Hadoop好友推荐系统-数据库过滤数据到HDFS
2017-07-13 09:31
501 查看
项目总目录:基于Hadoop的好友推荐系统项目综述
数据库过滤数据到HDFS
1、前端展示
jsp页面<table> <tr> <td><label for="name">输出路径:</label> </td> <td><input class="easyui-validatebox" type="text" id="preprocess_output_id" data-options="required:true" style="width:300px" value="/user/root/_filter/preparevectors" /></td> </tr> <tr> <td><label for="name">生成文件个数:</label> </td> <td><input class="easyui-validatebox" type="text" id="preprocess_record_id" data-options="required:true" style="width:300px" value="4" /></td> </tr> <tr> <td></td> <td><a id="preprocess_submit_id" href="" class="easyui-linkbutton" data-options="iconCls:'icon-door_in'">预处理</a></td> </tr> </table> </div>
js逻辑
// ===== 数据预处理 数据库到HDFS
$('#preprocess_submit_id').bind('click', function(){
var record_=$('#preprocess_record_id').val();
var output_=$('#preprocess_output_id').val();
// 弹出进度框
popupProgressbar('请等待','数据库数据解析并序列化到HFDS中...',1000);
// ajax 异步提交任务
callByAJax('cloud/cloud_db2hdfs.action',{record:record_,output:output_});
});2、后端逻辑
action层/**
* 数据库数据解析到云平台,为序列文件,是聚类运行的输入文件
*
* [IntWritable,DoubleArrIntWritable]
*/
public void db2hdfs(){
List<Object> list = dBService.getTableAllData("UserData");
Map<String,Object> map = new HashMap<String,Object>();
if(list.size()==0){
map.put("flag", "false");
Utils.write2PrintWriter(JSON.toJSONString(map));
return ;
}
try{
HUtils.db2hdfs(list,output,Integer.parseInt(record));//解析入库
}catch(Exception e){
map.put("flag", "false");
map.put("msg", e.getMessage());
Utils.write2PrintWriter(JSON.toJSONString(map));
return ;
}
map.put("flag", "true");
Utils.write2PrintWriter(JSON.toJSONString(map));
return ;
}其中HUtils.db2hdfs的定义如下:
/**
* List 解析入HDFS
*
* @param list
* @param fileNums
* @throws IOException
*/
public static void db2hdfs(List<Object> list,String url, int fileNums) throws IOException {
if(fileNums<=0||fileNums>9){
fileNums=HUtils.FILTER_PREPAREVECTORS_FILES;
}
int everyFileNum=(int)Math.ceil((double)list.size()/fileNums);//根据输入记录数和输出文件数计算每个文件存储的记录数
Path path=null;
int start=0;
int end=start+everyFileNum;
for(int i=0;i<fileNums;i++){
// 如果url为空,那么使用默认的即可,否则使用提供的路径
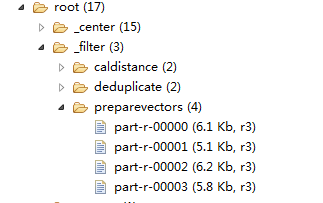
path= new Path(url==null?HUtils.FILTER_PREPAREVECTORS:url+"/part-r-0000"+i);//指定文件输出目录和文件名
if(end>list.size()){
end=list.size();
}
try{
db2hdfs(list.subList(start, end),path);
start=end;
end+=everyFileNum;
}catch(IOException e){
throw e;
}
}
Utils.simpleLog("db2HDFS 全部解析上传完成!");
}
private static boolean db2hdfs(List<Object> list, Path path) throws IOException {
boolean flag =false;
int recordNum=0;
SequenceFile.Writer writer = null;
Configuration conf = getConf();
try {
Option optPath = SequenceFile.Writer.file(path);
Option optKey = SequenceFile.Writer
.keyClass(IntWritable.class);
Option optVal = SequenceFile.Writer.valueClass(DoubleArrIntWritable.class);
writer = SequenceFile.createWriter(conf, optPath, optKey, optVal);
DoubleArrIntWritable dVal = new DoubleArrIntWritable();
IntWritable dKey = new IntWritable();
for (Object user : list) {
if(!checkUser(user)){
continue; // 不符合规则
}
dVal.setValue(getDoubleArr(user),-1);
dKey.set(getIntVal(user));
writer.append(dKey, dVal);// 用户id,<type,用户的有效向量 >// 后面执行分类的时候需要统一格式,所以这里需要反过来
recordNum++;
}
} catch (IOException e) {
Utils.simpleLog("db2HDFS失败,+hdfs file:"+path.toString());
e.printStackTrace();
flag =false;
throw e;
} finally {
IOUtils.closeStream(writer);
}
flag=true;
Utils.simpleLog("db2HDFS 完成,hdfs file:"+path.toString()+",records:"+recordNum);
return flag;
}
/**
* 检查用户是否符合规则
* 规则 :reputation>15,upVotes>0,downVotes>0,views>0的用户
* @param user
* @return
*/
private static boolean checkUser(Object user) {
UserData ud = (UserData)user;
if(ud.getReputation()<=15) return false;
if(ud.getUpVotes()<=0) return false;
if(ud.getDownVotes()<=0) return false;
if(ud.getViews()<=0) return false;
return true;
}service层
/**
* 获得tableName的所有数据并返回
*
* @param tableName
* @return
*/
public List<Object> getTableAllData(String tableName) {
String hql = "from " + tableName + " ";
List<Object> list = null;
try {
list = baseDao.find(hql);
} catch (Exception e) {
e.printStackTrace();
}
return list;
}二、程序运行截图
1、前端
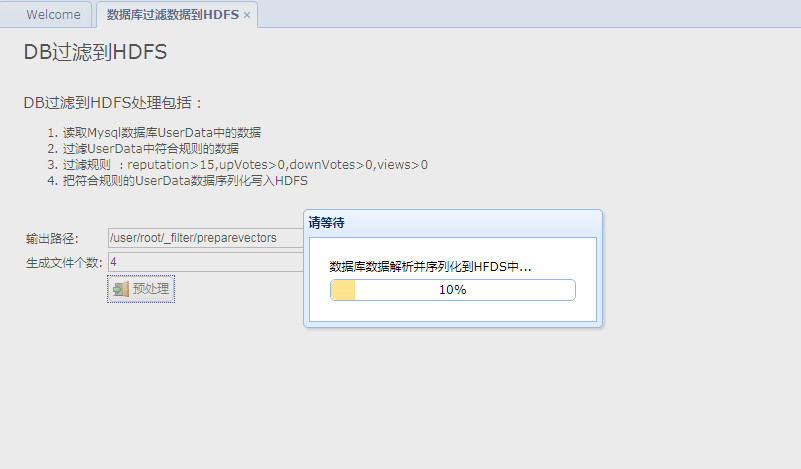
2、后台

3、查看HDFS目录

相关文章推荐
- 一脸懵逼学习HBase---基于HDFS实现的。(Hadoop的数据库,分布式的,大数据量的,随机的,实时的,非关系型数据库)
- php的CodeIgniter框架中如何过滤数据(将危险数据如html类型的数据过滤后提交到数据库)
- Hadoop源码分析HDFS Client向HDFS写入数据的过程解析
- Hadoop学习——HDFS数据备份与放置策略
- Hadoop第一个程序,利用API向HDFS中写入数据
- 利用SQOOP将数据从数据库导入到HDFS
- 从数据库安全取数据基类(过滤数据库读取未知错误)
- 利用SQOOP将数据从数据库导入到HDFS
- Hadoop数据工具sqoop,导入HDFS,HIVE,HBASE,导出到oracle
- Hadoop源码分析HDFS Client向HDFS写入数据的过程解析
- sqoop倒入数据到HDFS或者HDFS倒入数据到数据库
- 利用Sqoop将数据从数据库导入到HDFS(转)
- Hadoop源代码的边角料:HDFS的数据通信机制
- php的CodeIgniter框架中如何过滤数据(将危险数据如html类型的数据过滤后提交到数据库)
- 利用SQOOP将数据从数据库导入到HDFS
- Hadoop源代码的边角料:HDFS的数据通信机制
- 利用Sqoop将数据从数据库导入到HDFS
- sqoop从关系型数据库导数据到hdfs和hbase上
- Hadoop学习——HDFS数据备份与放置策略