逻辑回归
2017-07-31 07:40
585 查看
Logistic Regression
推导:
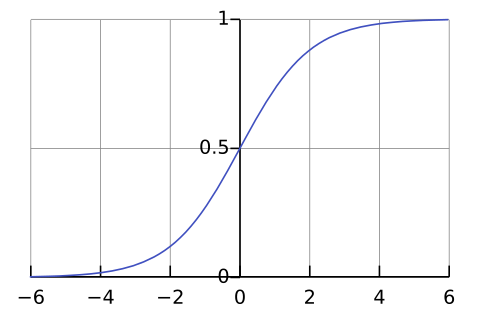
logit->sigmoid=P记一个事件发生的概率为:logit函数:推导出:S形函数:P(y=1|x),简记为P;不发生则为1-Plogit(x)=ln(P1−P)=w0+w1x1+w2x2+⋯+wmxmP(y=1|x)=P=11+e−z 其中:z=w0+w1x1+w2x2+⋯+wmxmf(z)=11+e−z定义域(−∞,+∞),值域(0,1)
cost 函数
似然函数->max;-ln(似然函数)->min(v凸函数)似然函数:二分类中:整理,得:L=∏iPiL(w)似然函数最大化→等价于P(y=0)带入L(w)cost(w)求解:=∏iNP(xi|y=1)yi⋅P(xi|y=0)1−yiargw max L(w)argw min −L(w)=1−P(y=1)并取自然对数ln,并取负,可得Loss损失函数:=−yi∑ilnP−(1−yi)∑iln(1−P)=−∑inyiz+∑inln(1+ez)=−∑inyiw⋅xi+∑inln(1+ew⋅xi)argw min cost(w)在区间(0,1)−lnx;−ln(1−x) 均为v凸函数,局部min=全局min
优化求解
对 L(w) 求 w的 偏 导 :ln(1+ew⋅xi)′∂∂wL(w)=(1+ew⋅xi)′(1+ew⋅xi)=ew⋅xi (w⋅xi)′(1+ew⋅xi)=ew⋅xi xi(1+ew⋅xi)=11+e−w⋅xi xi=f(w⋅xi) xi=Pi xi=−∑inyi xi+∑in[ln(1+ew⋅xi)]′=∑in(Pi−yi) xi梯度法求解:BGD,SGD
BGD-> python code […]其他方法:共轭梯度法、BFGS、L-BFGS
见 … .待编辑python代码实现 BGD SGD
import numpy as np
def sigmoid(z):
return 1/(1+np.exp(-z))
def gradDesc(x,y,lr=0.01,loop=402,opt='gd'):
w=np.zeros(len(x[0]))
b=0
if opt'gd': #梯度下降法
for i in range(loop):
error=sigmoid((x.dot(w)+b))-y #P_i-y_i
#grad_w=\sum_i^N (p_i-y_i)*x_i
w-=lr*np.dot(error,x)
b-=lr*(error.sum()) #grad_b,(x_i=1)即可
elif opt'sgd': #随机梯度下降法
for looper in range(loop):
for i in range(len(y)):
# print(w.dot(x[i],w))
error=sigmoid(w.dot(x[i])+b)-(y[i])
w-=lr*error*(x[i])
b-=lr*error
elif opt'xx':
pass
else:
print('Not support this optimize method')
#raise error
return w,b
if __name__ '__main__':
# x_train,y_train
x=np.array([[0,0],[1,1],[0,1],[1,0],[2,1],[3,3],[1,2],[1,3],[0.9,0.9]])
y=np.array([0,0,0,0,1,1,1,1,1])
w,b=gradDesc(x,y,lr=0.001,opt='sgd',loop=10000)
print(':',w/b,b)
import matplotlib.pyplot as plt
plt.scatter(x[:,0],x[:,1],c=y)
x_plot=np.array([x.min(),x.max()],dtype='float32')
y_plot=-(x_plot*w[0]+b)/(w[1])
plt.plot(x_plot,y_plot)
plt.show()

相关文章推荐
- 梯度下降原理及在线性回归、逻辑回归中的应用
- 机器学习算法与Python实践之逻辑回归(Logistic Regression)
- 逻辑斯蒂回归模型
- 逻辑回归与过拟合问题
- 逻辑回归LR的特征为什么要先离散化
- [转]逻辑斯蒂回归 via python
- 《统计学习方法》第六章逻辑斯蒂回归与最大熵模型学习笔记
- 机器学习: 逻辑回归(Logistic Regression)
- 转载:逻辑回归的python实现
- 线性模型和逻辑回归
- 机器学习入门系列三(关键词:逻辑回归,正则化)
- 机器学习之逻辑回归基础
- 机器学习二 逻辑回归作业
- 一篇浅显介绍逻辑回归的文章
- 过拟合和逻辑回归
- 逻辑回归以及广义线性模型总结
- 逻辑回归python实现(随机增量梯度下降,变步长)
- 使用R进行逻辑回归 分类
- 机器学习—逻辑回归理论简介
- LR(逻辑回归)