csdn.net/it_man/article/details/21593187 讲了如何利用消息队列来解决分布式事务!
从这一篇开始,我们来研究kafka的网络引擎的源码。
==========================================
开始介绍kafka服务端之前,先从整体上了解架构。
本章会详细介绍每个组件的功能和实现!
网络层
如果以前看过网上的文章,就知道kafka的客户端会跟服务端的多个broker建立网络连接。
通过这些 socket连接传递各种信息,从而实现c/s交互!
客户端一般情况下不会碰到大数据量访问。
服务端则不同,面对高并发、低延迟的需求,Kafka服务端使用Reactor模式实现其网络层。
这一层不仅仅要管理producer,consumer,还要管理来自其它broker的连接(想一想为什么? :)
---Reactor模式
好,聊到reactor模式,那么这个到底是啥玩意?
那么,具体要怎么实现呢?
1)读取配置文件,生成listening socket,产生监听套接字,然后注册OP_ACCEPT事件到selector上
注意,针对监听套接字的可读,就是有client socket连接进来导致acceptable事件 :)
一般是启动1个Acceptor线程来处理这种事件
2)一旦有连接过来,服务端的Selector监听到此事件,触发accept事件。
3)创建socketChannel,设置为非阻塞模式,在别的selector上注册I/O事件
(其实这里才是Reactor事件的核心,利用Linux内核的机制高效监听各种socket可以操作的事件,不会造成浪费!!! socket设置为非阻塞模式也正是因为此!)
4)当客户端发送消息时,服务端的Selector监听到OP_READ事件,触发执行相应的处理逻辑。
当服务端可以写时,服务端监听到OP_WRITE事件,触发执行相应的处理逻辑。
---
这里涉及到3种事情,ACCEPT,IO处理,业务处理,涉及到几种线程呢?
redis因为内存操作的特点,所以大胆的放在了1个线程,但是对于Kafka呢,怎么办?
对于kafka Producer/Consumer来说,是在1个线程里,适合客户端这种并发连接小,数据量小的场景
但是对于服务端来说,就不行,比如对某个socket请求的处理耗时,就会造成线程阻塞,后续其它请求都无法被处理,这业务要骂人了。。。
这样,就充分发挥了多核多线程的优势,
一言以蔽之:调整架构,将网络读写的逻辑与业务处理逻辑拆分,由不同的线程执行,从而实现牛逼的多线程处理。
具体还有一些细节,针对kafka来说
1)Acceptor单独运行在1个线程里,thrift也是默认启动了1个线程。
先插入Thrift的Acceptor线程是如何启动的!

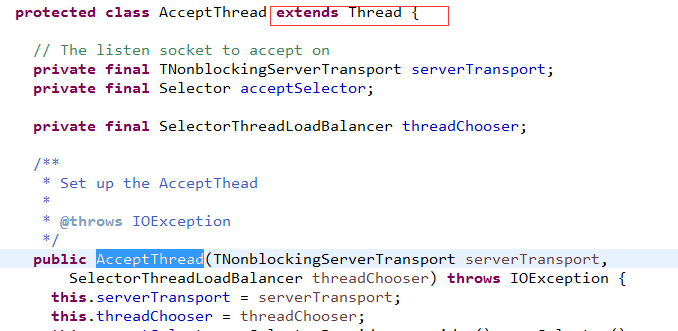
看来Thrift直接启动了一个线程,
其实用ExecutorService来启动单线程更好,因为线程异常退出时,会创建新线程进行补偿!
---
通过accept接收到的socketchannel,会注册OP_READ事件,负责服务端的 socket读取逻辑,这个时候
一个线程会处理多个socket,不然没法处理多socket啊,成功读取请求后,注意这里的成功读取是完整读取了1个socket请求体,这里涉及到业务协议,时刻注意TCP的字节流特性!!!
读取了完整的请求体后,怎么做?我们先看Thrift怎么做的,同类产品来个对比嘛
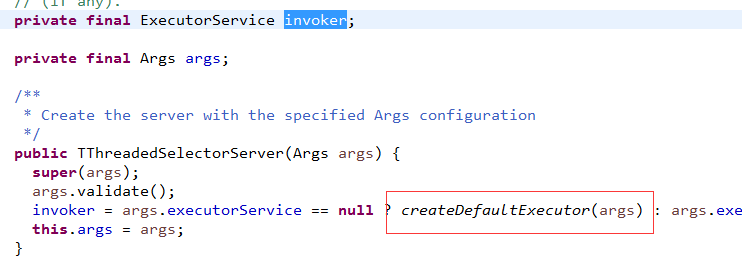

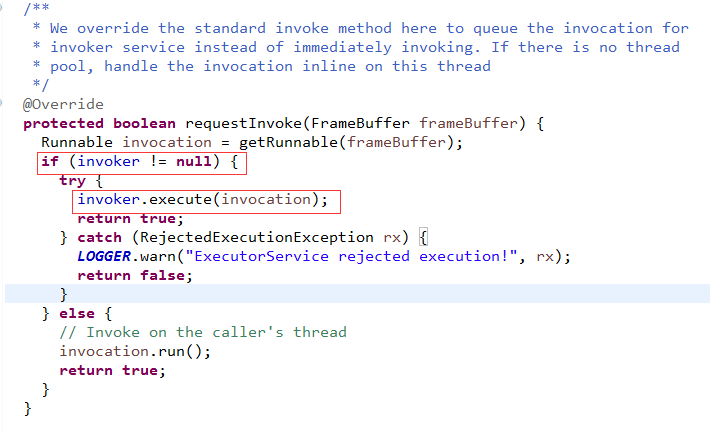
可见,这里是new了1个业务线程池,然后把请求抛到业务线程池里,
注意,我们都知道业务线程池内部有1个blockingqueue,其实是把请求放到了这个队列里!
然后我们再来看看 Kafka怎么做的,它是读到了1个完整的请求后,请求放到一个MessageQueue共享队列里,业务线程池中的线程会取出请求,然后执行业务逻辑对请求进行处理。
这种模式跟Thrift的模式基本一致,那么这种处理逻辑有什么好处呢?
因为采用了业务线程池,即使某个业务线程阻塞了,池中还有其它线程继续执行。
就不会堵塞请求,吞吐量才可以保证!
当业务线程处理完后,拿到了结果,怎么处理呢?抛回给IO线程池,至少Thrift是这么玩的
IO线程池的优势就是快速知道一个socket可以进行读写,然后才进行读写,整个Reactor框架的核心就在于此!!!
===
最后需要注意的是,当请求进入的速度与处理的速度不匹配时,MessageQueue的长度非常重要。
尤其是这个Queue的大小固定时,我们先看Thrift的队列大小是怎么选择的

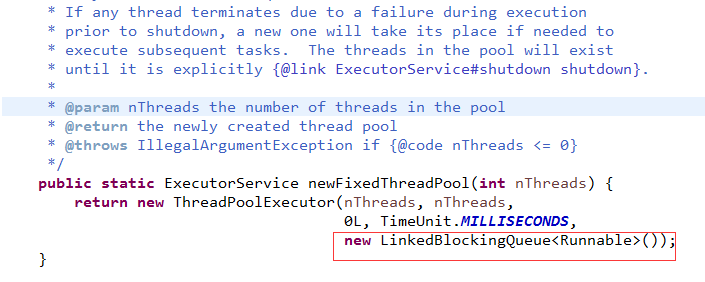
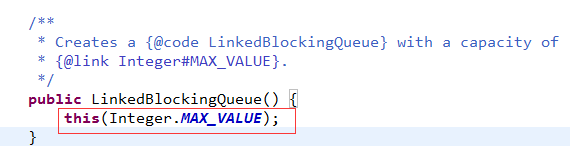
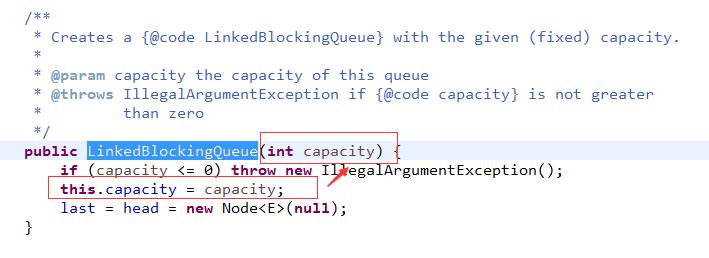
不用我再多解释1个字了吧。
如果长度太小,放不进去,请求都不用处理直接失败了
如果不限制长度,可能请求太多涌入,导致内存溢出,需要业务人员自己设置参数
(擦,业务自己背锅啊)
如果同一时间出现大量IO事件,单个selector可能忙不过来,可以设置多个Selector,监听不同的IO事件
其实就是处理不同的socket,本质还不就是负载均衡么。。。
这个也没啥好说的!
=======================================================
还是以Thrift类比来讲解,我们看Thrift怎么实现的!
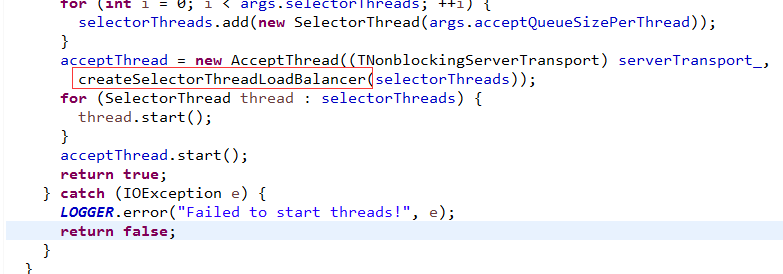

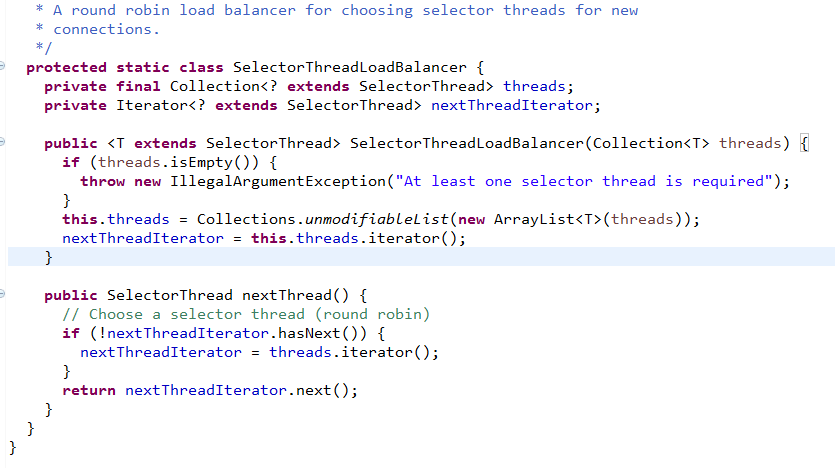
不用我解释了,轮询大法好!
强调1点,这个算法是用来选择IO线程的,IO线程自己会注册到自己线程专属的Selector上。
-------------------------------------------------------------------
从这一篇开始,我们来研究kafka的网络引擎的源码。
可能很多读者有疑问,说好的Kafka讲解,怎么变成Thrift了? 答案: 原理都一样,先拿Thrift为例,讲解网络服务器的Reactor本质,后面会专门 针对这个开一篇博客讲解Kafka的源码,敬请期待!
==========================================
开始介绍kafka服务端之前,先从整体上了解架构。
本章会详细介绍每个组件的功能和实现!
网络层
如果以前看过网上的文章,就知道kafka的客户端会跟服务端的多个broker建立网络连接。
通过这些 socket连接传递各种信息,从而实现c/s交互!
客户端一般情况下不会碰到大数据量访问。
服务端则不同,面对高并发、低延迟的需求,Kafka服务端使用Reactor模式实现其网络层。
这一层不仅仅要管理producer,consumer,还要管理来自其它broker的连接(想一想为什么? :)
---Reactor模式
在聊这种模式之前,让我们快乐的想一想redis,netty,mina,thrift的网络模型 无一例外基本都是这种模型,特殊一点的是redis单线程操作,而它之所以敢这么做,原因就在于它是1个内存操作,否则必须死翘翘。
好,聊到reactor模式,那么这个到底是啥玩意?
我们先想一想如何写一个网络服务器,要解决哪些问题? 1)accept问题 2)I/O处理读写的问题,其中读是读取完整逻辑报文 3)业务逻辑处理,包含各种后端业务交互过程 任何1个网络服务器,都要解决这3个问题,否则就是耍流氓了。
那么,具体要怎么实现呢?
1)读取配置文件,生成listening socket,产生监听套接字,然后注册OP_ACCEPT事件到selector上
注意,针对监听套接字的可读,就是有client socket连接进来导致acceptable事件 :)
一般是启动1个Acceptor线程来处理这种事件
2)一旦有连接过来,服务端的Selector监听到此事件,触发accept事件。
3)创建socketChannel,设置为非阻塞模式,在别的selector上注册I/O事件
(其实这里才是Reactor事件的核心,利用Linux内核的机制高效监听各种socket可以操作的事件,不会造成浪费!!! socket设置为非阻塞模式也正是因为此!)
4)当客户端发送消息时,服务端的Selector监听到OP_READ事件,触发执行相应的处理逻辑。
当服务端可以写时,服务端监听到OP_WRITE事件,触发执行相应的处理逻辑。
这里一定要请读者考虑到TCP的字节流协议特性,你懂的
---
这里涉及到3种事情,ACCEPT,IO处理,业务处理,涉及到几种线程呢?
redis因为内存操作的特点,所以大胆的放在了1个线程,但是对于Kafka呢,怎么办?
对于kafka Producer/Consumer来说,是在1个线程里,适合客户端这种并发连接小,数据量小的场景
但是对于服务端来说,就不行,比如对某个socket请求的处理耗时,就会造成线程阻塞,后续其它请求都无法被处理,这业务要骂人了。。。
应该怎么做? 读取请求,处理请求,发送请求,应该在不同的线程里来实现 通常读取发送在1个线程,处理请求在另外1个线程。 处理请求的叫做业务线程池 netty不带业务线程池,所以自己要new一个出来。 thrift天生完美自带业务线程池,快速高效! redis是一个另类,内存操作快速,全在1个线程搞定,按下不表!
这样,就充分发挥了多核多线程的优势,
一言以蔽之:调整架构,将网络读写的逻辑与业务处理逻辑拆分,由不同的线程执行,从而实现牛逼的多线程处理。
具体还有一些细节,针对kafka来说
1)Acceptor单独运行在1个线程里,thrift也是默认启动了1个线程。
先插入Thrift的Acceptor线程是如何启动的!
看来Thrift直接启动了一个线程,
其实用ExecutorService来启动单线程更好,因为线程异常退出时,会创建新线程进行补偿!
---
通过accept接收到的socketchannel,会注册OP_READ事件,负责服务端的 socket读取逻辑,这个时候
一个线程会处理多个socket,不然没法处理多socket啊,成功读取请求后,注意这里的成功读取是完整读取了1个socket请求体,这里涉及到业务协议,时刻注意TCP的字节流特性!!!
读取了完整的请求体后,怎么做?我们先看Thrift怎么做的,同类产品来个对比嘛
可见,这里是new了1个业务线程池,然后把请求抛到业务线程池里,
注意,我们都知道业务线程池内部有1个blockingqueue,其实是把请求放到了这个队列里!
然后我们再来看看 Kafka怎么做的,它是读到了1个完整的请求后,请求放到一个MessageQueue共享队列里,业务线程池中的线程会取出请求,然后执行业务逻辑对请求进行处理。
这种模式跟Thrift的模式基本一致,那么这种处理逻辑有什么好处呢?
因为采用了业务线程池,即使某个业务线程阻塞了,池中还有其它线程继续执行。
就不会堵塞请求,吞吐量才可以保证!
当业务线程处理完后,拿到了结果,怎么处理呢?抛回给IO线程池,至少Thrift是这么玩的
IO线程池的优势就是快速知道一个socket可以进行读写,然后才进行读写,整个Reactor框架的核心就在于此!!!
===
最后需要注意的是,当请求进入的速度与处理的速度不匹配时,MessageQueue的长度非常重要。
尤其是这个Queue的大小固定时,我们先看Thrift的队列大小是怎么选择的
不用我再多解释1个字了吧。
如果长度太小,放不进去,请求都不用处理直接失败了
如果不限制长度,可能请求太多涌入,导致内存溢出,需要业务人员自己设置参数
(擦,业务自己背锅啊)
如果同一时间出现大量IO事件,单个selector可能忙不过来,可以设置多个Selector,监听不同的IO事件
其实就是处理不同的socket,本质还不就是负载均衡么。。。
这个也没啥好说的!
=======================================================
一般情况下,Acceptor单独占用1个Selector, 通过accept得到的SocketChannel,通过一定的策略分发给IO线程里的Selector
还是以Thrift类比来讲解,我们看Thrift怎么实现的!
不用我解释了,轮询大法好!
强调1点,这个算法是用来选择IO线程的,IO线程自己会注册到自己线程专属的Selector上。
-------------------------------------------------------------------

相关文章推荐
- Apache Kafka源码剖析:第2篇 Kafka网络引擎: 核心字段&初始化
- Caffe框架源码剖析(2)—训练网络
- 【Linux 内核网络协议栈源码剖析】listen 函数剖析
- 推荐引擎之协同过滤算法——深度剖析及源码实现
- Linux 内核网络协议栈源码剖析】bind 函数剖析
- 【Linux 内核网络协议栈源码剖析】网络栈主要结构介绍(socket、sock、sk_buff,etc)
- 【Linux 内核网络协议栈源码剖析】connect 函数剖析(一)
- Nodejs事件引擎libuv源码剖析之:句柄(handle)结构的设计剖析
- 【Linux 内核网络协议栈源码剖析】recvfrom 函数剖析
- Irrlicht引擎源码剖析——第十四天
- irrlicht引擎源码剖析1 - 引擎概览
- Apache Kafka源码剖析:第6篇 日志存储系列1-基本概念
- 【Linux 内核网络协议栈源码剖析】数据包发送
- 【Linux 内核网络协议栈源码剖析】connect 函数剖析(一)
- Caffe框架源码剖析(2)—训练网络
- Irrlicht引擎源码剖析——第五天
- 【Linux 内核网络协议栈源码剖析】sendto 函数剖析
- irrlicht引擎源码剖析2 - IrrlichtDevice
- 【Linux 内核网络协议栈源码剖析】socket.c——BSD Socket层(1)
- Apache Kafka源码剖析:第5篇 业务API处理