Hadoop好友推荐系统-执行分类算法
2017-07-14 09:40
561 查看
项目总目录:基于Hadoop的好友推荐系统项目综述
一、前端展示
1、jsp页面
<table> <tr> <td><label for="name">输入路径:</label></td> <td><input class="easyui-validatebox" type="text" id= "runcluster2_input" name="input" data-options="required:true" style="width:300px" value="/user/root/_filter/preparevectors"/> </td> </tr> <tr> <td><label for="name">输出路径:</label></td> <td><input class="easyui-validatebox" type="text" id= "runcluster2_output" name="output" data-options="required:true" style="width:300px" value="/user/root/_center"/> </td> </tr> <tr> <td><label for="name">距离阈值:</label></td> <td><input class="easyui-validatebox" type="text" value="29" id="runcluster2_delta" name="delta" data-options="required:true" /> </td> </tr> <tr> <td><label for="name">聚类中心数:</label></td> <td><input class="easyui-validatebox" type="text" id="runcluster2_k" value="4" data-options="required:true" /> </td> <tr> <td><a id="runcluster2_submitid" href="" class="easyui-linkbutton">提交</a></td> </tr> </table>
在jsp页面中需要指定四个值
输入路径:数据库过滤到HDFS上的原数据(包含用户的原始信息);
输出路径:分类结果输出目录;
距离阈值:不用人为设置,直接从前面的计算结果中获取;
聚类中心数:根据上一步的计算结果设定。
2、js逻辑
// runCluster2.jsp执行分类算法-------
$('#runcluster2_submitid').bind('click', function(){
var k=$('#runcluster2_k').val();// 聚类中心向量个数
var input_=$('#runcluster2_input').val();
var output_=$('#runcluster2_output').val();
var delta_=$('#runcluster2_delta').val();
// 弹出进度框
popupProgressbar('执行聚类','原始数据拷贝并执行分类中...',1000);
// ajax 异步提交任务
console.info('here');
callByAJax('cloud/cloud_runCluster2.action',{input:input_,output:output_,record:k,delta:delta_});
});二、后台实现
1、action层
对应的action从这里获取callByAJax(‘cloud/cloud_runCluster2.action’,/**
* 快速聚类--执行分类算法
*
*/
public void runCluster2(){
Map<String ,Object> map = new HashMap<String,Object>();
try {
HUtils.setJobStartTime(System.currentTimeMillis()-10000);// 设置任务启动时间
// 由于不知道循环多少次完成,所以这里设置为2,每次循环都递增1
// 当所有循环完成的时候,就该值减去2即可停止监控部分的循环
HUtils.JOBNUM=2;
// 2. 使用Thread的方式启动一组MR任务
new Thread(new RunCluster2(input, output,delta, record)).start();
// 3. 启动成功后,直接返回到监控,同时监控定时向后台获取数据,并在前台展示;
map.put("flag", "true");
map.put("monitor", "true");
} catch (Exception e) {
e.printStackTrace();
map.put("flag", "false");
map.put("monitor", "false");
map.put("msg", e.getMessage());
}
Utils.write2PrintWriter(JSON.toJSONString(map));
}2、RunCluster2的定义
/**
* 分类操作线程
*/
public class RunCluster2 implements Runnable {
private String input;
private String output;
private String delta;//距离阀值
private String k;//聚类中心数
private Logger log = LoggerFactory.getLogger(RunCluster2.class);
@Override
public void run() {
input=input==null?HUtils.FILTER_PREPAREVECTORS:input;
try {
HUtils.clearCenter((output==null?HUtils.CENTERPATH:output));//清除输出目录
} catch (FileNotFoundException e2) {
e2.printStackTrace();
} catch (IOException e2) {
e2.printStackTrace();
}
output=output==null?HUtils.CENTERPATHPREFIX:output+"/iter_";
// 加一个操作,把/user/root/preparevectors里面的数据复制到/user/root/_center/iter_0/unclustered里面
HUtils.copy(input,output+"0/unclustered");
try {
Thread.sleep(200);// 暂停200ms
} catch (InterruptedException e1) {
e1.printStackTrace();
}
// 求解dc的阈值
// double dc =dcs[0];//使用前端传递的值
//每次循环执行分类时,阈值都是变化的,这里采取的方式是:
//1. 计算聚类中心向量两两之间的距离,并按照距离排序,从小到大,每次循环取出距离的一半当做阈值,一直取到最后一个距离;
//2. 当进行到K*(K-1)/2个距离时,即最后一个距离(K个聚类中心向量)后,下次循环的阈值设置为当前阈值翻倍,即乘以2;并计数,当再循环k次后,此阈值将不再变化;
//3. 这样设置可以减少误判,同时控制循环的次数;
// 读取聚类中心文件
Map<Object,Object> vectorsMap= HUtils.readSeq(output+"0/clustered/part-m-00000", Integer.parseInt(k));
double[][] vectors = HUtils.getCenterVector(vectorsMap);
double[] distances= Utils.getDistances(vectors);//获取两两聚类中心向量的距离,并按照从小到大排序
// 这里不使用传入进来的阈值
int iter_i=0;
int ret=0;
double tmpDelta=0;
int kInt = Integer.parseInt(k);
try {
do{//使用do-while循环
if(iter_i>=distances.length){//distances.length=K*(K-1)/2
// 当读取到最后一个向量距离时,使用如下方式计算阀值
tmpDelta=Double.parseDouble(delta);
while(kInt-->0){// 超过k次后就不再增大
tmpDelta*=2;// 每次翻倍
}
delta=String.valueOf(tmpDelta);//最终的阀值
}else{
//距离数组未越界时,直接取读取距离的一半为阀值
delta=String.valueOf(distances[iter_i]/2);
}
log.info("this is the {} iteration,with dc:{}",new Object[]{iter_i,delta});
String[] ar={
HUtils.getHDFSPath(output)+iter_i+"/unclustered",
HUtils.getHDFSPath(output)+(iter_i+1),//output
//HUtils.getHDFSPath(HUtils.CENTERPATHPREFIX)+iter_i+"/clustered/part-m-00000",//center file
k,
delta,
String.valueOf((iter_i+1))
};//初始化MapReduce运行参数
try{
ret = ToolRunner.run(HUtils.getConf(), new ClusterDataJob(), ar);
if(ret!=0){
log.info("ClusterDataJob failed, with iteration {}",new Object[]{iter_i});
break;
}
}catch(Exception e){
e.printStackTrace();
}
iter_i++;
HUtils.JOBNUM++;// 每次循环后加1
}while(shouldRunNextIter());//通过方法shouldRunNextIter()来判断是否终止循环
} catch (IllegalArgumentException e) {
e.printStackTrace();
}
if(ret==0){
log.info("All cluster Job finished with iteration {}",new Object[]{iter_i});
}
}
/**
* 是否应该继续下次循环
* 直接使用分类记录数和未分类记录数来判断
* @throws IOException
* @throws IllegalArgumentException
*/
private boolean shouldRunNextIter() {
if(HUtils.UNCLUSTERED==0||HUtils.CLUSTERED==0){//MapReduce任务运行时会修改HUtils.UNCLUSTERED和HUtils.CLUSTERED的值
//当两者其中一个为0时,则表示所有数据已经聚类完成,则结束循环
HUtils.JOBNUM-=2;// 不用监控 则减去2;
return false;
}
return true;
}
public RunCluster2(){}
public RunCluster2(String input,String output,String delta,String k){
this.delta=delta;
this.input=input;
this.output=output;
this.k=k;
}
}它主要完成了距离阀值的计算(run方法中)和任务终止的判断(shouldRunNextIter方法中)。通过
ret = ToolRunner.run(HUtils.getConf(), new ClusterDataJob(), ar);
来启动MapReduce任务。
3、MapReduce任务
ClusterDataJob定义/**
* 执行分类算法的MapReduce
*
* 输入为 db2hdfs的输出
*
*/
public class ClusterDataJob extends Configured implements Tool {
public int run(String[] args) throws Exception {
Configuration conf = HUtils.getConf();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();//初始化命令行参数
if (otherArgs.length !=5) {
System.err.println("Usage: com.kang.fast_cluster.ClusterData <in> <out>" +
" <K> <dc> <iter_i>");
System.exit(5);
}
conf.setInt("K", Integer.parseInt(otherArgs[2]));//设置聚类中心数
conf.setDouble("DC", Double.parseDouble(otherArgs[3]));//设置距离阀值
conf.setInt("ITER_I", Integer.parseInt(otherArgs[4]));//当前处理的数据个数
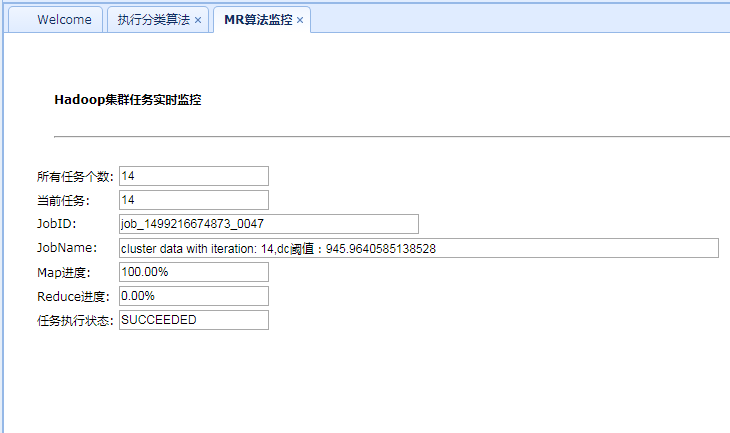
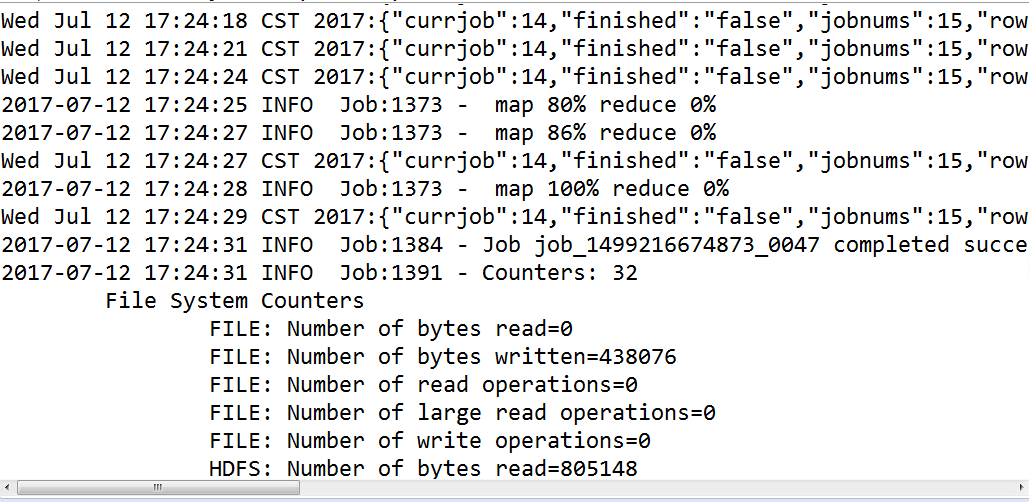
Job job = Job.getInstance(conf,"cluster data with iteration: "+otherArgs[4]+",dc阈值:"+otherArgs[3]);
job.setJarByClass(ClusterDataJob.class);
job.setMapperClass(ClusterDataMapper.class);
job.setNumReduceTasks(0);//不需要reduce方法
// <id,<type,用户有效向量>>
MultipleOutputs.addNamedOutput(job, "clustered", SequenceFileOutputFormat.class,
IntWritable.class, DoubleArrIntWritable.class);
// <id,<type,用户有效向量>>
MultipleOutputs.addNamedOutput(job, "unclustered", SequenceFileOutputFormat.class,
IntWritable.class, DoubleArrIntWritable.class);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
SequenceFileInputFormat.addInputPath(job, new Path(otherArgs[0]));
SequenceFileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
FileSystem.get(conf).delete(new Path(otherArgs[1]), true);
int ret= job.waitForCompletion(true) ? 0 : 1;
// 把已经分类的个数和未分类的个数赋值出去
HUtils.CLUSTERED=job.getCounters().findCounter(ClusterCounter.CLUSTERED).getValue();
HUtils.UNCLUSTERED=job.getCounters().findCounter(ClusterCounter.UNCLUSTERED).getValue();
return ret;
}
}这个MapReduce任务只有map操作,不需要reduce操作。
map方法
/**
* 输入:
* id ,用户有效向量
* 输出:
* id_i, <type_i,用户有效向量>
*/
// Mapper 的输出有两个
public class ClusterDataMapper extends Mapper<IntWritable, DoubleArrIntWritable, IntWritable, DoubleArrIntWritable> {
private Logger log = LoggerFactory.getLogger(ClusterDataMapper.class);
// private String center = null;
// private int k =-1;
private double dc =0.0;
private int iter_i =0;
private int start =0;
private DoubleArrIntWritable typeDoubleArr = new DoubleArrIntWritable();
private IntWritable vectorI = new IntWritable();
private MultipleOutputs<IntWritable,DoubleArrIntWritable> out;
@Override
public void setup(Context cxt){
// center = cxt.getConfiguration().get("CENTER");
// k = cxt.getConfiguration().getInt("K", 3);
dc = cxt.getConfiguration().getDouble("DC", Double.MAX_VALUE);
iter_i=cxt.getConfiguration().getInt("ITER_I", 0);
start=iter_i!=1?1:0;
out = new MultipleOutputs<IntWritable,DoubleArrIntWritable>(cxt);
cxt.getCounter(ClusterCounter.CLUSTERED).increment(0);
cxt.getCounter(ClusterCounter.UNCLUSTERED).increment(0);
log.info("第{}次循环...",iter_i);
}
@Override
public void map(IntWritable key,DoubleArrIntWritable value,Context cxt){
double[] inputI= value.getDoubleArr();
// hdfs
Configuration conf = cxt.getConfiguration();
FileSystem fs = null;
Path path = null;
SequenceFile.Reader reader = null;
try {
fs = FileSystem.get(conf);
// read all before center files
String parentFolder =null;
double smallDistance = Double.MAX_VALUE;
int smallDistanceType=-1;
double distance;
// if iter_i !=0,then start i with 1,else start with 0
for(int i=start;i<iter_i;i++){// all files are clustered points
parentFolder=HUtils.CENTERPATH+"/iter_"+i+"/clustered";
RemoteIterator<LocatedFileStatus> files=fs.listFiles(new Path(parentFolder), false);
while(files.hasNext()){
path = files.next().getPath();
if(!path.toString().contains("part")){
continue; // 只读取文件名包含“part”的文件
}
reader = new SequenceFile.Reader(conf, Reader.file(path),
Reader.bufferSize(4096), Reader.start(0));
IntWritable dkey = (IntWritable) ReflectionUtils.newInstance(
reader.getKeyClass(), conf);
DoubleArrIntWritable dvalue = (DoubleArrIntWritable) ReflectionUtils.newInstance(
reader.getValueClass(), conf);
while (reader.next(dkey, dvalue)) {// 遍历文件
distance = HUtils.getDistance(inputI, dvalue.getDoubleArr());//获取距离
if(distance>dc){// 距离大于阀值,不处理
continue;
}
// 这里只要找到离该点最近的点并且其distance<=dc 即可,把这个点的type赋值给当前值即可
if(distance<smallDistance){
smallDistance=distance;
smallDistanceType=dvalue.getIdentifier();//找到符合要求的数据下标
}
}// while
}// while
}// for
vectorI.set(key.get());// 用户id
typeDoubleArr.setValue(inputI,smallDistanceType);
if(smallDistanceType!=-1){
log.info("clustered-->vectorI:{},typeDoubleArr:{}",new Object[]{vectorI,typeDoubleArr.toString()});
cxt.getCounter(ClusterCounter.CLUSTERED).increment(1);//分类计数加1
out.write("clustered", vectorI, typeDoubleArr,"clustered/part");
}else{
log.info("unclustered---->vectorI:{},typeDoubleArr:{}",new Object[]{vectorI,typeDoubleArr.toString()});
cxt.getCounter(ClusterCounter.UNCLUSTERED).increment(1);//未分类计数加1
out.write("unclustered", vectorI, typeDoubleArr,"unclustered/part");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
IOUtils.closeStream(reader);
}
}
@Override
public void cleanup(Context cxt){
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}三、程序运行截图

相关文章推荐
- Hadoop好友推荐系统-执行聚类算法
- Hadoop好友推荐系统-原始数据去重操作(包含MapReduce任务监控)
- Hadoop好友推荐系统-组别数据入库
- Hadoop好友推荐系统-去重后的数据存入数据库
- Hadoop好友推荐系统-推荐结果查询
- Hadoop好友推荐系统-项目架构搭建和用户登陆的实现
- Hadoop好友推荐系统-寻找聚类中心
- 【备忘】基于Hadoop,Spark大数据技术的推荐系统算法实战教程
- 【备忘】基于Hadoop,Spark大数据技术的推荐系统算法实战教程
- [置顶] 基于Hadoop的好友推荐系统项目综述
- Hadoop好友推荐系统-聚类中心及占比查看
- Hadoop好友推荐系统-寻找最佳DC
- Hadoop好友推荐系统-HDFS的文件上传和下载
- 推荐系统算法分类
- 推荐系统的常用算法概述
- ucos在s3c2410上运行过程整体剖析-从加电到执行main函数 分类: μc /os ii 系统有关知识 2012-03-13 21:27 2409人阅读 评论(1) 收藏
- 推荐系统算法学习导论
- 社会网络分析:探索人人网好友推荐系统
- 震惊!-- CSDN对推荐系统算法的漠视
- 推荐算法分类