caffe中forward过程总结(1)
2017-07-22 20:59
288 查看
转载地址:http://blog.csdn.net/Buyi_Shizi/article/details/51504276
感谢作者总结!
caffe中最重要的两个部分就是forward和backward的过程,farward是根据输入数据正向预测输入属于哪一类;backward是根据输出的结果求得代价函数,然后根据代价函数反向求去其相对于各层网络参数的梯度的过程。我们先对farward过程做一下总结。
caffe中有两个过程会设计到farward,test和train,这里我们以train训练过程为例。
int train() caffe.cpp Line 181:
这是train的入口函数,train函数里的操作这里我们掠过,我们主要进入训练的主体函数solver->Solve()函数(Line 253)。void Solver<Dtype>::Solve()函数是训练网络的入口函数,而我们的训练的主体函数就是在Line 293的Step()函数。
训练主体函数void Solver<Dtype>::Step():
进入这个函数之后,我们首先就要进行迭代的循环,以lenet网络训练为例,由于lenet是采用stochastic的训练方式,所以就必须进行多次迭代,当然每次迭代循环又会采用多个样本(batch)进行训练。在循环体内,程序就回进入forward过程了。程序如下:
for (int i = 0; i < param_.iter_size(); ++i) { // iter_size=1 indicate update parameters for every sample
loss += net_->ForwardBackward(); // forward and backward process
}
loss /= param_.iter_size();
3. forward过程:
在进入net_->ForwardBackward()函数(net.hpp Line 85)之后,程序会先进入Forward函数:Forward(&loss),然后再会进入Backward()函数。forward过程是一层一层来进行的。在Net数据结构体中有一个存储有每层Layer指针的vector,forward过程就回根据这个vector在每层layer中进行循环。当前层的forward就是由当前层输入通过卷积或是矩阵运算或者别的运算求输出,得到的输出作为下一层的输入,然后继续下一层的forward过程。forward在每层的循环过程如下:
for (int i = start; i <= end; ++i) { // forward for every layer, 11 layers total
// LOG(ERROR) << "Forwarding " << layer_names_[i];
Dtype layer_loss = layers_[i]->Forward(bottom_vecs_[i], top_vecs_[i]);
loss += layer_loss;
if (debug_info_) { ForwardDebugInfo(i); }
}
4.每层的forward过程:
由于每层的作用不一样,所以每层的forward过程也是不一样的,这里我们以lenet为例,介绍几个重要的层的forward操作。
a.卷积层void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const
vector<Blob<Dtype>*>& top):
bottom代表输入的数据集合,top代表输出的数据集合,这两个数据结构是blob结构,关于blob结构,在另一篇总结中有总结。卷 积的具体计算过程这里我深究。由于训练是以batch为基本单位,在lenet中一个batch是含有64个样本,当前类下的this->num_表 示就是一个batch中含有的样本数量,所以卷积也要根据样本数量进行循环,程序如下:
for (int n = 0; n < this->num_; ++n) { // this->num: batch size
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_); // base_conv_layer.cpp:259 do convlution bottom_dim_:number of pixel of input, top_dim_:number of pixel of output with many convlution kernels
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias); // scale bias if request and add bias to conv result
}
}
程序首先会用weight矩阵和输入bottom向乘,对应的就是forward_cpu_gemm()函数;然后就是对bias进行处理,bias程序会根据情况决定是否对bias进行scale,即放大还是缩小。我们首先进入forward_cpu_gemm()函数:这个函数就是进行卷积运算的主要函数,caffe中的卷积运算是用blas库完成的,blas库只是完成矩阵操作,具体到卷积时怎么构造矩阵是caffe本身的程序做的。我们先来看一下caffe是怎么构造卷积矩阵的。
以lenet为例,在该层卷积之前,输入数据是28×28的,该层的卷积核是5x5,那么最后卷积的输出应该是24x24。但是当前卷积层有20个卷积核,而且我现在想只调用一次blas的矩阵函数,就能完成20个卷积核对28x28图像的全部卷积函数。caffe是这样处理的,如下图所示

程序先把20个不同的卷积核放在一个矩阵里,矩阵的每一行表示每个卷积核的所有系数,即每个卷积核都是按行展开了;然后对于输入像素,该卷积层只有一张输入像素,程序会把每个卷积核的不同位置上的25个像素拍成一列,对于5x5卷积核卷积28x28的图片,最后输出是24x24的尺寸,我们就要为每个卷积核构造576列数据,分别对应不同位置上的25个对应的像素;最后的输出就会变成20x576,其中20表示20个卷积核,576表示每个卷积核的输出尺寸,即24x24。
每个卷积核的bias只有一个值,但是对于每个卷积核在图像上的不同位置,我们可能要对其进行scale操作,这就需要576个scale系数,最后输出是20x576,然后和weight卷积后的结果相加就可以得出最终的结果了。
为什么要这样设计,我理解的是,是为了一次卷积运算就可以把20个卷积核对图像的卷积操作一次计算出来。上面只是第一层卷积层,后面卷积层的处理和这相似,但由于输入数据的个数不一样,矩阵构造的过程又有稍微不同。
b.pooling层void PoolingLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
pooling层的作用就是下采样,这里采用的是PoolMethid_MAX方式,即在Pooling核的区域选择出最大的值作为当前区域的值,pooling层的运算比较简单,这里不再深究。
c.2级卷积层void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
经过下采样之后,图像尺寸变成12x12,但是有20个12x12的图像数据,因为对应有20个卷积核,这一层又需要构造卷积矩阵,我们这里权值相乘的矩阵的构造,如下图所示:
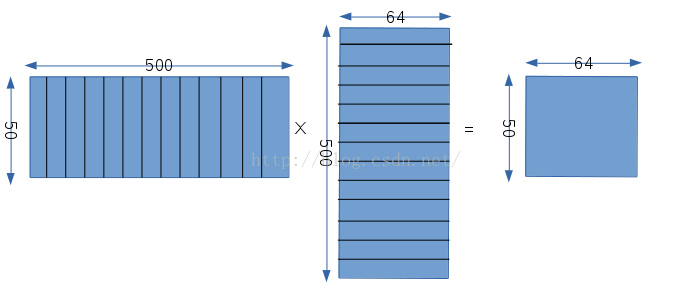
首先第一个矩阵同样表示权值矩阵,50表示这一层有50个卷积核,500=25×20,这一层的卷积核是5x5,然后这一层的输入有20个不同的12x12的图像,所以500就表示每个卷积核分别和20个不同的输入的对应的位置相乘,然后再把所有的结果相加,从这我们可以看出,这一层的每一个卷积核都是和所有的数据相连接的;第二个矩阵表示输入矩阵,同样由于卷积核的大小是5x5,输入尺寸是12x12,所以输出的结果是8x8,即一个卷积核在一个数据上卷积了64次,所以对于每一幅输入图像,我们都要构造64个对应的数,而又因为输入是有20张图像的,所以每一次卷积都会设计25x20个数据,所以输入矩阵有500行,64列;输出矩阵自然就是50x64,50对应卷积核的个数,64对应每个卷积核的输出。
d.2级pooling层void PoolingLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
这也只是一个下采样层,对输入8x8的图像进行下采样,输出就变成4x4个,都是有50个。
以上就是caffe中forward过程的和卷积层相关的forward具体过程,在卷积层后还有InnerProduct层以及求取代价函数层,这在另一篇有总结。
感谢作者总结!
caffe中最重要的两个部分就是forward和backward的过程,farward是根据输入数据正向预测输入属于哪一类;backward是根据输出的结果求得代价函数,然后根据代价函数反向求去其相对于各层网络参数的梯度的过程。我们先对farward过程做一下总结。
caffe中有两个过程会设计到farward,test和train,这里我们以train训练过程为例。
int train() caffe.cpp Line 181:
这是train的入口函数,train函数里的操作这里我们掠过,我们主要进入训练的主体函数solver->Solve()函数(Line 253)。void Solver<Dtype>::Solve()函数是训练网络的入口函数,而我们的训练的主体函数就是在Line 293的Step()函数。
训练主体函数void Solver<Dtype>::Step():
进入这个函数之后,我们首先就要进行迭代的循环,以lenet网络训练为例,由于lenet是采用stochastic的训练方式,所以就必须进行多次迭代,当然每次迭代循环又会采用多个样本(batch)进行训练。在循环体内,程序就回进入forward过程了。程序如下:
for (int i = 0; i < param_.iter_size(); ++i) { // iter_size=1 indicate update parameters for every sample
loss += net_->ForwardBackward(); // forward and backward process
}
loss /= param_.iter_size();
3. forward过程:
在进入net_->ForwardBackward()函数(net.hpp Line 85)之后,程序会先进入Forward函数:Forward(&loss),然后再会进入Backward()函数。forward过程是一层一层来进行的。在Net数据结构体中有一个存储有每层Layer指针的vector,forward过程就回根据这个vector在每层layer中进行循环。当前层的forward就是由当前层输入通过卷积或是矩阵运算或者别的运算求输出,得到的输出作为下一层的输入,然后继续下一层的forward过程。forward在每层的循环过程如下:
for (int i = start; i <= end; ++i) { // forward for every layer, 11 layers total
// LOG(ERROR) << "Forwarding " << layer_names_[i];
Dtype layer_loss = layers_[i]->Forward(bottom_vecs_[i], top_vecs_[i]);
loss += layer_loss;
if (debug_info_) { ForwardDebugInfo(i); }
}
4.每层的forward过程:
由于每层的作用不一样,所以每层的forward过程也是不一样的,这里我们以lenet为例,介绍几个重要的层的forward操作。
a.卷积层void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const
vector<Blob<Dtype>*>& top):
bottom代表输入的数据集合,top代表输出的数据集合,这两个数据结构是blob结构,关于blob结构,在另一篇总结中有总结。卷 积的具体计算过程这里我深究。由于训练是以batch为基本单位,在lenet中一个batch是含有64个样本,当前类下的this->num_表 示就是一个batch中含有的样本数量,所以卷积也要根据样本数量进行循环,程序如下:
for (int n = 0; n < this->num_; ++n) { // this->num: batch size
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_); // base_conv_layer.cpp:259 do convlution bottom_dim_:number of pixel of input, top_dim_:number of pixel of output with many convlution kernels
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias); // scale bias if request and add bias to conv result
}
}
程序首先会用weight矩阵和输入bottom向乘,对应的就是forward_cpu_gemm()函数;然后就是对bias进行处理,bias程序会根据情况决定是否对bias进行scale,即放大还是缩小。我们首先进入forward_cpu_gemm()函数:这个函数就是进行卷积运算的主要函数,caffe中的卷积运算是用blas库完成的,blas库只是完成矩阵操作,具体到卷积时怎么构造矩阵是caffe本身的程序做的。我们先来看一下caffe是怎么构造卷积矩阵的。
以lenet为例,在该层卷积之前,输入数据是28×28的,该层的卷积核是5x5,那么最后卷积的输出应该是24x24。但是当前卷积层有20个卷积核,而且我现在想只调用一次blas的矩阵函数,就能完成20个卷积核对28x28图像的全部卷积函数。caffe是这样处理的,如下图所示
程序先把20个不同的卷积核放在一个矩阵里,矩阵的每一行表示每个卷积核的所有系数,即每个卷积核都是按行展开了;然后对于输入像素,该卷积层只有一张输入像素,程序会把每个卷积核的不同位置上的25个像素拍成一列,对于5x5卷积核卷积28x28的图片,最后输出是24x24的尺寸,我们就要为每个卷积核构造576列数据,分别对应不同位置上的25个对应的像素;最后的输出就会变成20x576,其中20表示20个卷积核,576表示每个卷积核的输出尺寸,即24x24。
每个卷积核的bias只有一个值,但是对于每个卷积核在图像上的不同位置,我们可能要对其进行scale操作,这就需要576个scale系数,最后输出是20x576,然后和weight卷积后的结果相加就可以得出最终的结果了。
为什么要这样设计,我理解的是,是为了一次卷积运算就可以把20个卷积核对图像的卷积操作一次计算出来。上面只是第一层卷积层,后面卷积层的处理和这相似,但由于输入数据的个数不一样,矩阵构造的过程又有稍微不同。
b.pooling层void PoolingLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
pooling层的作用就是下采样,这里采用的是PoolMethid_MAX方式,即在Pooling核的区域选择出最大的值作为当前区域的值,pooling层的运算比较简单,这里不再深究。
c.2级卷积层void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
经过下采样之后,图像尺寸变成12x12,但是有20个12x12的图像数据,因为对应有20个卷积核,这一层又需要构造卷积矩阵,我们这里权值相乘的矩阵的构造,如下图所示:
首先第一个矩阵同样表示权值矩阵,50表示这一层有50个卷积核,500=25×20,这一层的卷积核是5x5,然后这一层的输入有20个不同的12x12的图像,所以500就表示每个卷积核分别和20个不同的输入的对应的位置相乘,然后再把所有的结果相加,从这我们可以看出,这一层的每一个卷积核都是和所有的数据相连接的;第二个矩阵表示输入矩阵,同样由于卷积核的大小是5x5,输入尺寸是12x12,所以输出的结果是8x8,即一个卷积核在一个数据上卷积了64次,所以对于每一幅输入图像,我们都要构造64个对应的数,而又因为输入是有20张图像的,所以每一次卷积都会设计25x20个数据,所以输入矩阵有500行,64列;输出矩阵自然就是50x64,50对应卷积核的个数,64对应每个卷积核的输出。
d.2级pooling层void PoolingLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top):
这也只是一个下采样层,对输入8x8的图像进行下采样,输出就变成4x4个,都是有50个。
以上就是caffe中forward过程的和卷积层相关的forward具体过程,在卷积层后还有InnerProduct层以及求取代价函数层,这在另一篇有总结。

相关文章推荐
- caffe中forward过程总结(2)
- caffe中forward过程总结
- caffe中forward过程总结 2
- caffe中backward过程总结
- 配置CPU caffe全过程总结
- caffe-ssd训练过程总结
- 深度学习 caffe 建自己的数据库 训练一个自创卷积神经网络 过程总结
- Ubuntu16.04 配置caffe过程总结
- caffe中backward过程总结
- caffe安装过程问题总结
- 实习过程中linux相关开发学习总结(二)
- Xampp安装过程总结(主要针对mysql和phpmyadmin)-很全的了
- Android Multimedia框架总结(十六)Camera2框架之openCamera及session过程
- Ubuntu16.04下基于Docker的Caffe-GPU版本环境搭建总结
- mysql 存储过程学习总结
- 某服务器安全事件分析过程分析和总结
- JAVASE总结--06(面向过程、面向对象、内存分析)
- SCI投稿过程总结、投稿状态解析、拒稿后处理对策及接受后期相关问答综合荟萃目录
- mysql 5.0存储过程学习总结
- 公司app出现异常版本与使用记录,怀疑app被换壳,下面总结换课过程,保护过程下节更新