基于协同过滤的推荐系统
2017-07-21 19:05
309 查看
1. 前言
推荐系统作为如今最有生产力的工业级系统,随着人工智能与机器学习的发展,逐渐成熟起来。日常生活中,今日头条的个性化推荐新闻模式,使得以百度为首的传统搜索模式受到了威胁,因为它改变了知识的获取方式,达到了由“我去找”到“你送来”的转变。那么这么神奇的推荐系统,是如何实现的呢?我们今天就管中窥豹一番。
2. 基于协同过滤的推荐系统
2.1 简介
基于协同过滤的推荐系统分为二类,分别是基于用户的和基于物品的。基于用户的协同过滤推荐的基本原理是,根据所有用户对物品或者信息的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,在一般的应用中是采用计算“K- 邻居”的算法;然后,基于这 K 个邻居的历史偏好信息,为当前用户进行推荐。下图给出了原理图。

上图示意出基于用户的协同过滤推荐机制的基本原理,假设用户 A 喜欢物品 A,物品 C,用户 B 喜欢物品 B,用户 C 喜欢物品 A ,物品 C 和物品 D;从这些用户的历史喜好信息中,我们可以发现用户 A 和用户 C 的口味和偏好是比较类似的,同时用户 C 还喜欢物品 D,那么我们可以推断用户 A 可能也喜欢物品 D,因此可以将物品 D 推荐给用户 A。
基于用户的协同过滤推荐机制和基于人口统计学的推荐机制都是计算用户的相似度,并基于“邻居”用户群计算推荐,但它们所不同的是如何计算用户的相似度,基于人口统计学的机制只考虑用户本身的特征,而基于用户的协同过滤机制可是在用户的历史偏好的数据上计算用户的相似度,它的基本假设是,喜欢类似物品的用户可能有相同或者相似的口味和偏好。
基于项目的协同过滤推荐的基本原理也是类似的,只是说它使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户,下图很好的诠释了它的基本原理。

假设用户 A 喜欢物品 A 和物品 C,用户 B 喜欢物品 A,物品 B 和物品 C,用户 C 喜欢物品 A,从这些用户的历史喜好可以分析出物品 A 和物品 C 时比较类似的,喜欢物品 A 的人都喜欢物品 C,基于这个数据可以推断用户 C 很有可能也喜欢物品 C,所以系统会将物品 C 推荐给用户 C。
与上面讲的类似,基于项目的协同过滤推荐和基于内容的推荐其实都是基于物品相似度预测推荐,只是相似度计算的方法不一样,前者是从用户历史的偏好推断,而后者是基于物品本身的属性特征信息。
同时协同过滤,在基于用户和基于项目两个策略中应该如何选择呢?其实基于项目的协同过滤推荐机制是 Amazon 在基于用户的机制上改良的一种策略,因为在大部分的 Web 站点中,物品的个数是远远小于用户的数量的,而且物品的个数和相似度相对比较稳定,同时基于项目的机制比基于用户的实时性更好一些。但也不是所有的场景都是这样的情况,可以设想一下在一些新闻推荐系统中,也许物品,也就是新闻的个数可能大于用户的个数,而且新闻的更新程度也有很快,所以它的形似度依然不稳定。所以,其实可以看出,推荐策略的选择其实和具体的应用场景有很大的关系。
关于推荐系统,IBM公司早在6年前就已经发布了相关推荐引擎的文章,具体的可以去看《IBM的推荐引擎》。
另外,Mahout已经完全封装了推荐算法,有兴趣的话,可以查阅《Mahout推荐算法API详解》
2.2 核心
无论是基于用户的,还是基于物品的,所谓协同过滤的协同,体现在哪里呢?就是需要依靠其他样本一起对目标样本进行协同过滤。那么如何体现出这个呢,如果是基于用户的协同过滤系统,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐;如果是基于物品的协同过滤系统,通过用户对不同物品的评分来评测物品之间的相似性,然后基于物品之间的相似性做出推荐。也就是说,如果A用户喜欢1物品和2物品,B用户也喜欢1物品和2物品,那么1物品和2物品的相似度就比较高,A用户和B用户之间的相似度也比较高。
当然如果是想基于物品特性的话,比如1物品是肉类,2物品也是肉类,1物品是生鲜,2物品也是生鲜等,那么是基于内容的推荐,要在基于物品的协同过滤上还要加上一层分类与聚类操作。这点我们放在最后去讲。
可以看出,协同过滤的推荐系统主要是基于相似度算法的,相似度这里提供3种常用的相似度计算方法,分别是欧氏距离相似度、皮尔逊相关系数和余弦相似度,下面给出实现代码:
#归一化的欧氏距离相似度 def eulidSim(inA,inB): return 1.0/(1.0+la.norm(inA-inB)) #归一化的皮尔逊相似度 def pearsSim(inA,inB): if len(inA)<3:return 1.0 return 0.5+0.5*corrcoef(inA,inB,rowvar=0)[0][1] #归一化的余弦相似度 def cosSim(inA,inB): num=float(inA.T*inB) denom=la.norm(inA)*la.norm(inB) return 0.5+0.5*(num/denom);
其实有十余种相似度方法可以使用,详见《相似度算法综述》。
2.3基于物品的协同过滤
之所以我们要讲基于物品的协同过滤,是因为物品的数量一般要小于用户的数量。这样的话,每次遍历的时间要少上许多,下面我们给出一个基于物品的协同过滤系统,它是餐厅用来推荐用餐的。首先,我们给出整个系统的流程。
推荐系统的工作过程是:给定一个用户,系统会为此用户返回N个最好的推荐菜。为了实现这一点,我们需要做到:
寻找用户没有评级的菜肴,即在用户-物品矩阵中的0值(事实上,实际生产中,比较困难的一步就在于此)。
在用户没有评级的所有物品中,对每个物品预计一个可能的评级分数。这就是说,我们认为用户可能会对物品的打分(这是相似度计算的初衷)。
对这些物品的评分从高到低进行排序,返回前N个物品。
实际上就是做这三件事,但是这三件事到底该怎么做?如果我使用一对代码来解释,那么显然很困难。因此我决定使用例子的手段来解释一下接下来的实现过程。
首先,你要有个一用户-物品矩阵,如下表所示。
| 下用户右物品 | W0 | W1 | W2 | W3 | W4 |
|---|---|---|---|---|---|
| U1 | 2 | 0 | 0 | 4 | 4 |
| U2 | 5 | 5 | 5 | 3 | 3 |
| U3 | 2 | 4 | 2 | 1 | 2 |
首先,我们需要找到是0的列,也就是W1列,决定要预测的值为D(0,1)。
然后我们去查找其他物品有哪个是用户同时对另一物品和待评价物品同时做出评价的。例如这里就是找到了W0和W1都是由B和C都进行了评价。
接着,对W0和W1同时非零的评价所形成的向量进行相似度计算,可以用上述的任何一种相似度计算方法。
最后把获得的相似度S和W0的U1评分相乘,就得到了基于W1的一个参考相似度,然后依次把W3,W4都计算后,全部相加后,再除以所有相似度,就得到了U1对于W1的参考分。这里就体现了协同过滤,也就是使用W0,W4,W5进行协同过滤。所以这是基于物品的系统过滤。
下面,我们给出实现代码:
def standEst(dataMat, user, simMeas, item): n = shape(dataMat)[1] simTotal = 0.0; ratSimTotal = 0.0 #对于每一个物品来讲 for j in range(n): userRating = dataMat[user,j] #如果没有标记过,就废弃 if userRating == 0: continue #寻找所有共同标记的行 overLap = nonzero(logical_and(dataMat[:,item].A>0, \ dataMat[:,j].A>0))[0] if len(overLap) == 0: similarity = 0 #计算相似度 else: similarity = simMeas(dataMat[overLap,item], \ dataMat[overLap,j]) print 'the %d and %d similarity is: %f' % (item, j, similarity) #总相似度 simTotal += similarity #总评分度 ratSimTotal += similarity * userRating if simTotal == 0: return 0 #最终结果 else: return ratSimTotal/simTotal #这是推荐主程序 def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst): #找到未标记的物品 unratedItems = nonzero(dataMat[user,:].A==0)[1]#find unrated items if len(unratedItems) == 0: return 'you rated everything' itemScores = [] for item in unratedItems: estimatedScore = estMethod(dataMat, user, simMeas, item) itemScores.append((item, estimatedScore)) #取前N个 return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N]
2.4 优化
上面那个用户只有3个,基本上是秒出相似度,但是试想一下,如果用户数目太多,那么在计算矩阵相似度的时候就会非常的慢。这就需要用到降维技术,还记得上一章中,我们讲解的两个线性降维方法么,一个LDA降维,一个PCA降维,这里我们使用的是SVD降维,它是PCA降维的一种具体实现。下面我们还是以上面例子,继续进行优化。2.4.1 SVD降维
其实SVD降维技术,就是奇异值分解,这个在线性代数的时候就已经讲过了,但是讲的非常浅显。实际上,奇异值的求解过程还是比较复杂的,喜欢公式推导的可以参见《奇异值分解原理详解及推导》,我们这里只介绍SVD的意义与实现。2.4.2 SVD的意义
奇异值分解的过程非常复杂,我在这里不再赘述,我们只讲一下它到底是干嘛的。奇异值分解的过程最终可以得到这样一个结果:DataM×N≈UM×r∑r×rVTr×N
其中UM×r称作是左矩阵,它是正交的,∑r×r则是传说中的奇异值矩阵,它是对角矩阵,对角线上就是该矩阵的奇异值,奇异值从小到大排列,其值为Data′×Data的特征值的平方根(Data’表示Data的转置矩阵)。
r就是我们要压缩的部分,一般来讲r都比较小,大概只有原矩阵大小的10%左右的奇异值就可以含有整个矩阵90%的信息,也就是说只需要原有的十分之一的空间就可以还原整个矩阵,因此我们把奇异值矩阵看做是原矩阵的压缩。
正常来讲,一个矩阵的奇异值分解如下图:
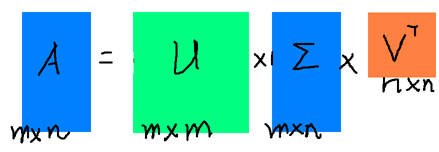
但是最后我们使用的是前r个奇异值,因此就变成了这么小的:
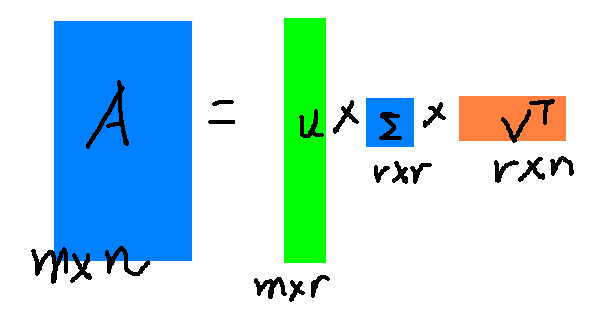
肉眼是可见它变小了。而它的几何意义可以参见《奇异值分解的几何意义》。
2.4.3 SVD的实现
虽然很难以理解并且很难实现求解过程,但是好在numpy包中自带这个SVD求解,它最终返回的是一个对角矩阵,对角线上即是奇异值,并且按照从大到小的顺序排列的。from numpy import * #U是左矩阵,VT是右矩阵,Sigma是奇异值矩阵。 U,Sigma,VT=linalg.svd(Matrix)
具体的可以参见《奇异值分解及其应用》。
2.4.4 SVD的应用
那么这个怎么用在我们刚才的那个例子中呢?详见下面代码:def svdEst(dataMat, user, simMeas, item): n = shape(dataMat)[1] simTotal = 0.0; ratSimTotal = 0.0 U,Sigma,VT = la.svd(dataMat) #获得了一个4维的奇异值矩阵 Sig4 = mat(eye(4)*Sigma[:4]) #arrange Sig4 into a diagonal matrix #转换后的矩阵,它的好处就在于可以把一个N*N的矩阵转换为一个N*4的矩阵。 xformedItems = dataMat.T * U[:,:4] * Sig4.I #create transformed items for j in range(n): userRating = dataMat[user,j] if userRating == 0 or j==item: continue similarity = simMeas(xformedItems[item,:].T,\ xformedItems[j,:].T) print 'the %d and %d similarity is: %f' % (item, j, similarity) simTotal += similarity ratSimTotal += similarity * userRating if simTotal == 0: return 0 else: return ratSimTotal/simTotal
2.5 挑战
但是尽管SVD可以帮助我们解决大数据集,但是推荐引擎仍然面临一个问题,就是如何在缺乏数据时给出好的推荐。这成为冷启动问题,处理起来十分困难,一般用基于内容的推荐来解决。
相关文章推荐
- 基于用户的协同过滤(user-based CF)推荐系统【1】
- 基于协同过滤构建简单推荐系统
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- 【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- 基于模糊聚类和协同过滤的混合推荐系统
- 【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- 推荐系统入门(协同过滤 基于内容 基于用户 基于项目 )
- 第1章:阿里云机器学习实践之路 / 第3节:推荐系统--基于协同过滤的商品推荐
- 论文笔记] Amazon推荐系统——基于item的协同过滤
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- 基于用户的协同过滤(user-based CF)推荐系统【2】
- 基于协同过滤的推荐系统
- 基于协同过滤的推荐系统
- 基于协同过滤的SVD的推荐系统
- 基于协同过滤的推荐系统
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- 推荐系统 基于用户和基于物品的协同过滤 (推荐系统实践读书笔记)
- 推荐系统简介——基于协同过滤的推荐