利用回归方程进行预测
2017-07-26 00:00
316 查看
预测
通过自变量 x 的取值来预测因变量 y 的取值
点估计
平均值的点估计
a、利用估计回归方程
E(y) =
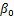
+
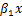
b、对于 x 的一个特定值 x0 ,求出 y 平均值的一个估计值 E(
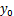
)
个别值的点估计
a、利用回归方程

=
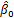
+
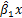
b、对于一个 x 的一个特定值 x0 ,求出 y 的一个个别值的估计值

注:
a、平均值的点估计实际上是对总体参数的估计,
而个别值的点估计则是对因变量的某各取值的估计
b、在点估计条件下,对于同一个 X0,平均值的点估计和个别值的点估计的结果是一样的,但在区间估计中则有所不同
区间估计
对于 x 的一个特定值 x0 ,求出 y 的一个估计值的区间就是区间估计
置信区间估计
对 x 的一个给定值 x0,求出 y 的平均值的估计区间,这区间称为
置信区间
设 X0 为自变量 x 的一个特定值或给定值 ,E(
)为给定 x0 时因变量 y 的平均值或期望值,当 x = x0 时,
=
+
0
为 E(
)的估计值
一般来说,不能期望估计值
0 精确的等于 E(
) ,需要考虑估计的回归方程得到的
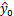
的方差,对于给定的 x0 ,统计学家给出的
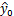
的标准差计算公式,用
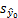
表示
的标准差的估计量
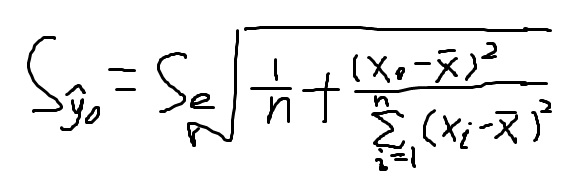
有了
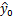
的标准差,对于给定的 x0, E(
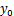
)在 1- a 置信水平下的置信区间可表示为
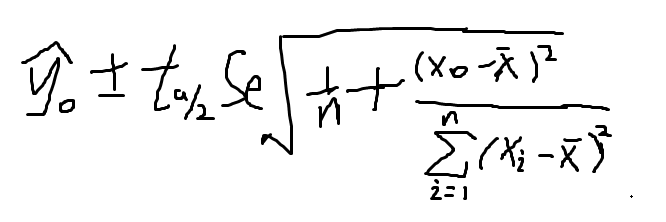
当 x0 =
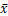
时,
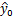
的标准差的估计量最小,此时有
=
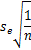
,这就是说,此时估计是最准确的, x0 偏离
越远, y 的平均值的置信区间就变得越宽,估计的效果就越不好
预测区间估计
对 x 的一个给定值 x0,求出 y 的一个个别值的估计区间,这区间称为
预测区间
统计学家给出了 y 的一个个别值
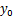
的标准差的估计量,计算公式为
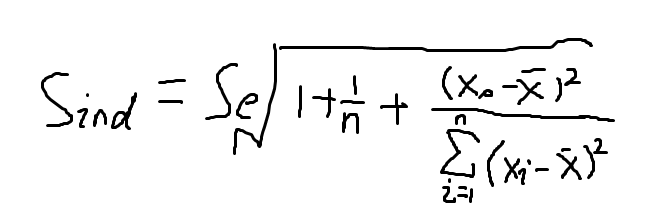
对于一个给定的 x0 y的一个个别指 y0 在 1-a 置信水平下的预测区间为
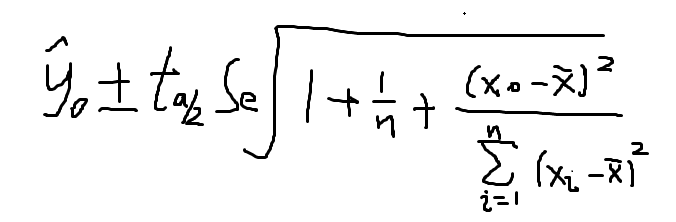
由两个式子中可以看出,预测区间面要比置信区间宽一些,因为更好多了一个1
注:
在利用回归方程进行估计或预测时,
不要在样本数据之外的 x 值去预测相对应的 y 值,因为在一元线性回归分享中,总是假定因变量 y 与自变量 x 之间的关系用线性模型表达是正确的,但实际应用中他们之间的关系可能是某种曲线。
通过自变量 x 的取值来预测因变量 y 的取值
点估计
平均值的点估计
a、利用估计回归方程
E(y) =
+
b、对于 x 的一个特定值 x0 ,求出 y 平均值的一个估计值 E(
)
个别值的点估计
a、利用回归方程
=
+
b、对于一个 x 的一个特定值 x0 ,求出 y 的一个个别值的估计值
注:
a、平均值的点估计实际上是对总体参数的估计,
而个别值的点估计则是对因变量的某各取值的估计
b、在点估计条件下,对于同一个 X0,平均值的点估计和个别值的点估计的结果是一样的,但在区间估计中则有所不同
区间估计
对于 x 的一个特定值 x0 ,求出 y 的一个估计值的区间就是区间估计
置信区间估计
对 x 的一个给定值 x0,求出 y 的平均值的估计区间,这区间称为
置信区间
设 X0 为自变量 x 的一个特定值或给定值 ,E(
)为给定 x0 时因变量 y 的平均值或期望值,当 x = x0 时,
=
+
0
为 E(
)的估计值
一般来说,不能期望估计值
0 精确的等于 E(
) ,需要考虑估计的回归方程得到的
的方差,对于给定的 x0 ,统计学家给出的
的标准差计算公式,用
表示
的标准差的估计量
有了
的标准差,对于给定的 x0, E(
)在 1- a 置信水平下的置信区间可表示为
当 x0 =
时,
的标准差的估计量最小,此时有
=
,这就是说,此时估计是最准确的, x0 偏离
越远, y 的平均值的置信区间就变得越宽,估计的效果就越不好
预测区间估计
对 x 的一个给定值 x0,求出 y 的一个个别值的估计区间,这区间称为
预测区间
统计学家给出了 y 的一个个别值
的标准差的估计量,计算公式为
对于一个给定的 x0 y的一个个别指 y0 在 1-a 置信水平下的预测区间为
由两个式子中可以看出,预测区间面要比置信区间宽一些,因为更好多了一个1
注:
在利用回归方程进行估计或预测时,
不要在样本数据之外的 x 值去预测相对应的 y 值,因为在一元线性回归分享中,总是假定因变量 y 与自变量 x 之间的关系用线性模型表达是正确的,但实际应用中他们之间的关系可能是某种曲线。

相关文章推荐
- 利用LSTM对股票的收盘价进行回归预测
- 【自然语言处理入门】03:利用线性回归对数据集进行分析预测(下)
- 利用支持向量机(回归)SVR进行回归预测(复习8)
- 利用K近邻(回归)KNeighborsRegressor进行回归预测(复习9)
- 【自然语言处理入门】03:利用线性回归对数据集进行分析预测(上)
- 利用树的集成回归模型RandomForestRegressor/ExtraTreesRegressor/GradientBoostingRegressor进行回归预测(复习11)
- 利用回归树对Boston房价进行预测,并对结果进行评估
- 利用线性回归器LinearRegression/SGDRegressor进行回归预测(复习7)
- 利用回归树DecisionTreeRegressor进行回归预测(复习10)
- 逻辑回归(Logistic Regression, LR)又称为逻辑回归分析,是分类和预测算法中的一种。通过历史数据的表现对未来结果发生的概率进行预测。例如,我们可以将购买的概率设置为因变量,将用户的
- TensorFlow 1.4利用Keras+Estimator API进行训练和预测
- Excel在统计分析中的应用—第十二章—回归分析与预测-应用回归分析宏工具进行回归分析
- 利用Python【Orange】结合DNA序列进行人种预测
- 使用三种继承回归模型对美国波士顿房价训练数据进行学习,并对测试数据进行预测
- K近邻回归模型对Boston房价进行预测,同时对性能进行评估(1.使用普通的算术平均法2.考虑距离差异进行加权平均)
- 如何利用季节性数据进行预测分析
- 利用MATLAB 2016a进行BP神经网络的预测(含有神经网络工具箱)
- 利用CNN进行人脸年龄预测
- 利用python进行泰坦尼克生存预测——数据探索分析
- Excel在统计分析中的应用—第十二章—回归分析与预测-运用LINEST函数进行多元线性回归分析