[笔记]监督学习·梯度下降
2017-07-29 09:51
288 查看
监督学习(Supervised Learning)
SupervisedLearning,Wiki通过训练资料(包含输入和预期输出的数据集)去学习或者建立一个函数模型,并依此模型推测新的实例。函数的输出可以是一个连续的值(回归问题,Regression),或是预测一个分类标签(分类问题,Classification)。
机器学习中与之对应还有:
无监督学习(Unsupervised Learning)
强化学习(Reinforcement Learning)

在课程中定义了一些符号:
x(i) :输入特征(input features)
y(i) :目标变量(target variable)
(x(i),y(i)) :训练样本(training example)
{(x(i),y(i));i=1,...,m} :训练集合(training set)
m :训练样本数量
h :假设函数(hypothesis)
线性回归(Linear Regression)
栗子:房屋价格与居住面积和卧室数量的关系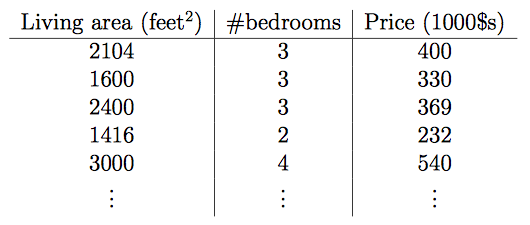
在这里输入特征变成了两个x1,x2,目标变量就是价格
x1: Living area
x2: bedrooms
可以把它们称之为x的二维向量。
在实际情况中,我们需要根据你所选择的特征来进行一个项目的设计。
我们之前已经了解了监督学习,所以需要我们决定我们应该使用什么样的假设函数来进行训练参数。线性函数是最初级,最简单的选择。
所以针对例子假设函数:
hθ(x)=θ0+θ1x1+θ2x2
h(x)=∑i=0nθixi=θTx
其中的θ就是要训练的参数(也被成为权重),我们想要得到尽可能符合变化规律的参数,使得这个函数可以用来估计价格。
因为要训练θ,所以引入cost function(损失函数/成本函数)
J(θ)=12∑i=1m(hθ(x(i))−y(i))2
最小二乘法(LMS algorithm)
我们需要求出使J(θ)最小化的θ,所以使用梯度下降算法(gradient descent algorithm)该算法通过从一个初始的θ值开始,不断地对θ值进行更新使J(θ)更小,直到找到一个θ值可以使J(θ)最小。更新方式:θj:=θj−α∂∂θjJ(θ)
α :学习速率(learning rate),它决定了梯度下降一步的大小。
:= :为赋值符号
假设只有一个训练样本(x,y):
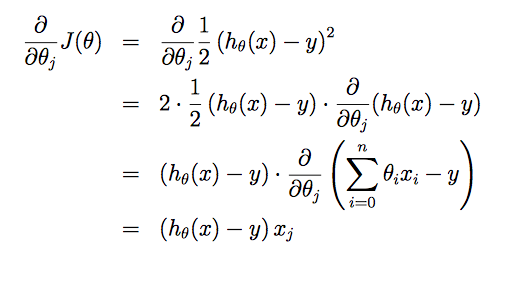
所以更新函数为:
θj:=θj+α(y(i)−hθ(x(i)))x(i)j
这就是最小二乘法(LMS, least mean squares)更新规则。
在面对多个样本进行处理时,就需要在此基础上演变更新规则。
批处理梯度下降(batch gradient descent)
每一步都要访问整个数据集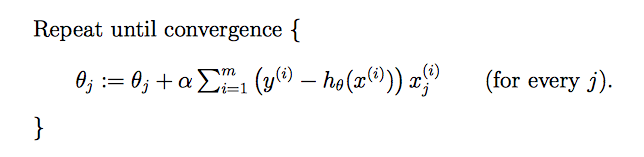
随机梯度下降(stochastic gradient descent)
每个样本进行一次更新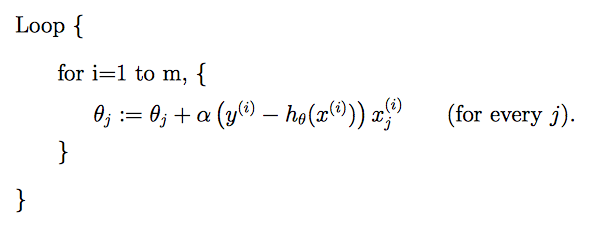
随机梯度下降比批处理梯度下降收敛更快。
所以当数据集比较大时,随机梯度下降优于批处理梯度下降。
正规方程组(normal equations)
矩阵导数

简单地来说就是用矩阵中的每个元素对f求导,然后将导数写在各个元素对应的位置。
矩阵的迹
一个n×n矩阵A的主对角线(从左上方至右下方的对角线)上各个元素的总和被称为矩阵A的迹(或迹数),一般记作tr(A)。trA=∑i=1nAii
常用性质:
实数a,tra=a
trA=trAT
trAB=trBA
trABC=trCAB=trBCA
▽AtrAB=BT
▽AtrABATC=CAB+CTABT
方程组求解
前提设计:X输入特征,y目标变量
根据性质对式子进行展开化简
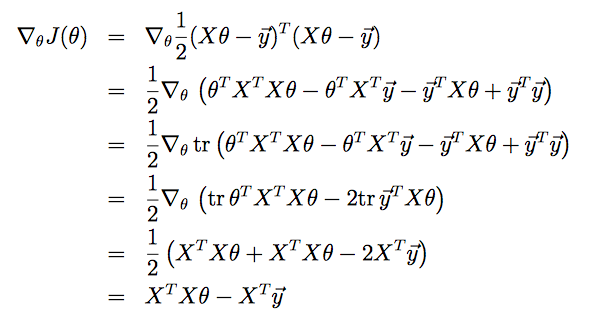
其中,
第三步用到了tra=a
第四步用到了trA=trAT
第五步用到了▽AtrABATC=CAB+CTABT
▽θtrθTXTXθ=▽θtrθθTXTX=▽θtrθIθTXTX,I为单位矩阵,
由此可化为▽AtrABATC形式,A=θ,B=I,C=XTX。
使J最小化,所以▽θJ(θ)=0,可得到正规方程组:
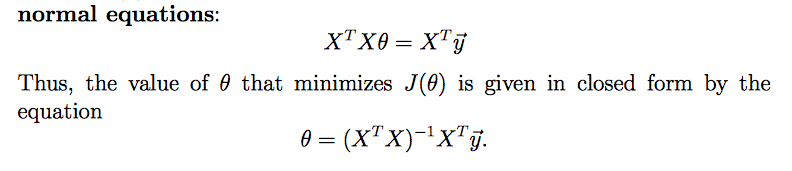

相关文章推荐
- 【机器学习-斯坦福】学习笔记2 - 监督学习应用与梯度下降
- 【斯坦福---机器学习】复习笔记之监督学习应用.梯度下降
- 【机器学习-斯坦福】学习笔记2 - 监督学习应用与梯度下降
- 机器学习笔记二:监督学习应用:梯度下降
- 斯坦福大学公开课 :机器学习课程笔记-[第2集] 监督学习应用.梯度下降
- Andrew Ng 机器学习 第一课 监督学习应用.梯度下降 笔记
- 机器学习笔记(1)---监督学习之梯度下降
- Ng深度学习笔记 1-线性回归、监督学习、成本函数、梯度下降
- 监督学习应用.梯度下降笔记
- 监督学习之梯度下降——Andrew Ng机器学习笔记(一)
- 机器学习-斯坦福:学习笔记2-监督学习应用与梯度下降
- 第二课 监督学习应用 梯度下降
- 机器学习-学习笔记-梯度下降-SGD/BGD
- Andrew Ng机器学习公开课02:监督学习应用:梯度下降
- CS229学习笔记之线性回归与梯度下降
- 机器学习学习笔记(二)-- 梯度下降
- 监督学习应用与梯度下降
- 监督学习应用与梯度下降
- 【机器学习】1 监督学习应用与梯度下降
- 【学习笔记】斯坦福大学公开课(机器学习) 之一:线性回归、梯度下降