Pandas数据特征分析
2017-07-17 10:32
239 查看
Pandas数据特征分析

数据的排序
.sort_index()方法在指定轴上根据索引进行排序,默认升序。默认0轴升序:.sort_index(axis=0, ascending=True)。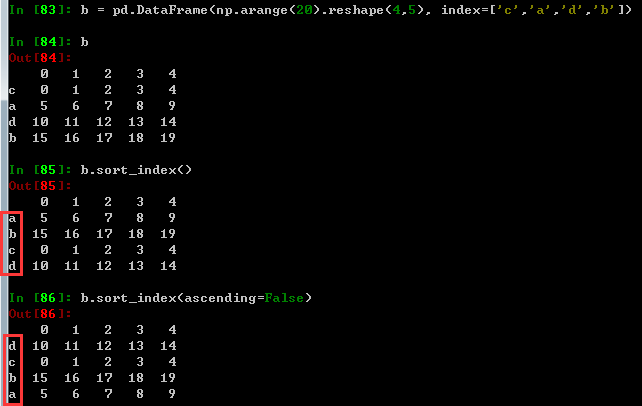
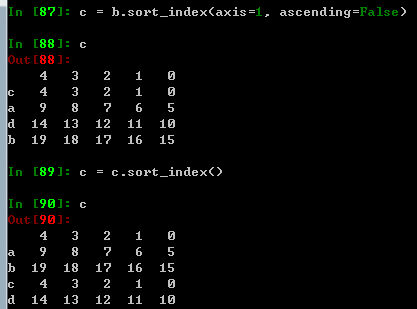
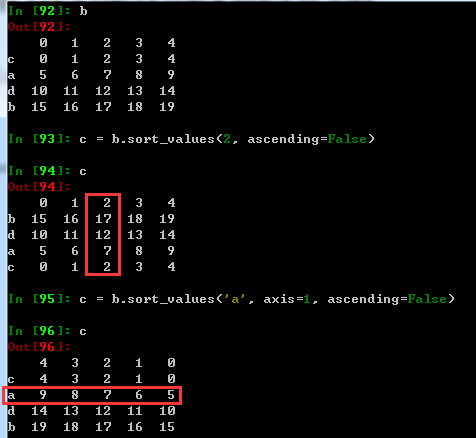
.sort_values()方法在指定轴上根据数值进行排序,默认升序。
Series.sort_values(axis=0, ascending=True)
DataFrame.sort_values(by, axis=0, ascending=True)
by : axis轴上的某个索引或索引列表。
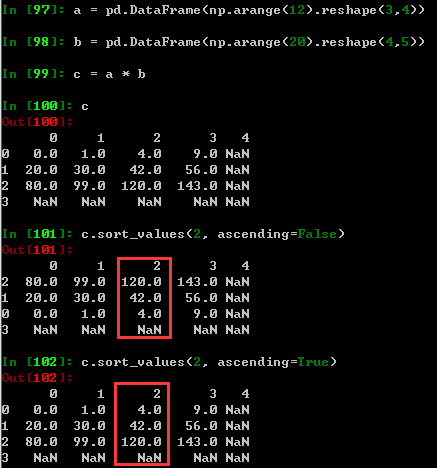
NaN统一放到排序末尾
数据的基本统计分析
基本的统计分析函数:适用于Series和DataFrame类型数据| 方法 | 说明 |
| .sum() | 计算数据的总和,按0轴计算,下同 |
| .count() | 非NaN值的数量 |
| .mean() .median() | 计算数据的算术平均值、算术中位数 |
| .var() .std() | 计算数据的方差、标准差 |
| .min() .max() | 计算数据的最小值、最大值 |
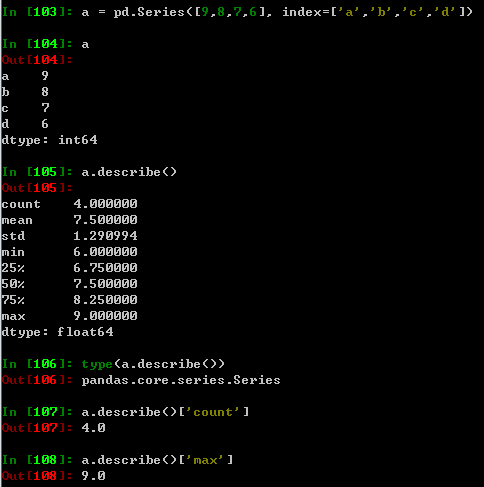
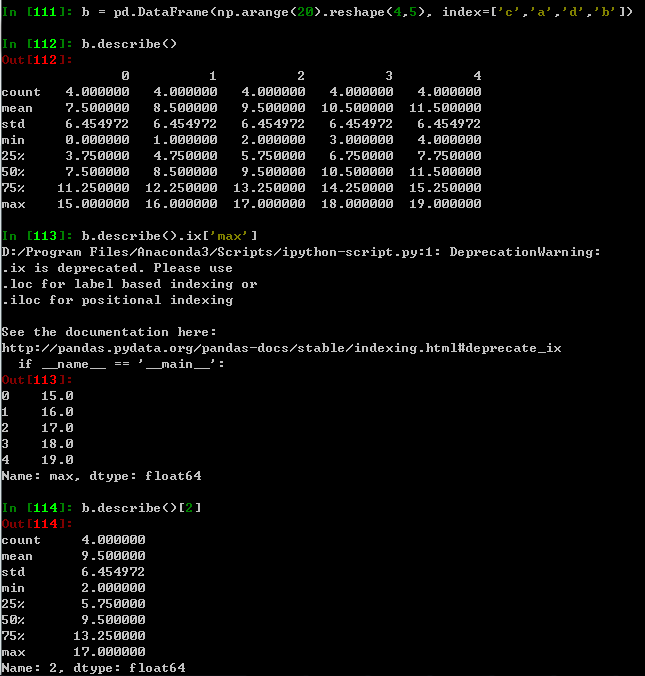
| .describe() | 针对0轴(各列)的统计汇总 |
适用于Series类型
| 方法 | 说明 |
| .argmin() .argmax() | 计算数据最大值、最小值所在位置的索引位置(自动索引) |
| .idxmin() .idxmax() | 计算数据最大值、最小值所在位置的索引位置(自定义索引) |
数据的累计统计分析
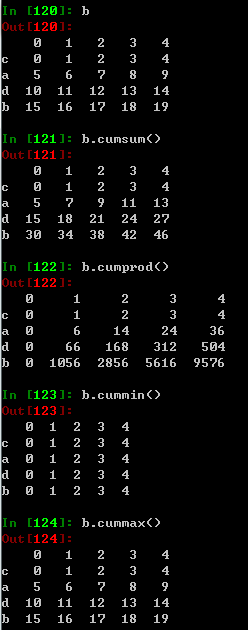
累计统计分析函数:适用于Series和DataFrame类型,累计计算| 方法 | 说明 |
| .cumsum() | 依次给出前1、2、…、n个数的和 |
| .cumprod() | 依次给出前1、2、…、n个数的积 |
| .cummax() | 依次给出前1、2、…、n个数的最大值 |
| .cummin() | 依次给出前1、2、…、n个数的最小值 |
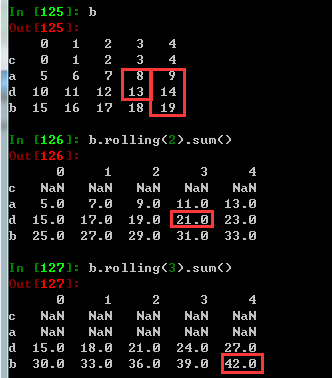
累计统计分析函数:适用于Series和DataFrame类型,滚动计算(窗口计算)
| 方法 | 说明 |
| .rolling(w).sum() | 依次计算相邻w个元素的和 |
| .rolling(w).mean() | 依次计算相邻w个元素的算术平均值 |
| .rolling(w).var() | 依次计算相邻w个元素的方差 |
| .rolling(w).std() | 依次计算相邻w个元素的标准差 |
| .rolling(w).min() .max() | 依次计算相邻w个元素的最小值和最大值 |
数据的相关性分析
两个事物,表示为X和Y,如何判断它们之间的存在相关性?相关性:
• X增大,Y增大,两个变量正相关
• X增大,Y减小,两个变量负相关
• X增大,Y无视,两个变量不相关
协方差:

•协方差>0, X和Y正相关
•协方差<0, X和Y负相关
•协方差=0, X和Y独立无关
Person相关系数:
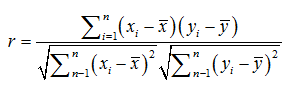
R的取值范围为[-1, 1]
• 0.8‐1.0 极强相关
• 0.6‐0.8 强相关
• 0.4‐0.6 中等程度相关
• 0.2‐0.4 弱相关
• 0.0‐0.2 极弱相关或无相关
相关性分析函数:适用于Series和DataFrame类型
| 方法 | 说明 |
| .cov() | 计算协方差矩阵 |
| .corr() | 计算相关系数矩阵, Pearson、Spearman、Kendall等系数 |
小结:


相关文章推荐
- 数据分析与展示——Pandas数据特征分析
- Python数据分析与展示(6)——Pandas数据特征分析
- 利用python/pandas/numpy做数据分析(三)-透视表pivot_table
- 开启机器学习的第一课:用Pandas进行数据分析
- Python数据分析之pandas学习
- pandas分析NBA2017-2018赛季球员球队数据
- python数据分析包pandas的使用方法
- 人工智能学习笔记——数据分析处理库Pandas
- 数据探索简介——质量分析、特征分析
- python爬取拉勾网招聘信息并利用pandas做简单数据分析
- (转载)Python数据分析之pandas学习
- 【python数据挖掘课程】十二.Pandas、Matplotlib结合SQL语句对比图分析
- 用 python 做数据分析:pandas 的 excel 应用初探
- 小象学院_Python数据分析_第三讲_Pandas
- python/pandas/numpy数据分析(十)-函数, rank,重复索引
- 【Python实战】Pandas:让你像写SQL一样做数据分析(二)
- Python 数据分析包:pandas 基础
- 上网行为、应用层协议数据特征与流量特征分析(招商合作)
- 数据分析 第三篇:数据特征分析(分布分析+帕累托分析)
- python pandas做数据分析视图分析matplotlib,seaborn模块使用