二叉查找树的简单实现
2017-07-07 10:55
344 查看
二叉查找树首先也是个二叉树,符合二叉树的一切特点。
原文地址:http://blog.csdn.net/qq_25806863/article/details/74638590
下面是两个的区别:
二叉查找树:
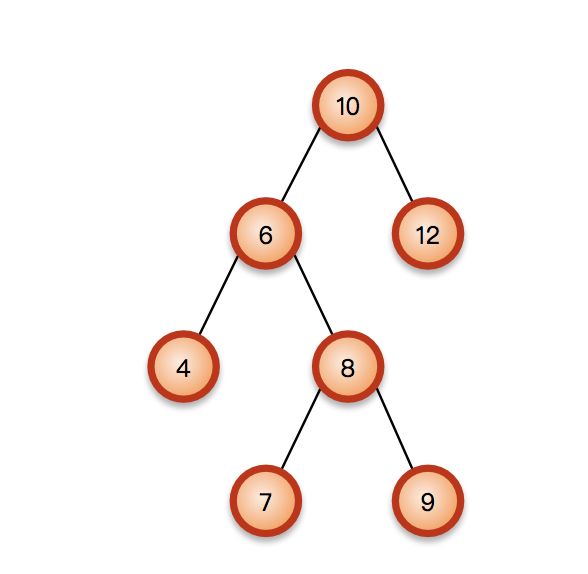
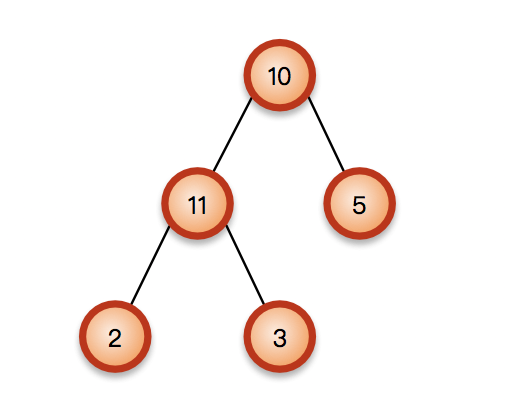
不是二叉查找树:
这里对删除的处理是,找到右子树中的最小值,把这个最小值放在当前节点上,然后从右子树中删除这个值。
而在insert的时候,是根据比较而随机的插入在左右子树上的。
所以如果交叉调用insert和remove很多次的话,这个二叉树会变得很不平衡,即左右子树的高度差很大。
这种平衡的二叉查找树叫平衡查找树。
一个最古老的平衡查找树是AVL树。
参考《数据结构与算法分析java版》

原文地址:http://blog.csdn.net/qq_25806863/article/details/74638590
简单介绍
但是二叉查找树要求对树中的每个节点,这个节点的左子树中所有的值要小于自己,右子树中所有的值要大于自己。下面是两个的区别:
二叉查找树:
不是二叉查找树:
简单实现
主要是查询,插入和删除的方法public class MySearchTree<E extends Comparable<E>> {
private BinaryNode<E> root;
public MySearchTree() {
root = null;
}
public void makeEmpty() {
root = null;
}
public boolean isEmpty() {
return root == null;
}
public boolean contains(E x) {
return contains(x, root);
}
public E findMin() {
return findMin(root).element;
}
public E findMax() {
return findMax(root).element;
}
public void insert(E x) {
root = insert(x, root);
}
public void remove(E x) {
remove(x, root);
}
public void printTree() {
printTree(root);
}
/**
* 如果这个树上的值就是要查找的x,返回true
* 如果树为空,说明不存在这个值,返回false
* 如果x小于这个树上的值,就在这个树的左子树上递归查找
* 如果x大于这个树上的值,就在这个树的右子树上递归查找
*/
private boolean contains(E x, BinaryNode<E> tree) {
if (tree == null) {
return false;
}
int compareResult = x.compareTo(tree.element);
if (compareResult < 0) {
return contains(x, tree.left);
} else if (compareResult > 0) {
return contains(x, tree.right);
} else {
return true;
}
}
/**
* 只要有左子树就一直往左找,左子树为空说明这个就是最小值
*/
private BinaryNode<E> findMin(BinaryNode<E> tree) {
if (tree == null) {
return null;
} else if (tree.left == null) {
return tree;
} else {
return findMin(tree.left);
}
}
/**
* 只要有右子树就一直往左找,右子树为空说明这个就是最大值
*/
private BinaryNode<E> findMax(BinaryNode<E> tree) {
if (tree == null) {
return null;
} else if (tree.right == null) {
return tree;
} else {
return findMax(tree.right);
}
}
/**
* 如果要插入的树是null,说明这个就是要插入的值该放的位置,new一个子树,绑定到对应的父亲上
* 如果树不为null,说明这个树上有值,拿x和这个值进行比较
* 如果两个值相等,说明已经有这个值了,可以进行一些处理
* 如果x小于树上的值,就往该树的左子树上递归插入
* 如果x大于树上的值,就往该树的右子树上递归插入
*/
private BinaryNode<E> insert(E x, BinaryNode<E> tree) {
if (tree == null) {
return new BinaryNode<E>(x, null, null);
}
int compareResult = x.compareTo(tree.element);
if (compareResult < 0) {
tree.left= insert(x, tree.left);
} else if (compareResult > 0) {
tree.right = insert(x, tree.right);
} else {
//说明已经有这个值了。
System.out.println("已经有这个值了");
}
return tree;
}
/**
* 比较x和树的值
* 如果x小于树的值,在树的左子树中递归删除
* 如果x大于树的值,在树的右子树中递归删除
* 如果x等于树的值,那么这个值就是要删除的值。
* 因为删除一个值就要对树进行重新排列,所以这个位置上不能空。
* 如果这个树只有一个子树,那么就直接把这个子树放在这个位置上
* 如果这个树有两个子树,那么需要找到右子树的最小值,将这个最小值赋值在要删除的位置上,
* 然后递归调用从右子树中删除刚刚找到的这个最小值
*/
private BinaryNode<E> remove(E x, BinaryNode<E> tree) {
if (tree == null) {
//没有这个树
return tree;
}
int compareResult = x.compareTo(tree.element);
if (compareResult < 0) {
tree.left = remove(x, tree.left);
} else if (compareResult > 0) {
tree.right = remove(x, tree.right);
} else if (tree.left != null && tree.right != null) {
tree.element = findMin(tree.right).element;
tree.right = remove(tree.element, tree.right);
} else {
tree = (tree.left != null) ? tree.left : tree.right;
}
return tree;
}
private void printTree(BinaryNode<E> tree) {
if (tree == null) {
return;
}
System.out.print(tree.element+" ");
printTree(tree.left);
printTree(tree.right);
}
public static class BinaryNode<E> {
E element;
BinaryNode<E> left;
BinaryNode<E> right;
public BinaryNode(E element) {
this(element, null, null);
}
public BinaryNode(E element, BinaryNode<E> left, BinaryNode<E> right) {
this.element = element;
this.left = left;
this.right = right;
}
}
}实现的缺点
在代码中,注意remove方法中的一段代码:else if (tree.left != null && tree.right != null) {
tree.element = findMin(tree.right).element;
tree.right = remove(tree.element, tree.right);这里对删除的处理是,找到右子树中的最小值,把这个最小值放在当前节点上,然后从右子树中删除这个值。
而在insert的时候,是根据比较而随机的插入在左右子树上的。
所以如果交叉调用insert和remove很多次的话,这个二叉树会变得很不平衡,即左右子树的高度差很大。
这种平衡的二叉查找树叫平衡查找树。
一个最古老的平衡查找树是AVL树。
参考《数据结构与算法分析java版》

相关文章推荐