日志系列--程序日志处理挑战与方案
2017-07-12 00:00
232 查看
摘要: 程序日志(AppLog)有什么特点? * 内容最全:程序日志是由程序员给出,在重要的地点、变量数值以及异常都会有记录,可以说线上90%以上Bug都是依靠程序日志输出定位到 * 格式比较随意:代码往往经过不同人开发,每个程序员都有自己爱好的格式,一般非常难进行统一,并且引入的一些第三方库的
格式比较随意:代码往往经过不同人开发,每个程序员都有自己爱好的格式,一般非常难进行统一,并且引入的一些第三方库的日志风格也不太一样
有一定共性:虽然格式随意,但一般都会有一些共性的地方,例如对Log4J日志而言,会有如下几个字段是必须的:
时间
级别(Level)
所在文件或类(file or class)
行数(Line Number)
线程号(ThreadId)
则日志总数为:
每条长度为200字节,则存储大小为
这个数据会随着业务系统复杂变得更大,一天100-200GB日志对一个中型网站而言是很常见的。
服务器
Docker(容器)
函数计算(容器服务)
对应实例数目会从几个到几千,需要有一种跨服务器的日志采集方案
应用相关的会在容器中
API相关日志会在FunctionCompute中
旧系统日志在传统IDC中
移动端相关日志在用户处
网页端(M站)在浏览器里
为了能够获得全貌,我们必须把所有数据统一并存储起来。
我们可以在日志服务中创建一个项目来存储应用日志,日志服务提供30+种日志采集手段:无论是在硬件服务器中埋点,还是网页端JS,或是服务器上输出日志,都可以在实时采集列表中找到。
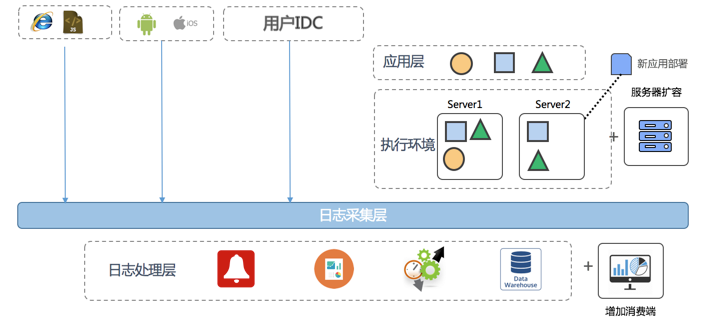
在服务器日志上,除了使用SDK等直接写入外,日志服务提供便捷、稳定、高性能Agent-Logtail。logtail提供windows、linux两个版本,在控制台定义好机器组,日志采集配置后,就能够实时将服务日志进行采集,这里有一个5分钟视频。
在创建完成一个日志采集配置后,我们就可以在项目中操作各种日志了。
可能有人要问到,日志采集Agent非常多,有Logstash,Flume,FluentD,以及Beats等,Logtash和这些相比有什么特点吗?
使用便捷:提供API、远程管理与监控功能,融入阿里集团百万级服务器日志采集管理经验,配置一个采集点到几十万设备只需要几秒钟
适应各种环境:无论是公网、VPC、用户自定义IDC等都可以支持,https以及断点续传功能使得接入公网数据也不再话下
性能强,对资源消耗非常小:经过多年磨练,在性能和资源消耗方面比开源要好,详见对比测试
例如有一个订单错误,一个延时很长,我们如何能够在一周几TB数据量日志中快速定位到问题。其中还会涉及到各种条件过滤和排查等。
例如我们对于程序中记录延时的日志,调查延时大于1秒,并且方法以Post开头的请求数据:
对于日志中查找包含error关键词,不包含merge关键词的日志
一天的结果

一周的结果

更长时间结果

这些查询都是在不到1秒时间内可以返回
进程内关联:一般比较简单,因为同一个函数前后日志都在一个文件中。在多线程环节中,我们只要根据线程Id进行过滤即可
跨进程关联:跨进程的请求一般没有明确线索,一般会通过RPC中传入TracerId来进行关联

程序日志(AppLog)有什么特点?
内容最全:程序日志是由程序员给出,在重要的地点、变量数值以及异常都会有记录,可以说线上90%以上Bug都是依靠程序日志输出定位到格式比较随意:代码往往经过不同人开发,每个程序员都有自己爱好的格式,一般非常难进行统一,并且引入的一些第三方库的日志风格也不太一样
有一定共性:虽然格式随意,但一般都会有一些共性的地方,例如对Log4J日志而言,会有如下几个字段是必须的:
时间
级别(Level)
所在文件或类(file or class)
行数(Line Number)
线程号(ThreadId)
处理程序日志会有哪些挑战?
1. 数据量大
程序日志一般会比访问日志大1个数量级:假设一个网站一天有100W次独立访问,每个访问大约有20逻辑模块,在每个逻辑模块中有10个主要逻辑点需要记录日志。则日志总数为:
100W * 20 * 10 = 2 * 10^8 条
每条长度为200字节,则存储大小为
2 * 10^8 * 200 = 4 * 10^10 = 40 GB
这个数据会随着业务系统复杂变得更大,一天100-200GB日志对一个中型网站而言是很常见的。
2. 分布服务器多
大部分应用都是无状态模式,跑在不同框架中,例如:服务器
Docker(容器)
函数计算(容器服务)
对应实例数目会从几个到几千,需要有一种跨服务器的日志采集方案
3. 运行环境复杂
程序会落到不同的环境上,例如:应用相关的会在容器中
API相关日志会在FunctionCompute中
旧系统日志在传统IDC中
移动端相关日志在用户处
网页端(M站)在浏览器里
为了能够获得全貌,我们必须把所有数据统一并存储起来。
如何解决程序日志需求
1.统一存储
目标:要把各渠道数据采集到一个集中化中心,打通才可以做后续事情。我们可以在日志服务中创建一个项目来存储应用日志,日志服务提供30+种日志采集手段:无论是在硬件服务器中埋点,还是网页端JS,或是服务器上输出日志,都可以在实时采集列表中找到。
在服务器日志上,除了使用SDK等直接写入外,日志服务提供便捷、稳定、高性能Agent-Logtail。logtail提供windows、linux两个版本,在控制台定义好机器组,日志采集配置后,就能够实时将服务日志进行采集,这里有一个5分钟视频。
在创建完成一个日志采集配置后,我们就可以在项目中操作各种日志了。
可能有人要问到,日志采集Agent非常多,有Logstash,Flume,FluentD,以及Beats等,Logtash和这些相比有什么特点吗?
使用便捷:提供API、远程管理与监控功能,融入阿里集团百万级服务器日志采集管理经验,配置一个采集点到几十万设备只需要几秒钟
适应各种环境:无论是公网、VPC、用户自定义IDC等都可以支持,https以及断点续传功能使得接入公网数据也不再话下
性能强,对资源消耗非常小:经过多年磨练,在性能和资源消耗方面比开源要好,详见对比测试
2. 快速查找定位
目标:无论数据量如何增长、服务器如何部署,都可以保证定位问题时间是恒定的例如有一个订单错误,一个延时很长,我们如何能够在一周几TB数据量日志中快速定位到问题。其中还会涉及到各种条件过滤和排查等。
例如我们对于程序中记录延时的日志,调查延时大于1秒,并且方法以Post开头的请求数据:
Latency > 1000000 and Method=Post*
对于日志中查找包含error关键词,不包含merge关键词的日志
一天的结果
一周的结果
更长时间结果
这些查询都是在不到1秒时间内可以返回
3. 关联分析
关联有两种类型,进程内关联与跨进程关联。我们先来看看两者有什么区别:进程内关联:一般比较简单,因为同一个函数前后日志都在一个文件中。在多线程环节中,我们只要根据线程Id进行过滤即可
跨进程关联:跨进程的请求一般没有明确线索,一般会通过RPC中传入TracerId来进行关联

相关文章推荐
- 日志系列--程序日志处理挑战与方案
- 日志系列--程序日志处理挑战与方案
- 程序员必看的程序日志处理挑战与方案!(阿里云日志管理平台)
- 日志系列--计量日志处理方案
- 日志系列-常见处理方案
- 【Firewall系列一】浅析基于区域的防火墙方案如何监测网络环境中内外流量与程序会话
- 爱上MVC3系列~全局异常处理与异常日志
- iBatisnet系列(二) 配置运行环境和日志处理
- 使用IsLine FrameWork开发ASP.NET程序之四—使用AppLogProvider日志处理框架
- iBatisnet系列(二) 配置运行环境和日志处理
- memcache系列--处理缓存的三种方案(三)
- 利用日志备份实现双服务器方案的处理示例.sql
- Spring.Net学习系列一(续):日志处理
- 系统日志处理系列 (一)如何使用logging、commons-logging、log4j输出日志
- SSH异常和日志处理方案
- 程序的异常处理及输出本地日志
- 彰显程序的美丽与魅力——Ajax系列之四之错误处理
- 第六周实验指导--下面的程序存在编译错误,请给出两种修改方案--说明处理此类问题的原则是什么
- 用正则表达式处理日志文件的小程序
- Linux 脚本和程序对SIGINT的处理方案,脚本通过kill给程序传递信号