The effect of parameter class_weight on linear SVM classifier
2017-07-17 19:28
766 查看
Best way to handle unbalanced dataset with SVM
I'm trying to build a prediction model with SVMs on fairly unbalanced data.
My labels/output have two classes, positive, and negative. I would say the positive example makes about 30% of my data, and negative about 70%. I'm trying to balance out the classes as the cost associated with incorrect predictions among the classes are not
the same. One method was resampling the training data and producing an equally balanced dataset, which was larger than the original.
Having different penalties for the margin slack variables for patterns of each class is a better approach than resampling the data. It is asymptotically
equivalent to resampling anyway, but is easier to implement and continuous, rather than discrete, so you have more control.
However, choosing the weights is not straightforward. In principal you can work out a theoretical weighting that takes into account the misclassification costs and the differences between training set an operational prior class probabilities, but it will not
give the optimal performance. The best thing to do is to select the penalties/weights for each class via minimising the loss (taking into account the misclassification costs) by cross-validation.
(OpenCV) How should we set the class weights in the OpenCV SVM implementation ?
Initialise a 1D opencv floating point matrix (point to CvMat* of type CV_32FC1) containing as many elements (columns
4000
) as classes in the learning
problem (i.e. 1xN matrix where N is the number of classes). Set each entry of this matrix to the corresponding class weights for classes 1 to N . From the OpenCV Manual: "class_weights - Optional weights, assigned to particular classes. They are multiplied
by C and thus affect the misclassification penalty for different classes. The larger weight, the larger penalty on misclassification of data from the corresponding class."
vector<float> v = {1,3.0}; // 1 for negative class and 3 for positive class
Mat weights = Mat(v);
CvMat cvWeights = weights;
CvSVMParams params;
params.svm_type = CvSVM::C_SVC;
params.kernel_type = CvSVM::LINEAR;
params.C = 10;
params.class_weights = &cvWeights;
params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 5000, 1e-6);
// Train the SVM
CvSVM SVM;
cout << "Training begins..." << endl;
SVM.train(traindata, trainlabel, Mat(), Mat(), params);
SVM.save((this->param_file).c_str());
cout << "Training ends." << endl;
Regarding the weights, I did some small tests to check the influence. Here are my results:
No class weights:
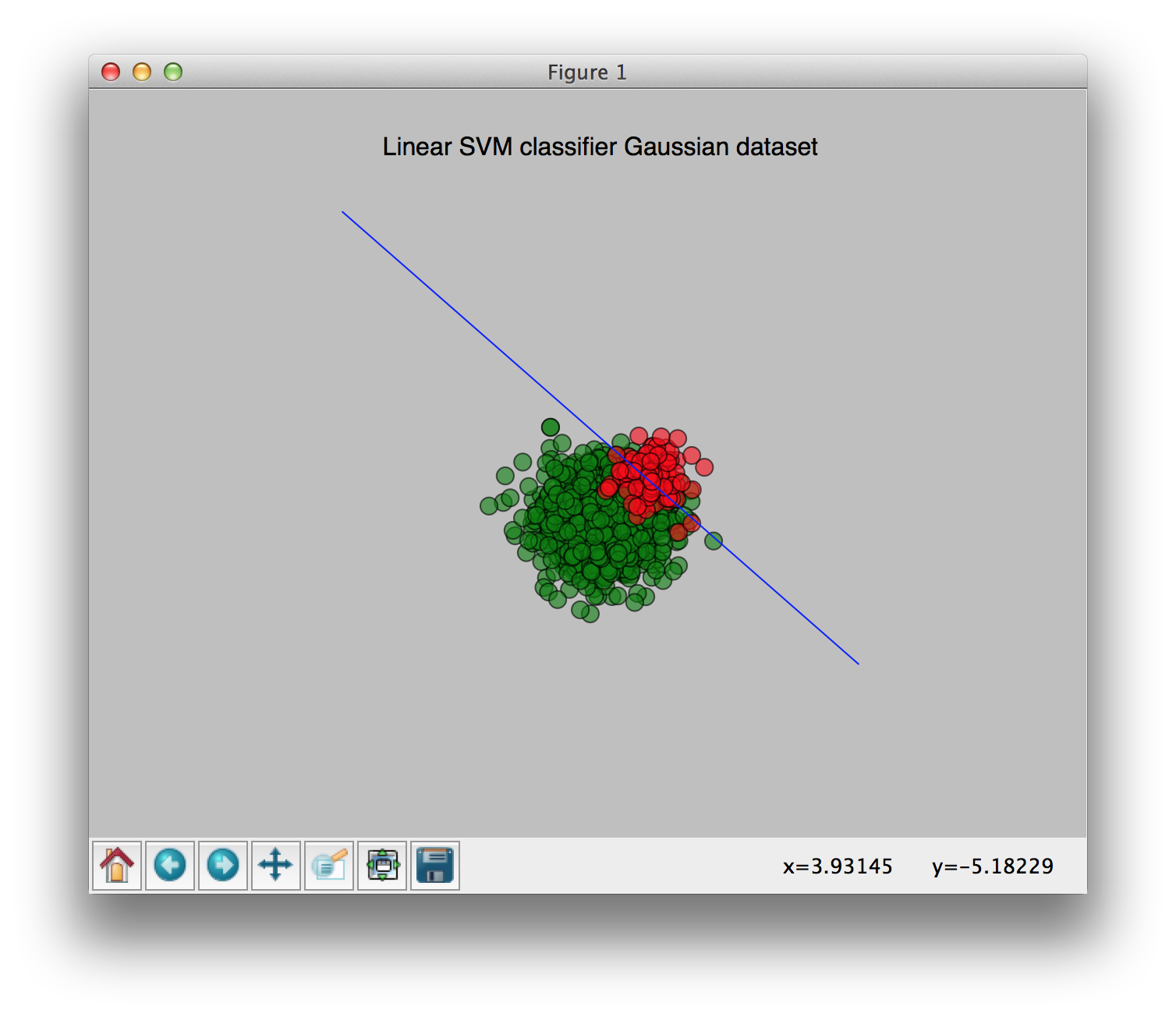
With weights [0.9, 0.1] (0.9 for the largest class, 0.1 for the smallest class):
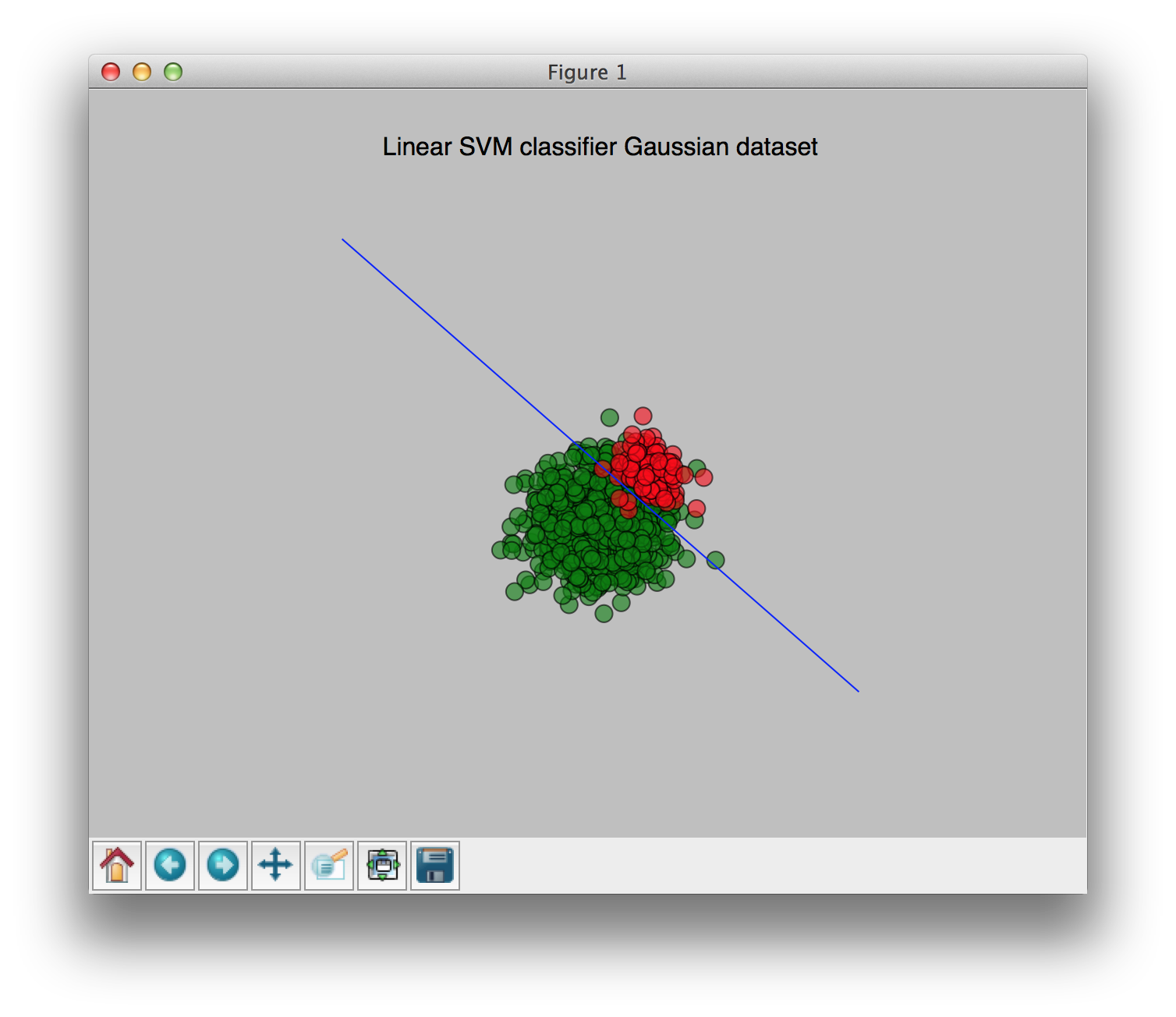
You can see the change of the weights clearly in these pictures. I hope this clears things up a bit.
(Image source: http://answers.opencv.org/question/26818/svm-bias-on-weights-of-positives-and-negatives/)
I'm trying to build a prediction model with SVMs on fairly unbalanced data.
My labels/output have two classes, positive, and negative. I would say the positive example makes about 30% of my data, and negative about 70%. I'm trying to balance out the classes as the cost associated with incorrect predictions among the classes are not
the same. One method was resampling the training data and producing an equally balanced dataset, which was larger than the original.
Having different penalties for the margin slack variables for patterns of each class is a better approach than resampling the data. It is asymptotically
equivalent to resampling anyway, but is easier to implement and continuous, rather than discrete, so you have more control.
However, choosing the weights is not straightforward. In principal you can work out a theoretical weighting that takes into account the misclassification costs and the differences between training set an operational prior class probabilities, but it will not
give the optimal performance. The best thing to do is to select the penalties/weights for each class via minimising the loss (taking into account the misclassification costs) by cross-validation.
(OpenCV) How should we set the class weights in the OpenCV SVM implementation ?
Initialise a 1D opencv floating point matrix (point to CvMat* of type CV_32FC1) containing as many elements (columns
4000
) as classes in the learning
problem (i.e. 1xN matrix where N is the number of classes). Set each entry of this matrix to the corresponding class weights for classes 1 to N . From the OpenCV Manual: "class_weights - Optional weights, assigned to particular classes. They are multiplied
by C and thus affect the misclassification penalty for different classes. The larger weight, the larger penalty on misclassification of data from the corresponding class."
vector<float> v = {1,3.0}; // 1 for negative class and 3 for positive class
Mat weights = Mat(v);
CvMat cvWeights = weights;
CvSVMParams params;
params.svm_type = CvSVM::C_SVC;
params.kernel_type = CvSVM::LINEAR;
params.C = 10;
params.class_weights = &cvWeights;
params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 5000, 1e-6);
// Train the SVM
CvSVM SVM;
cout << "Training begins..." << endl;
SVM.train(traindata, trainlabel, Mat(), Mat(), params);
SVM.save((this->param_file).c_str());
cout << "Training ends." << endl;
Regarding the weights, I did some small tests to check the influence. Here are my results:
No class weights:
With weights [0.9, 0.1] (0.9 for the largest class, 0.1 for the smallest class):
You can see the change of the weights clearly in these pictures. I hope this clears things up a bit.
(Image source: http://answers.opencv.org/question/26818/svm-bias-on-weights-of-positives-and-negatives/)

相关文章推荐
- The effect of opinion clustering on disease outbreaeks
- ON THE EVOLUTION OF MACHINE LEARNING: FROM LINEAR MODELS TO NEURAL NETWORKS
- 76 What is the effect of increasing the value of the ASM_POWER_LIMIT parameter? A. The number of DBW
- hibernate.TypeMismatchException: Provided id of the wrong type for class
- linux编译中error: no arguments depend on a template parameter, declaration of * must 解决
- hdu 5095 Linearization of the kernel functions in SVM(模拟)
- 安装springboot时遇到 LoggerFactory is not a Logback LoggerContext but Logback is on the classpath.问题
- [转] Loren on the Art of MATLAB
- How to draw an Icon on the IndicatorPane of Series 60
- Determining the Size of a Class Object
- ORACLE:IMP工具ignore=y的一个问题【THE QUESTION OF ORACLE IMP TOOL WHEN USE PARAMETER IGNORE=Y】
- The serializable class Myuser does not declare a static final serialVersionUID field of type long
- C#中事件的委托的注意事项(can only appear on the left hand side of += or -=)
- com.sun.tools.javac.Main is not on the classpath.Perhaps JAVA_HOME does not point to the JDK
- How to remove the copyright box on a paper that uses the ACM sig-alternate.cls class file?
- 当主页面关闭时关闭所有子窗口(Close all the child windows on unload of main page)
- (转载)A Crash Course on the Depths of Win32 Structured Exception Handling
- Changing the Output Voltage of a Switching Regulator on the Fly
- "org.xml.sax.SAXParseException: The content of element type "class" must match" 异常解决
- virtualbox “The value of the 服务器端口号 field on the 显示 page is 未完成” 错误