抛除C++旧印象(二):C#Dictionary源码剖析
2017-07-30 21:06
429 查看
C++中STL的Map跟C#的Dictionary的使用几乎是一样的,Map使用的是红黑树来实现,所以想当然的以为C#的Dictionary也是红黑树,老兄,那可真就大错特错了。
我也是有次没事去看下Dictionary的实现才发现压根就没有树的影子,原来使用散列表的方式来实现。下面我们一起来看下Dictionary的内部实现:
可以看到声明了两个数组,其中buckets记录的为指向entries数组的索引,entries记录的为dictionary的value值部分,count为存储的元素的数量,version为当前的版本号,freeList为空闲的列表,freeCount为空闲的列表数量。
我认为dictionary最重要的就是Insert函数,理解了Insert函数就说明你真正理解了dictionary的实现方式了,Add方法最终调用的也是Insert函数,代码如下:
private void Insert(TKey key, TValue value, bool add) {
if( key == null ) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets == null) Initialize(0);//第一次初始化
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;//得到key的hashcode进行运算并得到在buckets的索引值
int targetBucket = hashCode % buckets.Length;
#if FEATURE_RANDOMIZED_STRING_HASHING
int collisionCount = 0;
#endif
for (int i = buckets[targetBucket]; i >= 0; i = entries[i].next) {//判断是否已经存在,如果存在,那么进行值得替换
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {
if (add) {
ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate);
}
entries[i].value = value;
version++;
return;
}
#if FEATURE_RANDOMIZED_STRING_HASHING
collisionCount++;
#endif
}
int index;
if (freeCount > 0) {//判断entries是否有释放的空闲空间,如果有,则进行利用
index = freeList;
freeList = entries[index].next;
freeCount--;
}
else {
if (count == entries.Length) //数组空间不够,则重新分配两倍的内存进行存储
{
Resize();
targetBucket = hashCode % buckets.Length;
}
index = count;
count++;
}
entries[index].hashCode = hashCode;//具体的值存储
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
buckets[targetBucket] = index;
version++;
#if FEATURE_RANDOMIZED_STRING_HASHING
#if FEATURE_CORECLR
// In case we hit the collision threshold we'll need to switch to the comparer which is using randomized string hashing
// in this case will be EqualityComparer<string>.Default.
// Note, randomized string hashing is turned on by default on coreclr so EqualityComparer<string>.Default will
// be using randomized string hashing
if (collisionCount > HashHelpers.HashCollisionThreshold && comparer == NonRandomizedStringEqualityComparer.Default)
{
comparer = (IEqualityComparer<TKey>) EqualityComparer<string>.Default;
Resize(entries.Length, true);
}
#else
if(collisionCount > HashHelpers.HashCollisionThreshold && HashHelpers.IsWellKnownEqualityComparer(comparer))
{
comparer = (IEqualityComparer<TKey>) HashHelpers.GetRandomizedEqualityComparer(comparer);
Resize(entries.Length, true);
}
#endif // FEATURE_CORECLR
#endif
}
这段代码的难点就在于buckets数组和entries数组的映射,如果这理解了,代码自然就清晰了。
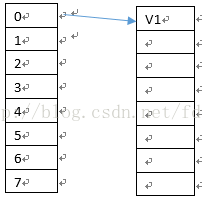
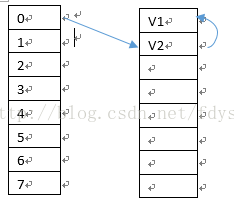
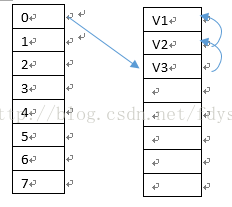
在add第一份数据V1的时候,假如hashcode取余的索引数据为0,则把V1放入entries的第一个数据中,buckets[0]存储的数据为V1在entries的索引,所以buckets[0]为0,假设add的第二份数据V2的hashcode值取模后也为0,那么表示这两份数据的key值发生了碰撞,则判断buckets[0]指向的entries链的key值是否与当前插入V2对应的key值相等,如果相等则用V2替换原有值,如果不等,则V2插入到entries的空闲列表中(因为remove,中间空出的内存块),如果不存在空闲列表则直接插入到末尾,本例因为刚添加,所以直接添加到entries[1]中,然后把entries[1]中的hashcode值赋为V2对应key的hashcode值,next指向0,对应buckets[0]也改成指向entries[1],插入V3与插入V2同理。多添加几个value值时,有可能如下图所示:
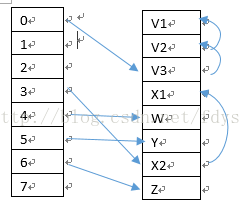
还有个点时如同List一样,Dictionary在数组不够用的情况下会分配2倍的新内存来进行存储,与List不同的是capacity的默认值为3,而且dictionary包含了buckets和entries两个数组,entries是通过Array.Copy直接拷贝到新地址,但是buckets的计算方式是haahcode对长度取余,所以在长度变化后,不能直接通过内存拷贝的方式,而是必须全部再重新计算一遍。在Dictionary的构造函数中可以直接对其进行设置,所以capacity的值如果能设置的合理,那么可以减少内存申请、拷贝的次数,效率也会提高很多。
4000
我也是有次没事去看下Dictionary的实现才发现压根就没有树的影子,原来使用散列表的方式来实现。下面我们一起来看下Dictionary的内部实现:
public class Dictionary<TKey,TValue>: IDictionary<TKey,TValue>, IDictionary, IReadOnlyDictionary<TKey, TValue>, ISerializable, IDeserializationCallback {
private struct Entry {
public int hashCode; // Lower 31 bits of hash code, -1 if unused
public int next; // Index of next entry, -1 if last
public TKey key; // Key of entry
public TValue value; // Value of entry
}
private int[] buckets;
private Entry[] entries;
private int count;
private int version;
private int freeList;
private int freeCount;
private IEqualityComparer<TKey> comparer;
private KeyCollection keys;
private ValueCollection values;
private Object _syncRoot;可以看到声明了两个数组,其中buckets记录的为指向entries数组的索引,entries记录的为dictionary的value值部分,count为存储的元素的数量,version为当前的版本号,freeList为空闲的列表,freeCount为空闲的列表数量。
我认为dictionary最重要的就是Insert函数,理解了Insert函数就说明你真正理解了dictionary的实现方式了,Add方法最终调用的也是Insert函数,代码如下:
private void Insert(TKey key, TValue value, bool add) {
if( key == null ) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets == null) Initialize(0);//第一次初始化
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;//得到key的hashcode进行运算并得到在buckets的索引值
int targetBucket = hashCode % buckets.Length;
#if FEATURE_RANDOMIZED_STRING_HASHING
int collisionCount = 0;
#endif
for (int i = buckets[targetBucket]; i >= 0; i = entries[i].next) {//判断是否已经存在,如果存在,那么进行值得替换
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {
if (add) {
ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate);
}
entries[i].value = value;
version++;
return;
}
#if FEATURE_RANDOMIZED_STRING_HASHING
collisionCount++;
#endif
}
int index;
if (freeCount > 0) {//判断entries是否有释放的空闲空间,如果有,则进行利用
index = freeList;
freeList = entries[index].next;
freeCount--;
}
else {
if (count == entries.Length) //数组空间不够,则重新分配两倍的内存进行存储
{
Resize();
targetBucket = hashCode % buckets.Length;
}
index = count;
count++;
}
entries[index].hashCode = hashCode;//具体的值存储
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
buckets[targetBucket] = index;
version++;
#if FEATURE_RANDOMIZED_STRING_HASHING
#if FEATURE_CORECLR
// In case we hit the collision threshold we'll need to switch to the comparer which is using randomized string hashing
// in this case will be EqualityComparer<string>.Default.
// Note, randomized string hashing is turned on by default on coreclr so EqualityComparer<string>.Default will
// be using randomized string hashing
if (collisionCount > HashHelpers.HashCollisionThreshold && comparer == NonRandomizedStringEqualityComparer.Default)
{
comparer = (IEqualityComparer<TKey>) EqualityComparer<string>.Default;
Resize(entries.Length, true);
}
#else
if(collisionCount > HashHelpers.HashCollisionThreshold && HashHelpers.IsWellKnownEqualityComparer(comparer))
{
comparer = (IEqualityComparer<TKey>) HashHelpers.GetRandomizedEqualityComparer(comparer);
Resize(entries.Length, true);
}
#endif // FEATURE_CORECLR
#endif
}
这段代码的难点就在于buckets数组和entries数组的映射,如果这理解了,代码自然就清晰了。
在add第一份数据V1的时候,假如hashcode取余的索引数据为0,则把V1放入entries的第一个数据中,buckets[0]存储的数据为V1在entries的索引,所以buckets[0]为0,假设add的第二份数据V2的hashcode值取模后也为0,那么表示这两份数据的key值发生了碰撞,则判断buckets[0]指向的entries链的key值是否与当前插入V2对应的key值相等,如果相等则用V2替换原有值,如果不等,则V2插入到entries的空闲列表中(因为remove,中间空出的内存块),如果不存在空闲列表则直接插入到末尾,本例因为刚添加,所以直接添加到entries[1]中,然后把entries[1]中的hashcode值赋为V2对应key的hashcode值,next指向0,对应buckets[0]也改成指向entries[1],插入V3与插入V2同理。多添加几个value值时,有可能如下图所示:
还有个点时如同List一样,Dictionary在数组不够用的情况下会分配2倍的新内存来进行存储,与List不同的是capacity的默认值为3,而且dictionary包含了buckets和entries两个数组,entries是通过Array.Copy直接拷贝到新地址,但是buckets的计算方式是haahcode对长度取余,所以在长度变化后,不能直接通过内存拷贝的方式,而是必须全部再重新计算一遍。在Dictionary的构造函数中可以直接对其进行设置,所以capacity的值如果能设置的合理,那么可以减少内存申请、拷贝的次数,效率也会提高很多。
4000

相关文章推荐
- 抛除C++旧印象(一):C#List源码剖析
- C# Dictionary源码剖析
- C++和C#进程之间通过命名管道通信(附源码)—下
- C# ArrayList源码剖析
- 白话算法(6.5) 泛型 Dictionary 源码剖析(下)
- C++仿c#的delegate的实现源码
- Boost源码剖析:C++泛型函数指针类function
- c# 源码深度剖析 list
- 使用UltraEdit32编辑器格式化源码功能 XML、Java、C/C++、C#
- Windows Phone 8.1 摄像机预览和手电筒(附加C#/C++/CX源码)
- 白话算法(6.4) 能让 Dictionary 比 Hashtable 慢 600 倍? ——泛型 Dictionary 源码剖析(上)
- 白话算法(6.4) 能让 Dictionary 比 Hashtable 慢 600 倍? ——泛型 Dictionary 源码剖析(上)
- c++ poco Event 源码剖析
- c++ poco StreamSocket 源码剖析
- C++xml文件操作 CMarkup学习方法说明 最近正在研究C++下的XML分析工具CMarkup。初次和XML相遇是基于C#对XML的操作。C#的XmlDocument和XmlNode给我印象
- C++ Standard Stl -- SGI STL源码学习笔记(06) stl_vector 与 一些问题的细化 2 push_back函数剖析
- C#debug跟踪C++DLL源码
- C#之Dictionary 与 C++之map
- c/c++:strlen源码剖析
- C++和C#进程之间通过命名管道通信(附源码)—下