Gradient And Karush-Kuhn-Tucker Conditions
2017-07-18 16:53
120 查看
转自:http://www.cnblogs.com/vivounicorn/archive/2011/12/29/2306060.html
这两天看到一篇论文,里面提到了Karush-Kuhn-Tucker,给我看的一顿蒙圈!上网找到了一篇博客,写的很66哦!
假设有单变量实值函数
)
,其图形如下:

实值函数
在点

的导数
)
的意义是该函数在

处的瞬时变化率,即:
%3D%5Clim_%7B%5CDelta+x-%3E0%7D%5Cfrac%7Bf(x_0%2B%5CDelta+x)-f(x_0)%7D%7B%5CDelta+x%7D)
在自变量

发生微小变化时,目标函数值的变化可以这么描述:
dx)
针对上图有以下三种情况:
(1)、

点位置,此时
%3E0)
,在
点做微小正向变化:

,显然有

,这说明在
点往
轴正向有可以使目标函数
值增大点存在;
(2)、

点位置,此时
%3C0)
,在
点做微小负向变化:

,显然有
,这说明在
点往
轴负向有可以使目标函数
值增大点存在;
(3)、
点位置,此时
%3D0)
,不管在
点做微小负向变化还是正向变化都有

,这说明在
点是一个最优解。
实际上,在一维情况下目标函数的梯度就是
,它表明了目标函数值变化方向。
以二元函数:
)
为例,设它在点
)
的某个邻域
)
内有定义,以点
出发引射线

,
)
为
上的且在邻域
内的任意点,则方向导数的定义为:
-f(x_0%2Cx_1)%7D%7B%5Crho%7D%7D)
其中

表示

和

两点之间的欧氏距离:
%5E2+%2B+(%5CDelta+x_1)%5E2%7D)
从这个式子可以看到:方向导数与某个方向
有联系、方向导数是个极限值、方向导数与偏导数似乎有联系。
实际上,如果
在点
可微,则:

其中

和

分别是两个维度上的方向角
这里需要注意的一个细节是:沿某个维度的方向导数存在时,其偏导数不一定存在,原因就是方向导数只要求半边极限存在(

),而偏导数则要求双边都存在。
把方向导数变换一下形式:
+%5Ccdot+(%5Ccos%5Calpha+%5Cquad+%5Cquad+%5Cquad+%2C%5Cquad+%5Cquad+%5Cquad+%5Ccos%5Cbeta)+%0A)
函数
在点
的梯度就被定义为向量:
%3D%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x_0%7Di+%2B+%5Cfrac%7B%5Cpartial+f++%7D%7B%5Cpartial+x_1%7Dj)
与射线
同方向的单位向量被定义为:

于是方向导数变成了:
%5Ccdot+e)
%7C%5Ccdot+%5Ccos(gradf(x_0%2Cx_1)%5C%5E+e))
我的理解是:方向导数描述了由各个维度方向形成的合力方向上函数变化的程度,当这个合力方向与梯度向量的方向相同时,函数变化的最剧烈,我想这就是为什么在梯度上升算法或者梯度下降算法中选择梯度方向或者负梯度方向的原因吧。换句话说就是:函数在某点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。

某个函数和它的等高线,图中标出了a点的梯度上升方向
将开篇的那个小例子扩展到多维的情况,目标函数值将会成为一个向量,向任意个维度方向做微小变动都将对目标函数值产生影响,假设有n个维度,可以用下面的式子描述:
%3Dgrad+f%5Ccdot+(dx_0%2C...%2Cdx_n)%5ET%3Dgradf%5Ccdot+dx)
)
令

(1)、当

,此时
,因此可以从点
移动使得目标函数值增加;
(2)、当

,此时

,因此可以从点
移动使得目标函数值减少;
(3)、当

,梯度向量和

正交(任一向量为0也视为正交),不管从点
怎样移动都找不到使目标函数值发生变化的点,于是
点就是目标函数的最优解。
由于
可以是任意方向向量,只要点
的梯度向量不为零,从点
出发总可以找到一个变化方向使得目标函数值向我们希望的方向变化(比如就找梯度方向,此时能引起目标函数值最剧烈地变化),理论上当最优解

出现时就一定有
%3D0)
(实际上允许以某个误差

结束),比如,对于梯度下降算法,当
时迭代结束,此时的
为最优解(可能是全局最优解也可能是局部最优解):
)
从现在开始,我假设目标函数和约束在某点可微,用符号

代替符号

。
+%5C%5C+%0A%26%26s.t.+%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad%5Cquad+h(x)%3D0%2C+%5Cquad+%0A%5Cend%7Beqnarray*%7D)

在约束条件的作用下,与点
(它是个向量)可移动方向相关的向量
就不像无约束问题那样随便往哪个方向都能移动了,此时
只能沿着约束曲线移动,例如,在

、

处,
)
和
不正交,说明还有使目标函数值更小的等高线存在,所以点
还有移动的余地,当移动到

位置时
和
正交,得到最优解
。那么在最优解处
和约束有什么关系呢?因为此时
%3D0)
,
+%5Ccdot+dx%3D0)
,显然此时有
%3D%5Cnabla+f(x))
(其中

是常数),也就是说约束的梯度向量与目标函数的梯度向量在最优解处一定平行。
想到求解此类优化问题时最常用的方法——拉格朗日乘数法,先要构造拉格朗日函数:
+%3D+f(x)+-+%5Clambda+h(x))
其中

,是常数
为什么求解拉格朗日函数得到的最优解就是原问题的最优解呢?
%7D%7B%5Cpart+x%7D%3D%5Cnabla+f(x)-%5Clambda+%5Cnabla+h(x))
%7D%7B%5Cpart+%5Clambda%7D%3D+h(x))
假设
、

为
)
的最优解,那么就需要满足:
-%5Clambda%5E*+%5Cnabla+h(x%5E*)%26%3D%26+0%5C%5C%0A++%5C%5C++++h(x%5E*)%26%3D%260%5C%5C%0A++%5Cend%7Beqnarray*%7D%0A)
第一个式子印证了约束的梯度向量与目标函数的梯度向量在最优解处一定平行,第二个式子就是等式约束本身。
于是:
+%26%5Cgeq+%26L(x%5E*%2C%5Clambda%5E*)%5C%5C%0A%5CRightarrow%26%26+f(x)-%5Clambda+h(x)+%26%5Cgeq+%26f(x%5E*)-%5Clambda%5E*+h(x%5E*)+%5C%5C%0A%5CRightarrow+%26%26f(x)+%26%5Cgeq+%26+f(x%5E*)%0A%5Cend%7Beqnarray*%7D)
实际情况中,约束条件可能是等式约束也可能是不等式约束或者同时包含这两种约束,下面描述为更一般地情况:
%5C%5C%0A%26+s.t.%26+h_i(x)%3D0+%5Cquad+(i%3D0+...+n)%5C%5C%0A%26%26g_j(x)+%5Cleq+0+%5Cquad+(j%3D0...m)%0A%5Cend%7Beqnarray*%7D)
依然使用拉格朗日乘数法,构造拉格朗日函数:
+%3D+f(x)+%2B+%5Csum%5Climit_%7Bi%3D0%7D%5En+%5Calpha_i+%5Ccdot+h_i(x)+%2B+%5Csum%5Climit_%7Bj%3D0%7D%5Em+%5Cbeta_j%5Ccdot+g_j(x))
其中

且

在这里不得不说一下Fritz John 定理了,整个证明就不写了(用局部极小必要条件定理、Gordan 引理可以证明)。
定理1:
依然假设
为上述问题的极小值点,问题中涉及到的各个函数一阶偏导都存在,则存在不全为零的

使得下组条件成立:
+%2B+%5Csum%5Climit_%7Bi%3D0%7D%5En+%5Clambda_i+%5Ccdot+%5Cnabla+h_i(x%5E*)+%2B+%5Csum%5Climit_%7Bj%3D0%7D%5Em+%5Clambda_j%5Ccdot+%5Cnabla+g_j(x%5E*)%3D0)
+%3D+0++%2Cj%3D0%2C...m)

这个定理第一项的形式类似于条件极值必要条件的形式,如果

则有效约束
)
会出现正线性相关,由Gordan
引理知道此时将存在可行方向,就是
将不是原问题的极值点,因此令
则线性无关则

。
+%3D+0++%2Cj%3D1%2C...m)
这个条件又叫互不松弛条件(Complementary Slackness),SVM里的支持向量就是从这个条件得来的。
由Fritz John 定理可知
线性无关则
,让每一个拉格朗日乘子除以

,即

,得到下面这组原问题在点
处取得极小值一阶必要条件。
定理2:
假设
为上述问题的极小值点,问题中涉及到的各个函数一阶偏导都存在,有效约束
线性无关,则下组条件成立:
%7D%7B%5Cpar+tx%7D+%3D%5Cnabla+f(x%5E*)+%2B+%5Csum%5Climit_%7Bi%3D0%7D%5En+%5Cmu%5E*_i+%5Ccdot+%5Cnabla+h_i(x%5E*)+%2B+%5Csum%5Climit_%7Bj%3D0%7D%5Em+%5Cmu%5E*_j%5Ccdot+%5Cnabla+g_j(x%5E*)%3D0)
+%3D+0++%2Cj%3D0%2C...m)

%3D0%2Ci%3D0%2C..%2Cn)
+%5Cleq+0%2Cj%3D0%2C...m)
这组条件就是Karush-Kuhn-Tucker条件,满足KKT条件的点就是KKT点,需要注意的是KKT条件是必要条件(当然在某些情况下会升级为充要条件,比如凸优化问题)。
由此也可以想到求解SVM最大分类间隔器时,不管是解决原问题还是解决对偶问题,不管是用SMO方法或其它方法,优化的过程就是找到并优化违反KKT条件的最合适的乘子。
KKT条件与对偶理论有密切的关系,依然是解决下面这个问题:
构造拉格朗日函数:
其中
且
,它们都是拉格朗日乘子
令
%3D%5Cmax%5Climit_%7B%5Calpha+%2C%5Cbeta%7D+L(x%2C%5Calpha%2C%5Cbeta))
,原问题可以表示为下面这个形式:
%3D+%0A+%5Cleft%5C%7B%0A%0A+++%5Cbegin%7Barray%7D%7Bc%7D%0A%0A+++%26f(x)%26+if+%5Cquad+x+%5Cquad+satisfies+%5Cquad+primal+%5Cquad+constraints%26%5C%5C%0A%0A++%26+%5Cinfty%26+otherwise.%26%5C%5C%0A%0A+++%5Cend%7Barray%7D%0A%0A++%5Cright.%0A)
这个式子比较容易理解,当
违反原问题约束条件时有:
%3D%5Cmax%5Climit_%7B%5Calpha+%2C%5Cbeta%7D+L(x%2C%5Calpha+%2C%5Cbeta)+%3D+%5Cmax%5Climit_%7B%5Calpha%2C+%5Cbeta%7D+f(x)+%2B+%5Csum%5Climit_%7Bi%3D0%7D%5En+%5Calpha_i+%5Ccdot+h_i(x)+%2B+%5Csum%5Climit_%7Bj%3D0%7D%5Em+%5Cbeta_j%5Ccdot+g_j(x)%3D%5Cinfty%0A)
于是原问题等价为下面这个问题:
%3D%5Cmin%5Climit_x+%5Cmax%5Climit_%7B%5Calpha+%2C%5Cbeta%7D+L(x%2C%5Calpha%2C%5Cbeta))
它的最优解记为

令
%3D%5Cmin%5Climit_%7Bx%7D+L(x%2C%5Calpha%2C%5Cbeta))
,则有以下形式:
%3D%5Cmax%5Climit_%7B%5Calpha%2C%5Cbeta%7D+%5Cmin%5Climit_%7Bx%7D+L(x%2C%5Calpha%2C%5Cbeta))
它的最优解记为

上面这两个形式很像,区别只在于

和

的顺序,实际上
)
和
)
互为对偶问题。因为

,打个不太恰当的比喻,这就像瘦死的骆驼比马大,具体的证明就不写了,所以

,这个就是弱对偶性,此时存在对偶间隙,它被定义为:

。
有弱对偶性就有强对偶性,它指的是在某些条件下有

,比如在以下条件下满足强对偶性:
目标函数和所有不等式约束函数是凸函数,等式约束函数是仿射函数(形如

),且所有不等式约束都是严格的约束(大于或小于)。
KKT条件和强对偶性的关系是:
KKT条件是强对偶性成立的必要条件,特别的,当原问题是凸优化问题时,KKT条件就是充要条件,强对偶性存在时KKT点既是原问题的解也是对偶问题的解,这个时候对偶间隙为0。
关于对偶问题可以参考pluskid写得非常好的一篇文章:http://blog.pluskid.org/?p=702
梯度是一个基础而重要的概念,函数在某点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值,梯度下降算法正是依据这一原理,还有在求解极大似然问题时也可以用梯度上升的算法进行参数估计;对于约束最优化问题可以使用拉格朗日乘数法解决——如:构造拉格朗日函数,求出KKT条件;当原问题不太好解决的时候可以利用拉格朗日乘数法得到其对偶问题,满足强对偶性条件时它们的解会是一致的,SVM问题的解决把这一点用的淋漓尽致,同时也为我们提供了一种判断算法收敛情况的方法——监视可行间隙。
这两天看到一篇论文,里面提到了Karush-Kuhn-Tucker,给我看的一顿蒙圈!上网找到了一篇博客,写的很66哦!
一、梯度是什么?
1、一个小例子
假设有单变量实值函数,其图形如下:
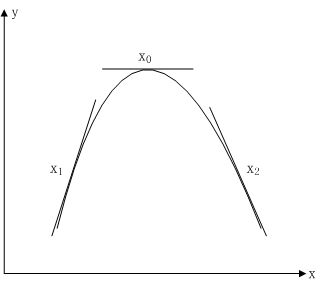
实值函数
在点
的导数
的意义是该函数在
处的瞬时变化率,即:
在自变量
发生微小变化时,目标函数值的变化可以这么描述:
针对上图有以下三种情况:
(1)、
点位置,此时
,在
点做微小正向变化:
,显然有
,这说明在
点往
轴正向有可以使目标函数
值增大点存在;
(2)、
点位置,此时
,在
点做微小负向变化:
,显然有
,这说明在
点往
轴负向有可以使目标函数
值增大点存在;
(3)、
点位置,此时
,不管在
点做微小负向变化还是正向变化都有
,这说明在
点是一个最优解。
实际上,在一维情况下目标函数的梯度就是
,它表明了目标函数值变化方向。
2、梯度与方向导数
(1)、方向导数
以二元函数:为例,设它在点
的某个邻域
内有定义,以点
出发引射线
,
为
上的且在邻域
内的任意点,则方向导数的定义为:
其中
表示
和
两点之间的欧氏距离:
从这个式子可以看到:方向导数与某个方向
有联系、方向导数是个极限值、方向导数与偏导数似乎有联系。
实际上,如果
在点
可微,则:
其中
和
分别是两个维度上的方向角
这里需要注意的一个细节是:沿某个维度的方向导数存在时,其偏导数不一定存在,原因就是方向导数只要求半边极限存在(
),而偏导数则要求双边都存在。
(2)、梯度
把方向导数变换一下形式:函数
在点
的梯度就被定义为向量:
与射线
同方向的单位向量被定义为:
于是方向导数变成了:
我的理解是:方向导数描述了由各个维度方向形成的合力方向上函数变化的程度,当这个合力方向与梯度向量的方向相同时,函数变化的最剧烈,我想这就是为什么在梯度上升算法或者梯度下降算法中选择梯度方向或者负梯度方向的原因吧。换句话说就是:函数在某点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。

某个函数和它的等高线,图中标出了a点的梯度上升方向
3、多维无约束问题
将开篇的那个小例子扩展到多维的情况,目标函数值将会成为一个向量,向任意个维度方向做微小变动都将对目标函数值产生影响,假设有n个维度,可以用下面的式子描述:令
(1)、当
,此时
,因此可以从点
移动使得目标函数值增加;
(2)、当
,此时
,因此可以从点
移动使得目标函数值减少;
(3)、当
,梯度向量和
正交(任一向量为0也视为正交),不管从点
怎样移动都找不到使目标函数值发生变化的点,于是
点就是目标函数的最优解。
由于
可以是任意方向向量,只要点
的梯度向量不为零,从点
出发总可以找到一个变化方向使得目标函数值向我们希望的方向变化(比如就找梯度方向,此时能引起目标函数值最剧烈地变化),理论上当最优解
出现时就一定有
(实际上允许以某个误差
结束),比如,对于梯度下降算法,当
时迭代结束,此时的
为最优解(可能是全局最优解也可能是局部最优解):
二、拉格朗日乘数法和KKT条件
从现在开始,我假设目标函数和约束在某点可微,用符号代替符号
。
1、等式约束

在约束条件的作用下,与点
(它是个向量)可移动方向相关的向量
就不像无约束问题那样随便往哪个方向都能移动了,此时
只能沿着约束曲线移动,例如,在
、
处,
和
不正交,说明还有使目标函数值更小的等高线存在,所以点
还有移动的余地,当移动到
位置时
和
正交,得到最优解
。那么在最优解处
和约束有什么关系呢?因为此时
,
,显然此时有
(其中
是常数),也就是说约束的梯度向量与目标函数的梯度向量在最优解处一定平行。
想到求解此类优化问题时最常用的方法——拉格朗日乘数法,先要构造拉格朗日函数:
其中
,是常数
为什么求解拉格朗日函数得到的最优解就是原问题的最优解呢?
假设
、
为
的最优解,那么就需要满足:
第一个式子印证了约束的梯度向量与目标函数的梯度向量在最优解处一定平行,第二个式子就是等式约束本身。
于是:
2、不等式约束
实际情况中,约束条件可能是等式约束也可能是不等式约束或者同时包含这两种约束,下面描述为更一般地情况:依然使用拉格朗日乘数法,构造拉格朗日函数:
其中
且
在这里不得不说一下Fritz John 定理了,整个证明就不写了(用局部极小必要条件定理、Gordan 引理可以证明)。
定理1:
依然假设
为上述问题的极小值点,问题中涉及到的各个函数一阶偏导都存在,则存在不全为零的
使得下组条件成立:
这个定理第一项的形式类似于条件极值必要条件的形式,如果
则有效约束
会出现正线性相关,由Gordan
引理知道此时将存在可行方向,就是
将不是原问题的极值点,因此令
则线性无关则
。
这个条件又叫互不松弛条件(Complementary Slackness),SVM里的支持向量就是从这个条件得来的。
由Fritz John 定理可知
线性无关则
,让每一个拉格朗日乘子除以
,即
,得到下面这组原问题在点
处取得极小值一阶必要条件。
定理2:
假设
为上述问题的极小值点,问题中涉及到的各个函数一阶偏导都存在,有效约束
线性无关,则下组条件成立:
这组条件就是Karush-Kuhn-Tucker条件,满足KKT条件的点就是KKT点,需要注意的是KKT条件是必要条件(当然在某些情况下会升级为充要条件,比如凸优化问题)。
由此也可以想到求解SVM最大分类间隔器时,不管是解决原问题还是解决对偶问题,不管是用SMO方法或其它方法,优化的过程就是找到并优化违反KKT条件的最合适的乘子。
KKT条件与对偶理论有密切的关系,依然是解决下面这个问题:
构造拉格朗日函数:
其中
且
,它们都是拉格朗日乘子
令
,原问题可以表示为下面这个形式:
这个式子比较容易理解,当
违反原问题约束条件时有:
于是原问题等价为下面这个问题:
它的最优解记为
令
,则有以下形式:
它的最优解记为
上面这两个形式很像,区别只在于
和
的顺序,实际上
和
互为对偶问题。因为
,打个不太恰当的比喻,这就像瘦死的骆驼比马大,具体的证明就不写了,所以
,这个就是弱对偶性,此时存在对偶间隙,它被定义为:
。
有弱对偶性就有强对偶性,它指的是在某些条件下有
,比如在以下条件下满足强对偶性:
目标函数和所有不等式约束函数是凸函数,等式约束函数是仿射函数(形如
),且所有不等式约束都是严格的约束(大于或小于)。
KKT条件和强对偶性的关系是:
KKT条件是强对偶性成立的必要条件,特别的,当原问题是凸优化问题时,KKT条件就是充要条件,强对偶性存在时KKT点既是原问题的解也是对偶问题的解,这个时候对偶间隙为0。
关于对偶问题可以参考pluskid写得非常好的一篇文章:http://blog.pluskid.org/?p=702
三、总结
梯度是一个基础而重要的概念,函数在某点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值,梯度下降算法正是依据这一原理,还有在求解极大似然问题时也可以用梯度上升的算法进行参数估计;对于约束最优化问题可以使用拉格朗日乘数法解决——如:构造拉格朗日函数,求出KKT条件;当原问题不太好解决的时候可以利用拉格朗日乘数法得到其对偶问题,满足强对偶性条件时它们的解会是一致的,SVM问题的解决把这一点用的淋漓尽致,同时也为我们提供了一种判断算法收敛情况的方法——监视可行间隙。

相关文章推荐
- Gradient And Karush-Kuhn-Tucker Conditions
- Lagrange Multiplier and KKT(Karush-Kuhn-Tucker)
- 逻辑回归模型实例(by Fminunc and Gradient descent)
- batch gradient algorithm and stochastic gradient algorithm
- Gradient And Karush-Kuhn-Tucker Conditions
- KKT(Karush-Kuhn-Tucher)条件
- Machine Learning with Scikit-Learn and Tensorflow 7.9 Gradient Boosting
- Logistic Regression and Gradient Descent
- neural-networks-and-deep-learning misleading_gradient.py
- Gradient Descent and NSCA
- 关于Karush-Kuhn-Tucker(KKT)条件的几何分析
- 20060925-Dilation, erosion, and the morphological gradient
- 线性回归与梯度下降(linear regression and gradient descent)
- Karush-Kuhn-Tucker 最优化条件 (KKT 条件)(转载)
- The Relation Between Gradient Descent and Cost Funtion(To be continued)
- [置顶] 线性回归和梯度下降(Linear Regression and Gradient Descent)
- 拉格朗日对偶和KKT条件(Karush-Kuhn-Tucker)
- 第三讲之 Logistic Regression(method:Gradient descent and Newton)
- FillRect and GradientFill
- SVM中的Karush-Kuhn-Tucker条件和对偶问题