第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
2017-07-25 11:52
330 查看
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url
一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过
记录url可以是缓存,或者数据库,如果保存数据库按照以下方式:
id URL加密(建索引以便查询) 原始URL
保存URL表里应该至少有以上3个字段
1、URL加密(建索引以便查询)字段:用来查询这样速度快,
2、原始URL,用来给加密url做对比,防止加密不同的URL出现同样的加密值
自动递归url
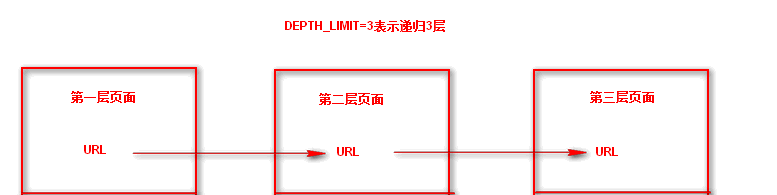
这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过
记录url可以是缓存,或者数据库,如果保存数据库按照以下方式:
id URL加密(建索引以便查询) 原始URL
保存URL表里应该至少有以上3个字段
1、URL加密(建索引以便查询)字段:用来查询这样速度快,
2、原始URL,用来给加密url做对比,防止加密不同的URL出现同样的加密值
自动递归url
# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from scrapy.selector import Selector
class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['hao.360.cn']
start_urls = ['https://hao.360.cn/']
def parse(self, response):
#这里做页面的各种获取以及处理
#递归查找url循环执行
hq_url = Selector(response=response).xpath('//a/@href') #查找到当前页面的所有a标签的href,也就是url
for url in hq_url: #循环url
yield scrapy.Request(url=url, callback=self.parse) #每次循环将url传入Request方法进行继续抓取,callback执行parse回调函数,递归循环
#这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层

相关文章推荐
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
- Scrapy爬虫教程之URL解析与递归爬取
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
- Scrapy爬虫教程之URL解析与递归爬取
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
- 解决支付宝WEB支付界面模块在Android上自动滑动到登录模块的问题
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
- IntelliJ IDEA 2017.3创建Web项目,解决无自动生成web.xml问题
- application Initialization设置导致处理程序ExtensionlessUrlHandler-Integrated-4.0在其模块列表中有一个错误模块问题的解决
- Android Webview中解决H5的音视频不能自动播放、只有声音没有图像的问题
- Eclipse下无法自动编译,或者WEB-INF/classes目录下没文件,编译失败的解决办法
- scrapy爬虫框架setting模块解析
- Python Scrapy 自动爬虫注意细节(2)
- 完美解决zencart SEO模块存在重复网址的问题
- j2ee的web项目怎么防止,重复提交的问题?(即点击了提交,后台新增了两条数据,也就是说,其实是点了多次提交,发起了多次http url,这样就插入了多条相同数据,但是主键id是不同的)
- Dynamics CRM webresource中的html页面url加参数后浏览报500错的解决方法
- 配置错误定义了重复的“system.web.extensions/scripting/scriptResourceHandler” 解决办法
- 配置错误定义了重复的“system.web.extensions/scripting/scriptResourceHandler” 解决办法
- python爬虫模块之URL管理器模块
- Retrofit(OKHttp)多BaseUrl情况下url实时自动替换完美解决方法