《数据压缩》实验报告六·MPEG-1 Audio编码器
2017-07-09 12:29
183 查看
一.实验原理
1.MPEG-1 层二编码器原理
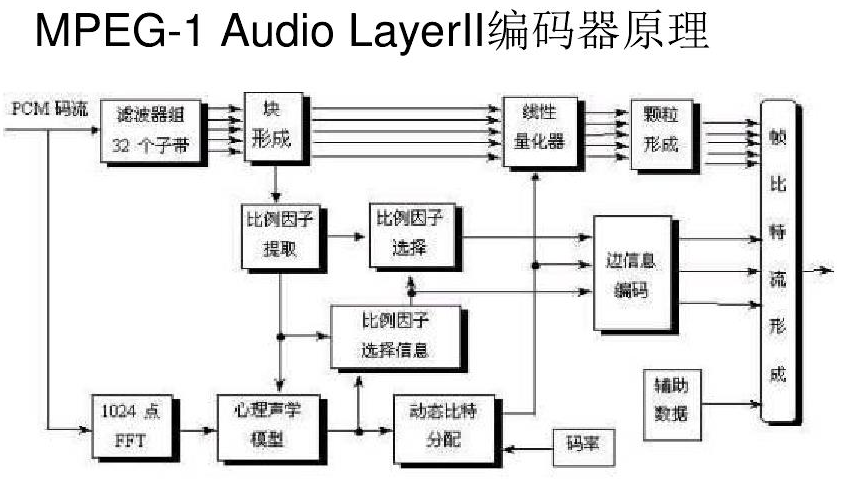
多相滤波器组:将pcm样本变换到32个子带的频域信号,如果输入的采样频率为48khz,那么子带宽度为48/(2*32)=0.75hz。
心理声学模型:计算信号中不可感知的部分,利用人耳的掩蔽效应,找到声音信号中冗余的部分。
比特分配器:根据心理声学模型的计算结果,为每个子带信号分配比特数。
装帧:根据MPEG-1的编码格式产生兼容的比特流。
2.音频信号与语音信号
通常将人耳可以听到的频率在20hz-20khz的声波称为声音信号,声音振动被拾音器转化为的电信号称为音频信号。人说话的信号频率在300hz到3000hz,将该频段的信号称为语音信号。
3.压缩的可能性
声音信号中存在大量的冗余信息,在不同的分析域冗余的表现不同,结合时域和频率域可以较好的去除冗余。在时域,信号的幅度分度非均匀,小幅度样值出现概率比大幅度样值出现概率高;语音信号变化比较缓慢,各信号样值间的相关性较强,可以用差分编码去除冗余。在频域,长时功率谱函数分布非均匀,低频能量高,高频能量低。
声音中存在一些人耳感觉不到的部分,根据人耳的心理听觉模型可以找出这部分冗余信息,并把它去除掉,而不影响人的听觉效果。
二.实验步骤
①理解程序设计的整体框架
②理解感知音频编码的设计思想
③理解心理声学模型的实现过程
④理解码率分配的实现思路
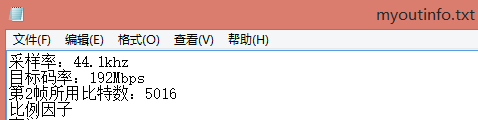
⑤输出音频的采样率和目标码率
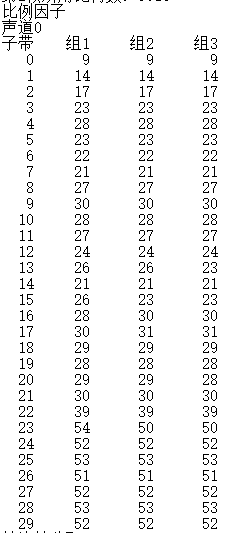
⑥选择其中一个数据帧输出该帧所分配的比特因子和比特分配结果
三.添加代码
FILE* outinfo=NULL;
char outinfoname[50]= "myoutinfo.txt";
outinfo = fopen(outinfoname, "wb");……
transmission_pattern (scalar, scfsi, &frame);
main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
if (error_protection)
CRC_calc (&frame, bit_alloc, scfsi, &crc);
encode_info (&frame, &bs);
if (error_protection)
encode_CRC (crc, &bs);
encode_bit_alloc (bit_alloc, &frame, &bs);
encode_scale (bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);
sample_encoding (*subband, bit_alloc, &frame, &bs);
if(frameNum==25)
{
fprintf(outinfo,"比例因子\r\n");
for ( cha = 0; cha < nch; cha++ )//声道
{
fprintf(outinfo,"声道%d\r\n",cha);
fprintf(outinfo,"子带\t组1\t组2\t组3\t\r\n");
for ( sbd = 0; sbd < frame.sblimit; sbd++ )//子带
{
fprintf(outinfo,"%4d\t",sbd);
for( gro = 0; gro < 3; gro++ )//组
{
fprintf(outinfo,"%3d\t",scalar[cha][gro][sbd]);
}
fprintf(outinfo,"\r\n");
}
}
fprintf(outinfo,"帧比特分配:\r\n");
for ( cha = 0; cha < nch; cha++ )//声道
{
fprintf(outinfo,"声道%d\r\n",cha);
for ( sbd = 0; sbd < frame.sblimit; sbd++ )//子带
{
fprintf(outinfo,"子带%2d:\t",sbd);
fprintf(outinfo,"%2d\r\n",bit_alloc[cha][sbd]);
}
}
if(outinfo)
fclose(outinfo);
四.实验结果

五.实验结果分析
实验输出结果表明,同一子带的三个比例因子相差较小,所以可以用比例因子选择的方法压缩文件;从帧比特分配来看,高频子带分配比特数较少,低频子带分批比特数较多。
1.MPEG-1 层二编码器原理
多相滤波器组:将pcm样本变换到32个子带的频域信号,如果输入的采样频率为48khz,那么子带宽度为48/(2*32)=0.75hz。
心理声学模型:计算信号中不可感知的部分,利用人耳的掩蔽效应,找到声音信号中冗余的部分。
比特分配器:根据心理声学模型的计算结果,为每个子带信号分配比特数。
装帧:根据MPEG-1的编码格式产生兼容的比特流。
2.音频信号与语音信号
通常将人耳可以听到的频率在20hz-20khz的声波称为声音信号,声音振动被拾音器转化为的电信号称为音频信号。人说话的信号频率在300hz到3000hz,将该频段的信号称为语音信号。
3.压缩的可能性
声音信号中存在大量的冗余信息,在不同的分析域冗余的表现不同,结合时域和频率域可以较好的去除冗余。在时域,信号的幅度分度非均匀,小幅度样值出现概率比大幅度样值出现概率高;语音信号变化比较缓慢,各信号样值间的相关性较强,可以用差分编码去除冗余。在频域,长时功率谱函数分布非均匀,低频能量高,高频能量低。
声音中存在一些人耳感觉不到的部分,根据人耳的心理听觉模型可以找出这部分冗余信息,并把它去除掉,而不影响人的听觉效果。
二.实验步骤
①理解程序设计的整体框架
②理解感知音频编码的设计思想
③理解心理声学模型的实现过程
④理解码率分配的实现思路
⑤输出音频的采样率和目标码率
⑥选择其中一个数据帧输出该帧所分配的比特因子和比特分配结果
三.添加代码
FILE* outinfo=NULL;
char outinfoname[50]= "myoutinfo.txt";
outinfo = fopen(outinfoname, "wb");……
if(frameNum==25)
{
fprintf(outinfo,"采样率:%.1fkhz\r\n",s_freq[header.version][header.sampling_frequency]);
fprintf(outinfo,"目标码率:%dMbps\r\n",bitrate[header.version][header.bitrate_index]);
fprintf(outinfo,"第%d帧所用比特数:%d\r\n",frameNum,adb);
}……transmission_pattern (scalar, scfsi, &frame);
main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
if (error_protection)
CRC_calc (&frame, bit_alloc, scfsi, &crc);
encode_info (&frame, &bs);
if (error_protection)
encode_CRC (crc, &bs);
encode_bit_alloc (bit_alloc, &frame, &bs);
encode_scale (bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);
sample_encoding (*subband, bit_alloc, &frame, &bs);
if(frameNum==25)
{
fprintf(outinfo,"比例因子\r\n");
for ( cha = 0; cha < nch; cha++ )//声道
{
fprintf(outinfo,"声道%d\r\n",cha);
fprintf(outinfo,"子带\t组1\t组2\t组3\t\r\n");
for ( sbd = 0; sbd < frame.sblimit; sbd++ )//子带
{
fprintf(outinfo,"%4d\t",sbd);
for( gro = 0; gro < 3; gro++ )//组
{
fprintf(outinfo,"%3d\t",scalar[cha][gro][sbd]);
}
fprintf(outinfo,"\r\n");
}
}
fprintf(outinfo,"帧比特分配:\r\n");
for ( cha = 0; cha < nch; cha++ )//声道
{
fprintf(outinfo,"声道%d\r\n",cha);
for ( sbd = 0; sbd < frame.sblimit; sbd++ )//子带
{
fprintf(outinfo,"子带%2d:\t",sbd);
fprintf(outinfo,"%2d\r\n",bit_alloc[cha][sbd]);
}
}
if(outinfo)
fclose(outinfo);
四.实验结果
| 原文件大小 | 压缩后文件大小 | 压缩比 |
| 2.83MB | 791KB | 3.58 |
实验输出结果表明,同一子带的三个比例因子相差较小,所以可以用比例因子选择的方法压缩文件;从帧比特分配来看,高频子带分配比特数较少,低频子带分批比特数较多。

相关文章推荐
- 数据压缩实验二:bmp转yuv格式实验报告
- 《数据压缩》实验报告三·Huffman编解码算法实现与压缩效率分析
- 【数据压缩】RGB2YUV/YUV2RGB实验报告
- 《数据压缩》实验报告一·YUV2RGB实验
- 数据压缩 实验报告一
- 《数据压缩》实验报告五·JPEG编解码
- 《数据压缩》实验报告四·DPCM编解码
- 数据压缩 实验报告一 彩色空间转换
- 20145230java实验报告1
- 20145321 实验一实验报告
- 结对实验报告
- 20145212《Java程序设计》实验报告一:Java开发环境的熟悉(Windows+IDE)
- 20145304 实验一实验报告
- 结对实验报告
- 20145235 《Java程序设计》第一次实验报告
- 实验报告三
- C++程序设计实验报告(六十八)---第十二周任务四
- 20145216史婧瑶《Java程序设计》第一次实验报告
- Sitemesh对于性能的影响实验报告
- 第十二周实验报告2