Scrapy爬虫框架
2017-08-06 10:54
246 查看
Scrapy爬虫框架
1.Scrapy的安装
pip install scrapy
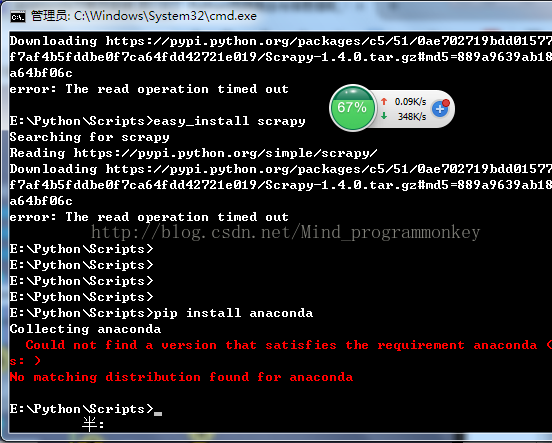
但是在安装过程中存在了一些问题,于是就打算采取下载anaconda来借助安装scrapy库。
(1)Anaconda是python科学计算的集成。下载Anaconda,下载地址:http://continuum.io/downloads。
(2)根据自己的系统选择相应版本进行下载(下载速度可能会有点慢),下载之后点击运行就可以安装了,和一般软件安装毫无二致,无需编译
(3)然后执行命令
conda install scrapy
2.Scrapy是一个爬虫框架,爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
3.

Note: 最简单的单个网页爬取流程是spiders > scheduler > downloader > spiders > item pipeline
(1)Scrapy Engine(Scrapy引擎)
Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。
更多的详细内容可以看下面的数据处理流程。(不需要用户修改)
(2)Scheduler(调度)
调度程序从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请
求后返还给他们。
(3)Downloader(下载器)
下载器的主要职责是抓取网页并将网页内容返还给蜘蛛( Spiders)。
(4)Spiders(蜘蛛)
蜘蛛是有Scrapy用户自己定义用来解析网页并抓取制定URL返回内容的类,每个蜘蛛都能处理一个域名或一组域名。换句话说就是用来定义特定网站的抓取和解析规则。
(5)Item Pipeline(项目管道)
项目管道的主要责任是负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清洗、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。每个项目管道的组件都是有一个简单的方法组成的Python类。他们获取了项目并执行他们的方法,同时他们还需要确定的是是否需要在项目管道中继续执行下一步或是直接丢弃掉不处理。
项目管道通常执行的过程有:
清洗HTML数据
验证解析到的数据(检查项目是否包含必要的字段)
检查是否是重复数据(如果重复就删除)
将解析到的数据存储到数据库中
(6)Downloader middlewares(下载器中间件)
下载中间件是位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。它提供了一个自定义的代码的方式来拓展Scrapy的功能。下载中间器是一个处理请求和响应的钩子框架。他是轻量级的,对Scrapy尽享全局控制的底层的系统。
(7)Spider middlewares(蜘蛛中间件)
蜘蛛中间件是介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。它提供一个自定义代码的方式来拓展Scrapy的功能。蛛中间件是一个挂接到Scrapy的蜘蛛处理机制的框架,你可以插入自定义的代码来处理发送给蜘蛛的请求和返回蜘蛛获取的响应内容和项目。
(8)Scheduler middlewares(调度中间件)
调度中间件是介于Scrapy引擎和调度之间的中间件,主要工作是处从Scrapy引擎发送到调度的请求和响应。他提供了一个自定义的代码来拓展Scrapy的功能。
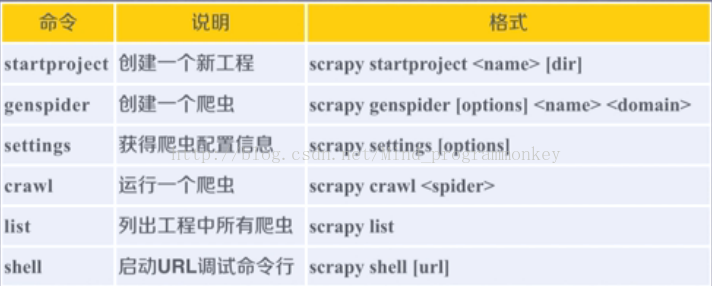
4.Scrapy的常用命令
5.scrapy的使用
步骤1:建立一个Scrapy工程
如:cd pycodes scrapy startprjects pythondemo
生成的工程目录:
pythondemo 外层目录
scrapycfg 部署Scrapy爬虫的配置文件
pythondemo/ Scrapy框架的用户自定义Pyhthon代码
_init_.py 初始化脚本
items.py Items代码模板(继承类)
middlewares.py Middlewares代码模板(继承类)
pipelines,py Pipelines代码模板(继承类)
settings.py Scrapy爬虫的配置文件
spiders/ Spiders代码模板目录(继承类)
步骤2:在工程中创建一个Scrapy爬虫
步骤3:编写Item Pipeline
步骤4:优化配置策略
1.Scrapy的安装
pip install scrapy
但是在安装过程中存在了一些问题,于是就打算采取下载anaconda来借助安装scrapy库。
(1)Anaconda是python科学计算的集成。下载Anaconda,下载地址:http://continuum.io/downloads。
(2)根据自己的系统选择相应版本进行下载(下载速度可能会有点慢),下载之后点击运行就可以安装了,和一般软件安装毫无二致,无需编译
(3)然后执行命令
conda install scrapy
2.Scrapy是一个爬虫框架,爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
3.
Note: 最简单的单个网页爬取流程是spiders > scheduler > downloader > spiders > item pipeline
(1)Scrapy Engine(Scrapy引擎)
Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。
更多的详细内容可以看下面的数据处理流程。(不需要用户修改)
(2)Scheduler(调度)
调度程序从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请
求后返还给他们。
(3)Downloader(下载器)
下载器的主要职责是抓取网页并将网页内容返还给蜘蛛( Spiders)。
(4)Spiders(蜘蛛)
蜘蛛是有Scrapy用户自己定义用来解析网页并抓取制定URL返回内容的类,每个蜘蛛都能处理一个域名或一组域名。换句话说就是用来定义特定网站的抓取和解析规则。
(5)Item Pipeline(项目管道)
项目管道的主要责任是负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清洗、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。每个项目管道的组件都是有一个简单的方法组成的Python类。他们获取了项目并执行他们的方法,同时他们还需要确定的是是否需要在项目管道中继续执行下一步或是直接丢弃掉不处理。
项目管道通常执行的过程有:
清洗HTML数据
验证解析到的数据(检查项目是否包含必要的字段)
检查是否是重复数据(如果重复就删除)
将解析到的数据存储到数据库中
(6)Downloader middlewares(下载器中间件)
下载中间件是位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。它提供了一个自定义的代码的方式来拓展Scrapy的功能。下载中间器是一个处理请求和响应的钩子框架。他是轻量级的,对Scrapy尽享全局控制的底层的系统。
(7)Spider middlewares(蜘蛛中间件)
蜘蛛中间件是介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。它提供一个自定义代码的方式来拓展Scrapy的功能。蛛中间件是一个挂接到Scrapy的蜘蛛处理机制的框架,你可以插入自定义的代码来处理发送给蜘蛛的请求和返回蜘蛛获取的响应内容和项目。
(8)Scheduler middlewares(调度中间件)
调度中间件是介于Scrapy引擎和调度之间的中间件,主要工作是处从Scrapy引擎发送到调度的请求和响应。他提供了一个自定义的代码来拓展Scrapy的功能。
4.Scrapy的常用命令
5.scrapy的使用
步骤1:建立一个Scrapy工程
如:cd pycodes scrapy startprjects pythondemo
生成的工程目录:
pythondemo 外层目录
scrapycfg 部署Scrapy爬虫的配置文件
pythondemo/ Scrapy框架的用户自定义Pyhthon代码
_init_.py 初始化脚本
items.py Items代码模板(继承类)
middlewares.py Middlewares代码模板(继承类)
pipelines,py Pipelines代码模板(继承类)
settings.py Scrapy爬虫的配置文件
spiders/ Spiders代码模板目录(继承类)
步骤2:在工程中创建一个Scrapy爬虫
步骤3:编写Item Pipeline
步骤4:优化配置策略

相关文章推荐
- Ubuntu 12.04 安装Scrapy爬虫框架
- 爬虫 scrapy 框架学习 1. Scrapy框架业务逻辑的理解 + 简单爬虫案例示范
- python爬虫--scrapy 框架 之 项目外运行爬虫(用脚本运行爬虫)
- 【网络爬虫】【python】网络爬虫(四):scrapy爬虫框架(架构、win/linux安装、文件结构)
- python爬虫之scrapy框架
- Python爬虫进阶三之Scrapy框架安装配置
- Python 采用Scrapy爬虫框架爬取豆瓣电影top250
- Python的爬虫程序编写框架Scrapy入门学习教程
- scrapy爬虫框架的详细用法
- Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法
- python爬虫框架scarpy之AttributeError: module 'scrapy' has no attribute 'spider'
- 零基础写python爬虫之爬虫框架Scrapy安装配置
- Ubuntu 12.04 安装Scrapy爬虫框架
- Scrapy:Python的爬虫框架
- Python2 爬虫 -- 初尝Scrapy框架
- Python爬虫Scrapy框架系列之十四
- Scrapy框架利用CrawlSpider创建自动爬虫
- Python爬虫框架Scrapy获得定向打击批量招聘信息
- 爬虫框架scrapy,爬取豆瓣电影top250
- centos6.3 安装python爬虫框架scrapy