Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
2017-07-09 14:22
281 查看
最近在公司需要计算手机信令数据 但是每次spark读取文件的时候都是把当天24小时从头到尾读取一遍 非常耗时,在一步操作中处理批量文件,这个要求很常见。举例来说,处理日志的MapReduce作业可能会分析一个月的文件,这些文件被包含在大量目录中。Hadoop有一个通配的操作,可以方便地使用通配符在一个表达式中核对多个文件,不需要列举每个文件和目录来指定输入如下图所示:
点击打开链接
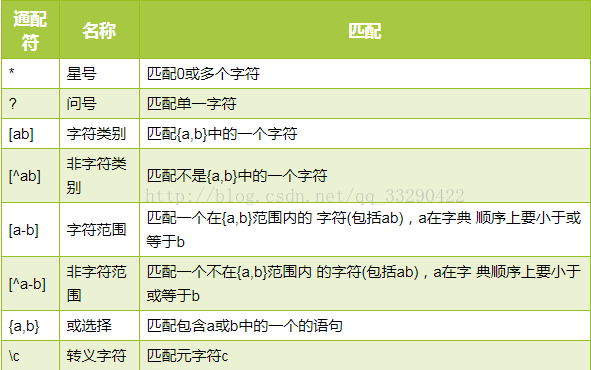
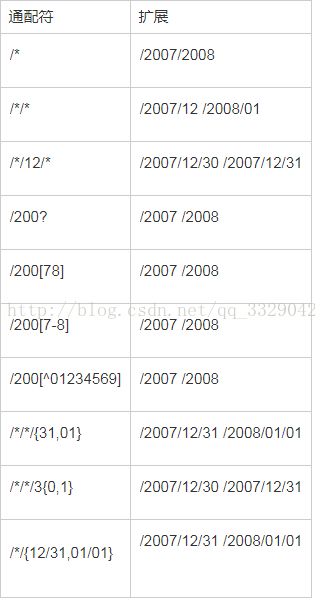
例如 我想读取 hdfs://master:9000/population/unicom_phone/pekin/20150701/02
和hdfs://master:9000/population/unicom_phone/pekin/20150701/03的文件
也就是我想读20150701 下的02 和03文件 通过通配符可以写成如下:
hdfs://master:9000/population/unicom_phone/pekin/20150701/0[2-3]
再次执行 计算速度快了四倍。
Fei joe
点击打开链接
点击打开链接
例如 我想读取 hdfs://master:9000/population/unicom_phone/pekin/20150701/02
和hdfs://master:9000/population/unicom_phone/pekin/20150701/03的文件
也就是我想读20150701 下的02 和03文件 通过通配符可以写成如下:
hdfs://master:9000/population/unicom_phone/pekin/20150701/0[2-3]
再次执行 计算速度快了四倍。
Fei joe
点击打开链接

相关文章推荐
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- Hadoop 和 spark 读取多个文件通配符规则(正则表达式)joe
- spark读取hdfs文件的路径使用正则表达式
- Hadoop和spark中读取文件通配符使用举例
- hadoop输入路径读取文件的正则通配符
- spark 读取hadoop 格式的文件