mysql架构及sql执行顺序
2017-07-11 23:58
531 查看
Mysql体系架构
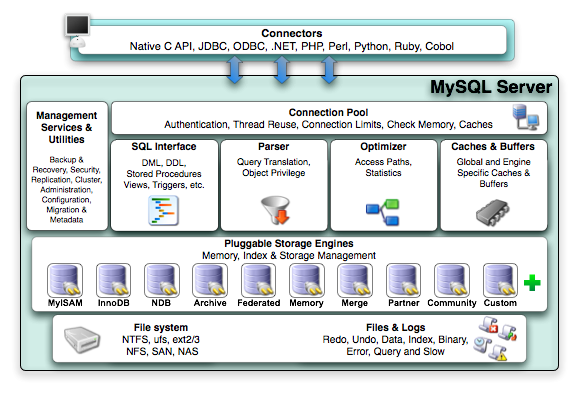
1 Connectors指的是不同语言中与SQL的交互
2.Management
Serveices & Utilities: 系统管理和控制工具
3.Connection
Pool: 连接池
管理缓冲用户连接,线程处理等需要缓存的需求
4.SQL
Interface: SQL接口
接受用户的SQL命令,并且返回用户需要查询的结果。比如select
from就是调用SQL Interface
5.Parser:
解析器
SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本
主要功能:
a . 将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的
b. 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的
6 Optimizer: 查询优化器
7 Cache和Buffer:
查询缓存
8
Engine :存储引擎。
存储引擎是MySql中具体的与文件打交道的子系统。也是Mysql最具有特色的一个地方
Mysql的存储引擎是插件式的。它根据MySql AB公司提供的文件访问层的一个抽象接口来定制一种文件访问机制(这种访问机制就叫存储引擎)
默认下MySql是使用MyISAM引擎,它查询速度快,有较好的索引优化和数据压缩技术。但是它不支持事务
InnoDB支持事务,并且提供行级的锁定,应用也相当广泛
Mysql也支持自己定制存储引擎,甚至一个库中不同的表使用不同的存储引擎,这些都是允许的

FORM: 对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1
ON: 对虚表VT1进行ON筛选,只有那些符合<join-condition>的行才会被记录在虚表VT2中。
JOIN: 如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3, rug from子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这三个步骤,一直到处理完所有的表为止。
WHERE: 对虚拟表VT3进行WHERE条件过滤。只有符合<where-condition>的记录才会被插入到虚拟表VT4中。
GROUP BY: 根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5.
CUBE | ROLLUP: 对表VT5进行cube或者rollup操作,产生表VT6.
HAVING: 对虚拟表VT6应用having过滤,只有符合<having-condition>的记录才会被 插入到虚拟表VT7中。
SELECT: 执行select操作,选择指定的列,插入到虚拟表VT8中。
DISTINCT: 对VT8中的记录进行去重。产生虚拟表VT9.
ORDER BY: 将虚拟表VT9中的记录按照<order_by_list>进行排序操作,产生虚拟表VT10.
LIMIT:取出指定行的记录,产生虚拟表VT11, 并将结果返回
1 Connectors指的是不同语言中与SQL的交互
2.Management
Serveices & Utilities: 系统管理和控制工具
3.Connection
Pool: 连接池
管理缓冲用户连接,线程处理等需要缓存的需求
4.SQL
Interface: SQL接口
接受用户的SQL命令,并且返回用户需要查询的结果。比如select
from就是调用SQL Interface
5.Parser:
解析器
SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本
主要功能:
a . 将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的
b. 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的
6 Optimizer: 查询优化器
7 Cache和Buffer:
查询缓存
8
Engine :存储引擎。
存储引擎是MySql中具体的与文件打交道的子系统。也是Mysql最具有特色的一个地方
Mysql的存储引擎是插件式的。它根据MySql AB公司提供的文件访问层的一个抽象接口来定制一种文件访问机制(这种访问机制就叫存储引擎)
默认下MySql是使用MyISAM引擎,它查询速度快,有较好的索引优化和数据压缩技术。但是它不支持事务
InnoDB支持事务,并且提供行级的锁定,应用也相当广泛
Mysql也支持自己定制存储引擎,甚至一个库中不同的表使用不同的存储引擎,这些都是允许的
MySQL的语句执行顺序
FORM: 对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1
ON: 对虚表VT1进行ON筛选,只有那些符合<join-condition>的行才会被记录在虚表VT2中。
JOIN: 如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3, rug from子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这三个步骤,一直到处理完所有的表为止。
WHERE: 对虚拟表VT3进行WHERE条件过滤。只有符合<where-condition>的记录才会被插入到虚拟表VT4中。
GROUP BY: 根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5.
CUBE | ROLLUP: 对表VT5进行cube或者rollup操作,产生表VT6.
HAVING: 对虚拟表VT6应用having过滤,只有符合<having-condition>的记录才会被 插入到虚拟表VT7中。
SELECT: 执行select操作,选择指定的列,插入到虚拟表VT8中。
DISTINCT: 对VT8中的记录进行去重。产生虚拟表VT9.
ORDER BY: 将虚拟表VT9中的记录按照<order_by_list>进行排序操作,产生虚拟表VT10.
LIMIT:取出指定行的记录,产生虚拟表VT11, 并将结果返回

相关文章推荐
- MySQL架构总览->查询执行流程->SQL解析顺序
- MySQL逻辑架构、SQL加载执行顺序、七种JOIN模式图解
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
- MySQL架构总览->查询执行流程->SQL解析顺序
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
- mysql sql执行顺序
- MySql SQL语句执行的顺序
- 一条sql语句搞定基于mysql的sql执行顺序的基本理解
- mysql sql语句执行顺序
- MYSQL学习心得(4) --SQL语句执行顺序
- mysql 执行顺序 SQL语句执行顺序分析
- MySQL-SQL语句中SELECT语句的执行顺序
- mysql sql语句执行顺序
- mysql 执行顺序 SQL语句执行顺序分析
- 关于sql和MySQL的语句执行顺序(必看!!!)
- mysql 执行顺序 SQL语句执行顺序分析