开始学习吧,《算法》:动态连通性练习
2017-07-21 00:00
295 查看
摘要: 我看的《算法》是第4版的电子书,在网上能很容易的找到免费下载。这里就不会对内容做过多分析,感兴趣的小伙伴们可以去下载一本学习下。
因为源书中的示例使用的是java语言,额,,怎么说呢。反正就是我不会,但是还是阅读还是没问题的。这里使用swift实现了下书中的示例代码,并且自己做了一些小的测试。
《算法》中对动态连通性所提供的最原始的算法是quick-find算法。最直接,最好理解。
这里使用swift对quick-find简单的实现:
在这次算法的联系中 我声明了一个全局变量用来记录访问数组元素和给数组元素赋值的次数access_count:
自己准备了一个数组array:[(Int,Int)],用来测试将0~num个触点连接成一个连通分量:
※这个准备的数据主要考虑的是生成比较简单,可以通过代码根据num的不同生成对应的测试数据。只能大体上验证动态连通性不同算法的运行情况,并不能作为详细测试的数据(因为不同的算法的最佳情况和最坏情况有所不同,这里就不再一一的提供测试数据)。
这里我们很容易发现union方法每次将两个触点连通在一起的时候都需要遍历数组,那么这个算法具体执行的效果如何呢?
首先记录开始计算之前的时间和完成计算的时间,得到完成计算的耗时;
由于实现动态连通性的API都相同只是内部实现有差异,所以后文不再展示实验代码。。。
※本次测试的数据都是 测试代码在我的小mini上运行而得来的。因为算法的不同实现有很大的差异,计算次数和运行的时间差异都很大。这里每种不同的实现都是只运行一遍并没有运行多次取平均值。。。(就似懒)
10个触点的时候,访问数组135次时间也很短。不错。100个也还行,1000次 马马虎虎吧,再往后 就不能忍受了。
这是我们按照书中的思路实现了quick-union算法,这个算法的思路就是解决union方法中数组遍历所产生的性能问题。
我们发现quick-union算法的union方法变得简单了很多,但是find方法引入了一个while循环。不过这个循环不像quick-find算法中的循环那样每次都会遍历整个数组,这个循环最佳的情况是只执行一次最坏的情况是执行num-1次。那么我们继续用上面的测试方法测试一下吧;
通过这个简单的测试十万个触点的时候不论是访问数组的次数还是测试运行的时间都有了很大的提升。一百万个触点的测试我的小mini也可以轻松的胜任了。但是这个算法还能不能做进一步的提升呢?
我们发现这个quick-union算法里除了find方法其他的方法都很简单,那么我们着重的看下find方法。这个算法里每次对两个触点进行链接的时候都是将一个触点指向另一个被连接的触点,这样每个连通分量都可以看做是一个树状的链接结构(如下图)。
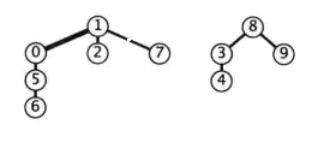
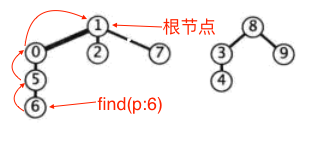
每次执行find方法的时候都会根据当前触点所在的深度不同执行不同的次数。那么我们能不能让我们连通分量所生成的树状结构的深度更小呢?quick-union算法每次联通两个触点的union(p:Int,q:Int)方法都是单纯的将p指向q或者将q指向p,这时我们在将两个触点链接在一起的时候可以考虑固定的将深度较浅的连通分量指向较深的连通分量。这就引出了后续的加权quick-union算法:
我们在quick-union算法的基础上添加了一个数组sz:[Int]用来记录个个连通分量的深度,在两个触点执行union的时候始终将深度较浅的指向深度较深的分量的根节点。这样产生的新的连通分量就可以有更浅的树状结构,在执行find方法的时候while循环执行的次数也会相对应的减少;
关于WeightedQuick-Union算法我并没有继续使用上面生成的数据做测试。因为当我们发挥想象力试想下继续测试所产生的连通分量会有怎么样的树状结构时,我们就会发现我们的测试数据所产生的结果证实WeightedQuickUnion算法的最佳结果他产生的树桩结构应该是所有的触点都指向同一个根节点(如下图)。
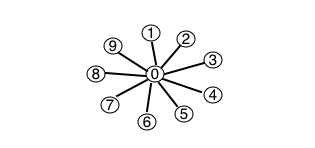
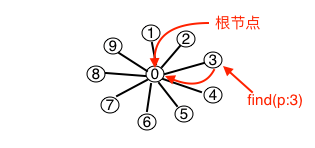
WeightedQuickUnion算法的最坏的情况是所有执行union操作的两个触点所在的分量深度都一样。同样的我们也可以预想到,因为引入了一个新的数组,那么这个算法在执行较少的数据的时候势必不如quick-union算法。但是当num逐渐的增大的时候加权quick-union算法的优势将逐渐的显现出来。
※我再这两次的测试中发现不同的算法在处理少量数据的时候性能差距都是可接受的,我们在移动端开发的时候所处理的数据都是非常有限的。这使我们在工作中可以选择更好理解的算法(虽然在性能上有所欠缺但是因为简单所以更好维护)。但是这并不能成为我们拒绝学习的理由,本人这次学习《算法》的目的是为拓展自己的思维能力。再说了谁也不知道以后的服务器会不会安在手机上。。。
昨天只看了这么多,今天继续。坚持,我啃啃啃!
因为源书中的示例使用的是java语言,额,,怎么说呢。反正就是我不会,但是还是阅读还是没问题的。这里使用swift实现了下书中的示例代码,并且自己做了一些小的测试。
《算法》中对动态连通性所提供的最原始的算法是quick-find算法。最直接,最好理解。
这里使用swift对quick-find简单的实现:
quick-find:
class UF {
private var count:Int
public var ids:[Int]
/**
查看 共有多少个 连通分量
*/
public func counts() ->Int {
return count;
}
init(N:Int) {
count = N
ids = [Int]()
for i in 0..<N {
ids.append(i)
}
}
///将两个 触点 链接 起来
public func union(p:Int,q:Int)->Void {
let pID = find(p: p)
let qID = find(p: q)
if pID == qID {
///已经处于同一个联通分量,不做处理;
return
}
for i in 0..<ids.count {
if qID == ids[i] {
ids[i] = pID
}
}
count = count - 1
}
///查看 给定 触点 所属的连通分量 的标识符
public func find(p:Int) -> Int {
return ids[p]
}
///查看 两个 触点是否属于同一个连通分量
public func connected(p:Int,q:Int)->Bool {
return find(p: p) == find(p: q)
}
}在这次算法的联系中 我声明了一个全局变量用来记录访问数组元素和给数组元素赋值的次数access_count:
var access_count = 0
自己准备了一个数组array:[(Int,Int)],用来测试将0~num个触点连接成一个连通分量:
※这个准备的数据主要考虑的是生成比较简单,可以通过代码根据num的不同生成对应的测试数据。只能大体上验证动态连通性不同算法的运行情况,并不能作为详细测试的数据(因为不同的算法的最佳情况和最坏情况有所不同,这里就不再一一的提供测试数据)。
let num = 10///声明了一个变量,方便测试在不同的数量级下算法执行的情况;
var array = [(Int,Int)]()
for i in 0..<num-1 {
let item = (i,i+1)
array.append(item)
}
///array : [(0,1),(1,2),(2,3),(3,4),(4,5),(5,6),(6,7),(7,8),...]这里我们很容易发现union方法每次将两个触点连通在一起的时候都需要遍历数组,那么这个算法具体执行的效果如何呢?
首先记录开始计算之前的时间和完成计算的时间,得到完成计算的耗时;
由于实现动态连通性的API都相同只是内部实现有差异,所以后文不再展示实验代码。。。
let statreTime = NSDate()
let uf = UF(N: num)
for (a,b) in array {
if uf.find(p: a) == uf.find(p: b) {
continue
}
uf.union(p: a, q: b)
}
let endTime = NSDate()/** quick-find num : 触点的个数 access_count:连通为一个分量需要对ids数组操作的次数 time:耗时(秒) num access_count(次) time(秒) 10 135(一百) 0.000606060028076172 100 10395(一万) 0.000803947448730469 1000 1003995(一百万) 0.0304648876190186 10000 100039995(一亿) 3.14806509017944 100000 10000399995(一百亿) 285.034122943878 1000000 (心疼我的小mini没做) */
※本次测试的数据都是 测试代码在我的小mini上运行而得来的。因为算法的不同实现有很大的差异,计算次数和运行的时间差异都很大。这里每种不同的实现都是只运行一遍并没有运行多次取平均值。。。(就似懒)
10个触点的时候,访问数组135次时间也很短。不错。100个也还行,1000次 马马虎虎吧,再往后 就不能忍受了。
这是我们按照书中的思路实现了quick-union算法,这个算法的思路就是解决union方法中数组遍历所产生的性能问题。
quick-union:
class Quick_Union: NSObject {
private var count:Int
public var ids:[Int]
init(N:Int) {
count = N
ids = [Int]()
for i in 0 ..< N {
ids.append(i)
}
super.init()
}
public func find(p:Int)->Int {
var i = p
while i != ids[i] {
i = ids[i]
}
return i
}
public func union(p:Int,q:Int)->Void {
if find(p: p) == find(p: q) {
///已经处于同一个连通分量,直接返回
return
}
///不处于同一个连通分量时,直接将ids[p]改为q的值 使触点p指向触点q
ids[p] = q
count = count-1
}
public func connected(p:Int,q:Int)->Bool {
return find(p: p) == find(p: q)
}
public func counts()->Int {
return count
}
}我们发现quick-union算法的union方法变得简单了很多,但是find方法引入了一个while循环。不过这个循环不像quick-find算法中的循环那样每次都会遍历整个数组,这个循环最佳的情况是只执行一次最坏的情况是执行num-1次。那么我们继续用上面的测试方法测试一下吧;
/** quick-union num : 触点的个数 access_count:连通为一个分量需要对ids数组操作的次数 time:耗时(秒) num access_count(次) time(秒) 10 45 0.000564813613891602 100 495 0.000559806823730469 1000 4995 0.00180912017822266 10000 49995 0.00599193572998047 100000(十万) 499995 0.0488219261169434 1000000(百万) 4999995 0.47326397895813 */
通过这个简单的测试十万个触点的时候不论是访问数组的次数还是测试运行的时间都有了很大的提升。一百万个触点的测试我的小mini也可以轻松的胜任了。但是这个算法还能不能做进一步的提升呢?
我们发现这个quick-union算法里除了find方法其他的方法都很简单,那么我们着重的看下find方法。这个算法里每次对两个触点进行链接的时候都是将一个触点指向另一个被连接的触点,这样每个连通分量都可以看做是一个树状的链接结构(如下图)。
每次执行find方法的时候都会根据当前触点所在的深度不同执行不同的次数。那么我们能不能让我们连通分量所生成的树状结构的深度更小呢?quick-union算法每次联通两个触点的union(p:Int,q:Int)方法都是单纯的将p指向q或者将q指向p,这时我们在将两个触点链接在一起的时候可以考虑固定的将深度较浅的连通分量指向较深的连通分量。这就引出了后续的加权quick-union算法:
加权quick-union:
class WeightedQuickUnion {
private var count:Int
public var ids:[Int]
public var sz:[Int]///记录个个连通分量深度的数组
init(N:Int) {
count = N
ids = [Int]()
sz = [Int]()
for i in 0..<N {
ids.append(i)
sz.append(1)
}
}
public func counts()->Int {
return count
}
public func find(p:Int)->Int {
var i = p
while i != ids[i] {
i = ids[i]
}
return i
}
public func connected(p:Int,q:Int)->Bool {
return find(p: p) == find(p: q)
}
public func union(p:Int,q:Int)->Void {
let i = find(p: p)
let j = find(p: q)
if i == j {
return
}
if sz[i]<sz[j] {
ids[i] = j ; sz[j] = sz[i]+sz[j]
}else {
ids[j] = i ; sz[i] = sz[i]+sz[j]
}
count = count - 1
}
}我们在quick-union算法的基础上添加了一个数组sz:[Int]用来记录个个连通分量的深度,在两个触点执行union的时候始终将深度较浅的指向深度较深的分量的根节点。这样产生的新的连通分量就可以有更浅的树状结构,在执行find方法的时候while循环执行的次数也会相对应的减少;
关于WeightedQuick-Union算法我并没有继续使用上面生成的数据做测试。因为当我们发挥想象力试想下继续测试所产生的连通分量会有怎么样的树状结构时,我们就会发现我们的测试数据所产生的结果证实WeightedQuickUnion算法的最佳结果他产生的树桩结构应该是所有的触点都指向同一个根节点(如下图)。
WeightedQuickUnion算法的最坏的情况是所有执行union操作的两个触点所在的分量深度都一样。同样的我们也可以预想到,因为引入了一个新的数组,那么这个算法在执行较少的数据的时候势必不如quick-union算法。但是当num逐渐的增大的时候加权quick-union算法的优势将逐渐的显现出来。
※我再这两次的测试中发现不同的算法在处理少量数据的时候性能差距都是可接受的,我们在移动端开发的时候所处理的数据都是非常有限的。这使我们在工作中可以选择更好理解的算法(虽然在性能上有所欠缺但是因为简单所以更好维护)。但是这并不能成为我们拒绝学习的理由,本人这次学习《算法》的目的是为拓展自己的思维能力。再说了谁也不知道以后的服务器会不会安在手机上。。。
昨天只看了这么多,今天继续。坚持,我啃啃啃!

相关文章推荐
- 算法分析学习笔记(一) - 动态连通性问题的并查集算法(上)
- 开始学习NodeJs, javascript, 算法
- 从头开始学算法:考研机试题练习(C/C++)–STL使用
- 算法学习第一课静态顺序表操作—练习
- 【算法学习笔记】71.动态规划 双重条件 SJTU OJ 1124 我把助教团的平均智商拉低了
- 动态规划-背包的基础上进行模拟 2018年全国多校算法寒假训练营练习比赛(第二场)牛客网B题
- 数据结构及算法 1-开始学习!
- 我决定从今天开始进行魔鬼式的算法学习与训练
- 算法学习之:动态树(link-cut-tree)及bzoj3282Tree例题详解
- 动态规划-算法学习之路
- 【算法系列学习】Dijkstra单源最短路 [kuangbin带你飞]专题四 最短路练习 A - Til the Cows Come Home
- 开始网络流算法学习
- 【算法学习笔记】07.数据结构基础 链表 初步练习
- 【算法学习笔记】之动态规划
- 算法学习之动态规划(leetcode 85. Maximal Rectangle)
- 【算法学习笔记】27.动态规划 解题报告 SJTU OJ 1254 传手绢
- 从头开始学算法:考研机试题练习(C/C++)–简单数据结构
- 动态连通性:union-find算法(常规搜索、树状触点搜索、加权树搜索的算法分析)
- 【算法学习笔记】07.数据结构基础 链表 初步练习
- 算法学习之路:动态规划-钢条切割-java实现