Hadoop好友推荐系统-寻找聚类中心
2017-07-14 09:38
441 查看
项目总目录:基于Hadoop的好友推荐系统项目综述
一、前端展示
1、jsp页面
<table> <tr> <td><label for="name">局部密度阈值:</label> </td> <td><input class="easyui-validatebox" type="text" id="center2hdfs_density" data-options="required:true" value="50" /></td> </tr> <tr> <td><label for="name">最小距离阈值:</label> </td> <td><input class="easyui-validatebox" type="text" id="center2hdfs_distance" data-options="required:true" value="50" /></td> </tr> <tr> <td><label for="name">输入路径:</label> </td> <td><input class="easyui-validatebox" type="text" id="center2hdfs_input_id" data-options="required:true" style="width:300px" value="/user/root/sort/part-r-00000" /></td> </tr> <tr> <td><label for="name">本地路径:</label> </td> <td><input class="easyui-validatebox" type="text" id="center2hdfs_localfile_id" data-options="required:true" style="width:300px" value="WEB-INF/classes/centervector.dat" /></td> </tr> <tr> <td><label for="name">输出路径:</label> </td> <td><input class="easyui-validatebox" type="text" id="center2hdfs_output_id" data-options="required:true" style="width:300px" value="/user/root/_center/iter_0/clustered/part-m-00000" /></td> </tr> <tr> <td></td> <td><a id="center2hdfs_submit_id" href="" class="easyui-linkbutton" data-options="iconCls:'icon-door_in'">确定</a></td> </tr> </table>
jsp页面中指定了5个值
局部密度阈值:根据上一步的决策图修改该值;
最小距离阈值:根据上一步的决策图修改该值;
输入路径:指定查找的数据源位置,也就是过滤排序MR的输出路径;
本地路径:把查找的结果保存到本地的目录;
输出路径:把查找的结果保存到HDFS上的目录
2、js逻辑
// cent2hdfs寻找聚类中心---
$('#center2hdfs_submit_id').bind('click', function(){
var density=$('#center2hdfs_density').val();// 局部密度阈值
var distance=$('#center2hdfs_distance').val();// 最小距离阈值
var input_=$('#center2hdfs_input_id').val();
var output_=$('#center2hdfs_output_id').val();
var localfile=$('#center2hdfs_localfile_id').val();
// 弹出进度框
popupProgressbar('寻找聚类中心','聚类中心寻找并上传中...',1000);
// ajax 异步提交任务
console.info('here');
callByAJax('cloud/cloud_center2hdfs.action',{input:input_,output:output_,
numReducerDensity:density,numReducerDistance:distance,method:localfile});
});二、后台逻辑
1、action层
对应的action从这里获取:callByAJax(‘cloud/cloud_center2hdfs.action’)/**
* 根据给定的阈值寻找聚类中心向量,并写入hdfs
* 非MR任务,不需要监控,注意返回值
*/
public void center2hdfs(){
// localfile:method
// 1. 读取SortJob的输出,获取前面k条记录中的大于局部密度和最小距离阈值的id;
// 2. 根据id,找到每个id对应的记录;
// 3. 把记录转为double[] ;
// 4. 把向量写入hdfs
// 5. 把向量写入本地文件中,方便后面的查看
Map<String,Object> retMap=new HashMap<String,Object>();
Map<Object,Object> firstK =null;
List<Integer> ids= null;
List<UserData> users=null;
try{
firstK=HUtils.readSeq(input==null?HUtils.SORTOUTPUT+"/part-r-00000":input,
100);//---1 这里默认读取前100条记录
ids=HUtils.getCentIds(firstK,numReducerDensity,numReducerDistance);
//获取聚类中心的id
users = dBService.getTableData("UserData",ids);//-----2
Utils.simpleLog("聚类中心向量有"+users.size()+"个!");
HUtils.writecenter2hdfs(users,method,output);//----3、4、5
}catch(Exception e){
e.printStackTrace();
retMap.put("flag", "false");
retMap.put("msg", e.getMessage());
Utils.write2PrintWriter(JSON.toJSONString(retMap));
return ;
}
retMap.put("flag", "true");
Utils.write2PrintWriter(JSON.toJSONString(retMap));
return ;
}上述代码的关键语句如下:
ids=HUtils.getCentIds(firstK,numReducerDensity,numReducerDistance); //获取聚类中心的id HUtils.writecenter2hdfs(users,method,output);//----3、4、5
2、获取聚类中心的id
HUtils.getCentIds的定义如下:/**
* 获取firstK中的id
* {key:mul,value:third:id}<first:density_i,second:min_distance_j,third:i>
* @param firstK
* @param numReducerDistance
* @param numReducerDensity
* @return
*/
public static List<Integer> getCentIds(Map<Object, Object> firstK, String numReducerDensity, String numReducerDistance) {
List<Integer> ids = new ArrayList<Integer>();
IntDoublePairWritable v=null;
for(Object i: firstK.values()){//只查找前firstK.values()个记录
v=(IntDoublePairWritable) i;
if(v.getFirst()>Double.parseDouble(numReducerDensity)&&
v.getSecond()>Double.parseDouble(numReducerDistance)){//大于两个阀值,满足条件
ids.add(v.getThird());
}
}
return ids;
}3、将结果数据写入本地和HDFS
HUtils.writecenter2hdfs的定义如下:/**
* 每次写入聚类中心之前,需要把前一次的结果删掉,防止重复,不应该在这里删除,应该在执行分类的时候删除
* 根据给定的users提取出来每个聚类中心,并把其写入hdfs
* key,value--> <IntWritable ,DoubleArrIntWritable> --> <id,<type,用户有效向量>>
* 同时把聚类中心写入本地文件
* @param localfile
* @param users
* @param output
* @throws IOException
*/
public static void writecenter2hdfs(List<UserData> users, String localfile, String output) throws IOException {
localfile=localfile==null?HUtils.LOCALCENTERFILE:localfile;
localfile=Utils.getRootPathBasedPath(localfile);//本地目录
output=output==null?HUtils.FIRSTCENTERPATH:output;//HDFS目录
// 写入hdfs
SequenceFile.Writer writer = null;
Configuration conf = getConf();
try {
Option optPath = SequenceFile.Writer.file(HUtils.getHDFSPath(output, "false"));
Option optVal = SequenceFile.Writer
.valueClass(DoubleArrIntWritable.class);
Option optKey = SequenceFile.Writer.keyClass(IntWritable.class);
writer = SequenceFile.createWriter(conf, optPath, optKey, optVal);
DoubleArrIntWritable dVal = new DoubleArrIntWritable();
IntWritable dKey = new IntWritable();
int k=1;
for (Object user : users) {
dVal.setValue(getDoubleArr(user),k++);
// dVal.setIdentifier(k++);
dKey.set(getIntVal(user));//
writer.append(dKey, dVal);// 用户id,<type,用户的有效向量>
}
} catch (IOException e) {
Utils.simpleLog("writecenter2hdfs 失败,+hdfs file:"+output.toString());
e.printStackTrace();
throw e;
} finally {
IOUtils.closeStream(writer);
}
Utils.simpleLog("聚类中心向量已经写入HDFS:"+output.toString());
// 写入本地文件
FileWriter writer2 = null;
BufferedWriter bw = null;
try {
writer2 = new FileWriter(localfile);
bw = new BufferedWriter(writer2);
for(UserData user:users){
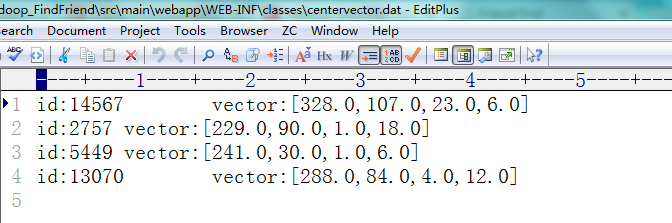
bw.write("id:"+user.getId()+"\tvector:["+
HUtils.doubleArr2Str(HUtils.getDoubleArr(user))+"]");
bw.newLine();
}
} catch (IOException e) {
e.printStackTrace();
throw e;
} finally {
try {
bw.close();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
Utils.simpleLog("聚类中心向量已经写入HDFS:"+localfile.toString());
}三、程序运行截图
1、HDFS目录
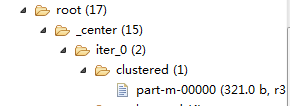
2、本地目录

相关文章推荐
- Hadoop好友推荐系统-聚类中心及占比查看
- Hadoop好友推荐系统-寻找最佳DC
- Hadoop好友推荐系统-去重后的数据存入数据库
- Hadoop好友推荐系统-执行分类算法
- [置顶] 基于Hadoop的好友推荐系统项目综述
- Hadoop好友推荐系统-HDFS的文件上传和下载
- Hadoop好友推荐系统-组别数据入库
- Hadoop好友推荐系统-推荐结果查询
- Hadoop好友推荐系统-执行聚类算法
- Hadoop好友推荐系统-原始数据去重操作(包含MapReduce任务监控)
- Hadoop好友推荐系统-项目架构搭建和用户登陆的实现
- 用Hadoop构建电影推荐系统
- hadoop1-构建电影推荐系统
- 用Hadoop构建电影推荐系统
- 用Hadoop构建电影推荐系统
- Hadoop连载系列之四:数据收集分析系统Chukwa 推荐
- hadoop实现购物商城推荐系统
- hadoop学习-Netflix电影推荐系统
- hadoop学习-Netflix电影推荐系统
- Hadoop应用开发--基于MapReduce推荐系统的实现