R中季节性时间序列分析及非季节性时间序列分析
2017-07-25 17:45
330 查看
序列分解
1、非季节性时间序列分解
移动平均MA(Moving Average)①SAM(Simple Moving Average)
简单移动平均,将时间序列上前n个数值做简单的算术平均。
SMAn=(x1+x2+…xn)/n
②WMA(Weighted Moving Average)
加权移动平均。基本思想,提升近期的数据、减弱远期数据对当前预测值的影响,使平滑值更贴近最近的变化趋势。
用Wi来表示每一期的权重,加权移动平均的计算:
WMAn=w1x1+w2x2+…+wnxn
R中用于移动平均的API
install.packages(“TTR”)
SAM(ts,n=10)
ts 时间序列数据
n 平移的时间间隔,默认值为10
WMA(ts,n=10,wts=1:n)
wts 权重的数组,默认为1:n
#install.packages('TTR')
library(TTR)
data <- read.csv("data1.csv", fileEncoding="UTF8")
plot(data$公司A, type='l')
data$SMA <- SMA(data$公司A, n=3)
lines(data$SMA)
plot(data$公司A, type='l')
data$WMA <- WMA(data$公司A, n=3, wts=1:3)
lines(data$WMA)
2、季节性时间序列分解
在一个时间序列中,若经过n个时间间隔后呈现出相似性,就说该序列具有以n为周期的周期性特征。分解为三个部分:
①趋势部分
②季节性部分
③不规则部分
R中用于季节性时间序列分解的API
序列数据周期确定
freg<-spec.pgram(ts,taper=0, log=’no’, plot=FALSE)
start<-which(freqspec==max(freqspec))周期开始位置
frequency<-1/freqfreq[which(freqspec==max(freq$spec))]周期长度
序列数据分解
decompose(ts)
data <- read.csv("data2.csv", fileEncoding = "UTF8")
freq <- spec.pgram(data$总销量, taper=0, log='no', plot=FALSE);
start <- which(freq$spec==max(freq$spec))
frequency <- 1/freq$freq[which(freq$spec==max(freq$spec))]
data$均值 <- data$总销量/data$分店数
freq <- spec.pgram(data$均值, taper=0, log='no', plot=FALSE);
start <- which(freq$spec==max(freq$spec))
frequency <- 1/freq$freq[which(freq$spec==max(freq$spec))]
plot(data$均值, type='l')
meanTS <- ts(
data$均值[start:length(data$均值)],
frequency=frequency
)
ts.plot(meanTS)
meanTSdecompose <- decompose(meanTS)
plot(meanTSdecompose)
#趋势分解
meanTSdecompose$trend
#季节性分解数据
meanTSdecompose$seasonal
#随机部分
meanTSdecompose$random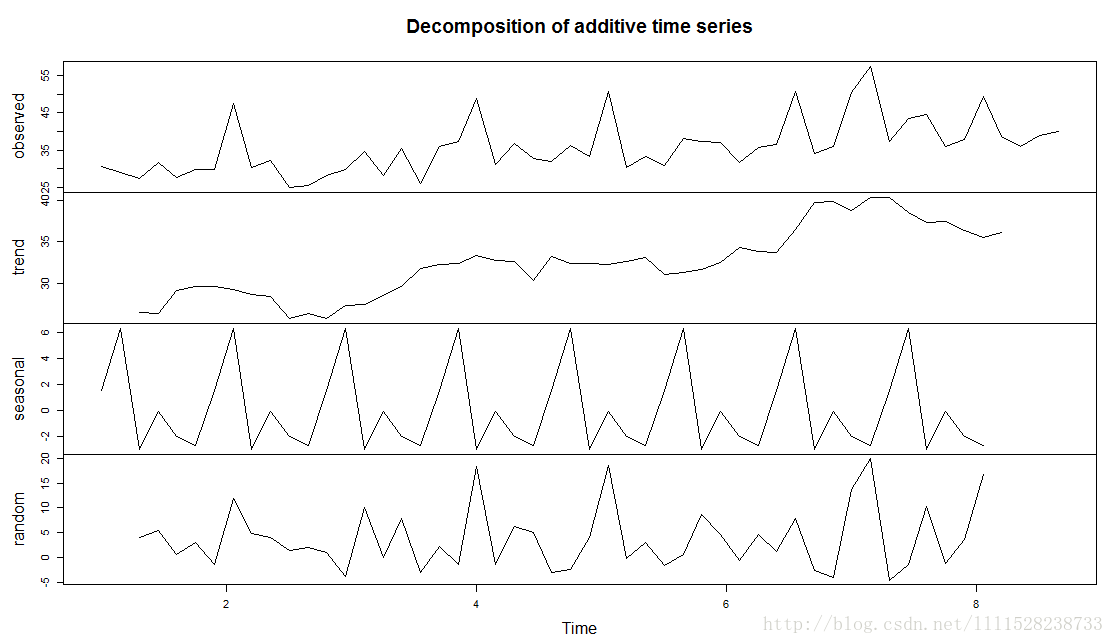

相关文章推荐
- BMDP为常规的统计分析提供了大量的完备的函数系统,如:方差分析(ANOVA)、回归分析(Regression)、非参数分析(Nonparametric Analysis)、时间序列(Times Series)等等。此外,BMDP特别擅于进行出色的生存分析(Survival Analysis )。许多年来,一大批世界范围内顶级的统计学家都曾今参与过BMDP的开发工作。这不仅使得BMDP的权威性得到
- Excel在统计分析中的应用—第十三章—时间序列分析-季节变动的测定
- 时间序列分析框架
- 时间序列分析
- 时间序列分析之一次指数平滑法
- 浅析时间序列分析之一次指数平滑法
- 时间序列分析中的ARMA,ARIMA模型整体综述
- 时间序列的相似性有没有办法分析呢
- R语言学习笔记(一):时间序列分析
- [时间序列分析][1]--平稳性,白噪声的检验
- R学习日记——时间序列分析之ARIMA模型预测
- BMDP为常规的统计分析提供了大量的完备的函数系统,如:方差分析(ANOVA)、回归分析(Regression)、非参数分析(Nonparametric Analysis)、时间序列(Times Series)等等。此外,BMDP特别擅于进行出色的生存分析(Survival Analysis )。许多年来,一大批世界范围内顶级的统计学家都曾今参与过BMDP的开发工作。这不仅使得BMDP的权威性得到
- [DataAnalysis]时间序列分析
- 时间序列分析——ARIMA模型
- 时间序列分析基础
- 应用时间序列分析(王燕)学习笔记3
- Python_Statsmodels包_时间序列分析_ARIMA模型
- Python数据分析——时间序列
- R语言实现金融数据的时间序列分析及建模
- python 金融应用(四)金融时间序列分析基础