caffe中forward过程总结(2)
2017-07-22 21:25
127 查看
转载地址:http://blog.csdn.net/Buyi_Shizi/article/details/51506448
感谢作者总结!
第一层Inner Product void InnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
这层的输入是50x4x4,总共有800个输入,而输出的宽度是500,所以该层有500个神经元分别与输入进行全连接,每个神经元都有自己的权值向量,所以关于权值就有500x800个,还有就是该层一个batch中有64个样本。和前面卷积层类似,我们要做的就是用一次矩阵运算,得出关于各个神经元输入和权值矩阵相乘的结果。在caffe中矩阵的构造如下图所示:
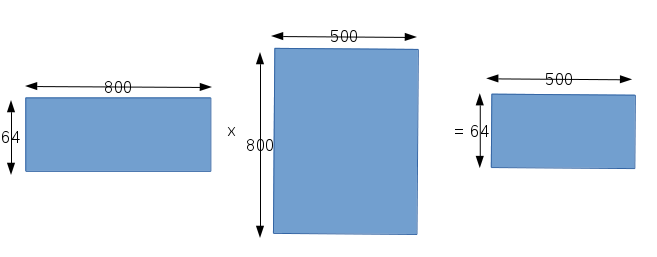
第一个矩阵表示输入数据,总共有64个50x4x4=800的数据;第二个矩阵表示权值矩阵,可以看出对于每一个神经元,都分别有800个权值参数,而500个神经元就有800x500个权值参数;第三个矩阵就是输出矩阵,对应一个batch中的64个样本,每个样本的宽度是500。bias的矩阵运算这里我们就不说了。
激活函数层void ReLULayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>&
bottom, const vector<Blob<Dtype>*>& top):
传统神经网络的每一层都有一个activation function,caffe中是把加权求和和激活函数分为两层,激活函数层就比较简单了,这一层激活函数层的输入是64x500,对应的输出也是64x500,所做的运算就是用relu函数对输入做个运算,关于为什么选取relu函数,这有很多考虑,这里暂且不深究。
第二层Inner Product void InnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
这层Inner Product的输入宽度是500,同时有64个样本;输出宽度是10,同时也有64个样本。和上面一样,我们也想用一次矩阵运算,得到64个样本的加权求和结果。矩阵的构造和上面也是类似的:
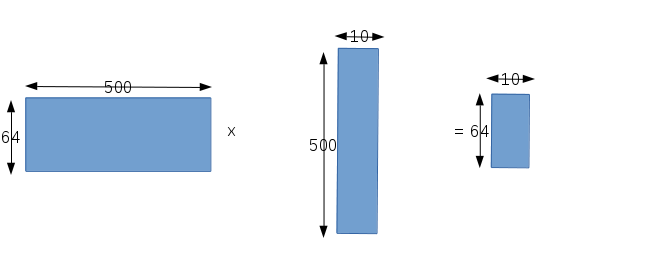
第一个矩阵表示输入,数据宽度500,总共64个样本,所以矩阵就是64x500;第二个矩阵表示权值矩阵,该层有10个神经元,用样,每个神经元和输入都是全连接,所以该层的权值参数总共有500x10个;第三个矩阵就表示最后的输出,输出宽度为10,样本数量为64;
激活函数层void SoftmaxWithLossLayer<Dtype>::Forward_cpu(const
vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
这一层的激活函数就比较特殊,因为该层采用了softmax回归,关于softmax在另一篇总结中有介绍,该激活函数把该层的10个输入看成是输入在每个标签上的打分,分数越高,说明输入越有可能输入对应的标签;而该层的输出是输入输入对应标签上的概率,该层可以分为两步,
第一步是利用该层的子层:softmax_layer_->Forward(softmax_bottom_vec_, softmax_top_vec_)获取输入在对应标签上的概率,关于输入是如何转化称概率的在softmax的总结中有介绍。
第二部是求取代价函数,代价函数其实对应的就是输入在正确标签上的概率,只不过为了计算和后面的优化简便取了log元算,我们的目的就是让输入在正确的标签上的概率最大,程序如下:
for (int i = 0; i < outer_num_; ++i){ // sample by sample
for (int j = 0; j < inner_num_; j++) {
const int label_value = static_cast<int>(label[i * inner_num_ + j]);
if (has_ignore_label_ && label_value == ignore_label_) {
continue;
}
DCHECK_GE(label_value, 0);
DCHECK_LT(label_value, prob_.shape(softmax_axis_));
loss -= log(std::max(prob_data[i * dim + label_value * inner_num_ + j],
Dtype(FLT_MIN))); // cost function
++count;
}
}
loss就是我们最终求取的代价函数。outer_num_对应的就是我们的样本数,意思就是我们会连续对一个batch中的64个样本求取代价函数,然后求取平均值作为这一次farward迭代的代价函数值。
至此,forward过程就结束了,接下来就是利用求取的代价函数再进行backward求取代价函数相对于网络中每一个参数的梯度,然后利用梯度更新权值。本文是以lenet网络训练为例,其他网络的forward过程和本文总结的大同小异,只是层数不同或者激活函数不同而已。
感谢作者总结!
第一层Inner Product void InnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
这层的输入是50x4x4,总共有800个输入,而输出的宽度是500,所以该层有500个神经元分别与输入进行全连接,每个神经元都有自己的权值向量,所以关于权值就有500x800个,还有就是该层一个batch中有64个样本。和前面卷积层类似,我们要做的就是用一次矩阵运算,得出关于各个神经元输入和权值矩阵相乘的结果。在caffe中矩阵的构造如下图所示:
第一个矩阵表示输入数据,总共有64个50x4x4=800的数据;第二个矩阵表示权值矩阵,可以看出对于每一个神经元,都分别有800个权值参数,而500个神经元就有800x500个权值参数;第三个矩阵就是输出矩阵,对应一个batch中的64个样本,每个样本的宽度是500。bias的矩阵运算这里我们就不说了。
激活函数层void ReLULayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>&
bottom, const vector<Blob<Dtype>*>& top):
传统神经网络的每一层都有一个activation function,caffe中是把加权求和和激活函数分为两层,激活函数层就比较简单了,这一层激活函数层的输入是64x500,对应的输出也是64x500,所做的运算就是用relu函数对输入做个运算,关于为什么选取relu函数,这有很多考虑,这里暂且不深究。
第二层Inner Product void InnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
这层Inner Product的输入宽度是500,同时有64个样本;输出宽度是10,同时也有64个样本。和上面一样,我们也想用一次矩阵运算,得到64个样本的加权求和结果。矩阵的构造和上面也是类似的:
第一个矩阵表示输入,数据宽度500,总共64个样本,所以矩阵就是64x500;第二个矩阵表示权值矩阵,该层有10个神经元,用样,每个神经元和输入都是全连接,所以该层的权值参数总共有500x10个;第三个矩阵就表示最后的输出,输出宽度为10,样本数量为64;
激活函数层void SoftmaxWithLossLayer<Dtype>::Forward_cpu(const
vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
这一层的激活函数就比较特殊,因为该层采用了softmax回归,关于softmax在另一篇总结中有介绍,该激活函数把该层的10个输入看成是输入在每个标签上的打分,分数越高,说明输入越有可能输入对应的标签;而该层的输出是输入输入对应标签上的概率,该层可以分为两步,
第一步是利用该层的子层:softmax_layer_->Forward(softmax_bottom_vec_, softmax_top_vec_)获取输入在对应标签上的概率,关于输入是如何转化称概率的在softmax的总结中有介绍。
第二部是求取代价函数,代价函数其实对应的就是输入在正确标签上的概率,只不过为了计算和后面的优化简便取了log元算,我们的目的就是让输入在正确的标签上的概率最大,程序如下:
for (int i = 0; i < outer_num_; ++i){ // sample by sample
for (int j = 0; j < inner_num_; j++) {
const int label_value = static_cast<int>(label[i * inner_num_ + j]);
if (has_ignore_label_ && label_value == ignore_label_) {
continue;
}
DCHECK_GE(label_value, 0);
DCHECK_LT(label_value, prob_.shape(softmax_axis_));
loss -= log(std::max(prob_data[i * dim + label_value * inner_num_ + j],
Dtype(FLT_MIN))); // cost function
++count;
}
}
loss就是我们最终求取的代价函数。outer_num_对应的就是我们的样本数,意思就是我们会连续对一个batch中的64个样本求取代价函数,然后求取平均值作为这一次farward迭代的代价函数值。
至此,forward过程就结束了,接下来就是利用求取的代价函数再进行backward求取代价函数相对于网络中每一个参数的梯度,然后利用梯度更新权值。本文是以lenet网络训练为例,其他网络的forward过程和本文总结的大同小异,只是层数不同或者激活函数不同而已。

相关文章推荐
- caffe中forward过程总结(1)
- caffe中forward过程总结
- caffe中forward过程总结 2
- caffe中backward过程总结
- caffe-ssd训练过程总结
- 配置CPU caffe全过程总结
- caffe中backward过程总结
- 深度学习 caffe 建自己的数据库 训练一个自创卷积神经网络 过程总结
- Ubuntu16.04 配置caffe过程总结
- caffe安装过程问题总结
- python 学习过程中自己总结的tips
- Caffe 实例 手写数字mnist训练与测试过程(Windows + CPU Only)
- C语言编译过程总结详解
- Linux USB 驱动开发(五)—— USB驱动程序开发过程简单总结
- 开发过程中遇到的问题总结
- sendRedirect和forward原理及区别总结
- AD RMS总结(工作过程,证书)
- Lucene学习总结之四:Lucene索引过程分析(3)
- caffe安装过程中的问题
- mysql 5.0存储过程学习总结