30分钟带你玩转正则表达式
2017-07-07 09:30
531 查看
30分钟带你玩转正则表达式
定义:
正则表达式说白了就是有普通字符、以及特殊字符组成的文子模式。{匹配模式标准}
正则表达式将会作为一个模板与所搜索的字符串进行匹配。可以让使用者轻易达到搜寻/删除/取代某些特定字符的处理程序。此外vim、grep、find、awk、sed等命令都支持正则表达式
注:在这里希望大家搞明白一件事,那就是通配符和正则表达式的区别与关系:
1、正则表达式是用来匹配字符串的,这个就不解释了
2、通配符是用来通配的,也就是shell在做Pathname Expansion时用到的
那么在什么情况下使用呢?
在什么地方使用通配符?答案是只要是shell命令行或者shell脚本中,你都可以使用通配符
在什么地方使用正则表达式?当你使用能够支持正则表达式的工具软件进行字符串处理时你就可以使用正则表达式
一、常用的正则表达式:
1)、 . 代表任意单个字符;如要查看某行中的put,可以使用p.t 文件名与之相互匹配。

2)、 ^号代表开始;如以T开头的行进行匹配.

3)、$代表行的结束;如以tty结束的行进行匹配:

4)、[...]匹配括号中的字符之一。但是只要有和方括号内的字符相同将会全部匹配:
如[tty] 匹配包含tty其中之一字符或者全部包括
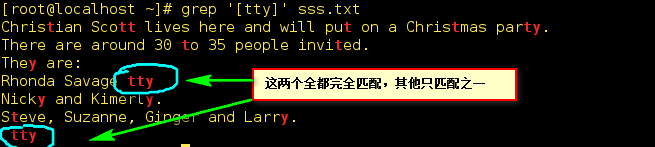
注:数字或者大小写字符和上面的都是相同的道理这里不在演示,有兴趣大家可以自己进行测试。
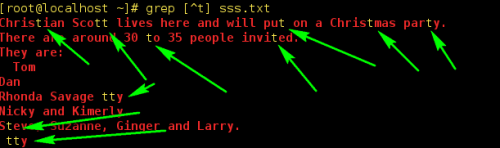
5)、[^xx]这个表示把某个字符或者数字排除在外的匹配,类似与取反的操作:
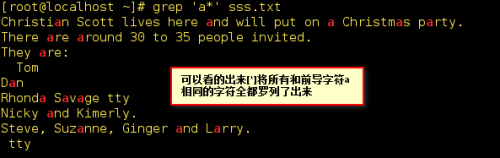
6)、 * 用于修饰前导字符,表示前导字符出现0次或任意多次,*代表所有和前导字符相同的字符。如:
7)、\?同样用于修饰前导字符,表示前导字符出现0次或者1次
8)、\+修饰前导字符,表示前导字符出现1次或者多次
这三种方式的使用方式基本一样,但就是前导字符出现的次数有所不同,上面已经标明了次数
9)、\{n,m\}同样用于修饰前导字符,但是在这里的n和m表示的是出现的次数,而不是个数,希望大家千万不要混淆。比如匹配连续2到4个a

注意了:在这里换可以使用其他的两种方式进行显示结果:
方式一:

方式二:

这里使用的三种方式进行显示,但是呢,都是进行了转译之后才可以的到想要的结果。egrep就属于转译,另外grep -E也是转译,最后a\{2,4\}也是转译,不管使用那种方式,都可以得到想要的结果,
\ 用于转义紧跟其后的单个特殊字符,使该特殊字符成为普通字符
在这里这个不做深入的研究。
另外还有其他的几种形式:
\{n\} 连续的n个前导字符
\{n,\} 连续的至少n个前导字符
不知道上面的大家伙有没有看明白,如果要是没有看明白的话这里将会为大家继续讲解一个综合的例子希望大家可以看的更加明白一些:
Christian Scott lives here and will put on a Christmas party.There are around 30 to 35 people invited. They are: TomDan Rhonda SavageNicky and Kimerly.Steve, Suzanne, Ginger and Larry.
搜索行以A至Z的一个字母开头,然后跟两个任意字母,然后跟一个换行符的行。将找到第5行。

搜索以一个大写字母开头,后跟0个或多个小写字母,再跟数字3,再跟0—5之间的一个数字。

搜索以0个或多个空格开头,跟一个大写字母,两个小写字母和一个换车符

将查找以0个或多个大写或小写字母开头,不跟逗号,然后跟0个或多个大写或小写字母,然后跟一个换车符。

二、grep命令的用法:
相信大家之前多多少少之前对grep都有过了解和使用,比如截取,再或者结合管道符、重定向符号进行使用,那么今天就让大家对grep有一个更深如层次的了解;
grep(全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来.
大家可以通过grep --help帮助来查看关于grep的更多参数命令,在这里就为大家介绍其中常用的几种:
-A NUM,--after-context=NUM 除了列出符合行之外,并且列出后NUM行。

-B NUM,--before-context=NUM 与 -A NUM 相对,但这此参数是显示除符合行之外并显示在它之前的NUM行

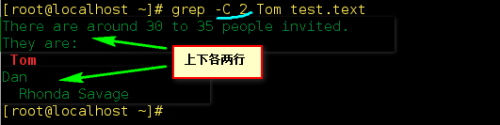
-C [NUM], -NUM, --context[=NUM] 列出符合行之外并列出上下各NUM行,默认值是2
-i,--ignore-case 忽略大小写差别
-n,--line-number 在匹配的行前面打印行号
-v,--revert-match 反检索,只显示不匹配的行
要用好grep这个工具,其实就是要写好正则表达式,所以这里不对grep的所有功能进行实例讲解,只列几个例子,讲解一个正则表达式的写法。
$ ls -l | grep '^d'
通过管道过滤ls -l输出的内容,只显示以d开头的行。

$grep '\.$' filename显示以.为结尾的所有行。

总结grep:
这几个参数不在进行演示了相信大家已经明白了grep的基本用法了,但是grep的参数选项可不止这一点点,如果想要掌握更多的参数,就要学会查看帮助--help再或者查看man手册
三、sed的用法:
sed是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。
注意:虽然sed把处理的内容发送到了屏幕之上,但是文件本身的内容却并没有改变,如果要想改变最简单的方法就是使用参数【-i】即可。另外也可以重定向到其他文件之下。
sed的基本命令:
1)、替换:s命令
这是最为常用的命令
比如:
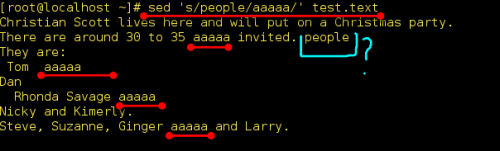
为啥有一个people没有被替换掉呢?
那是因为sed 's/people/aaaaa/g' test.text没有加g
2)用 & 表示匹配的字符串有时可能会想在匹配到的字符串周围或附近加上一些字符 .
如: sed 's/abc/(abc)/' filename
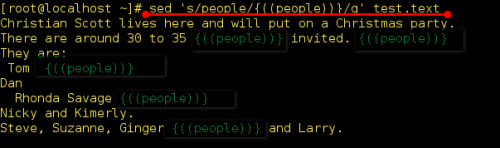
该例子在找到的 abc 前后加上括号 .
该例子还可以写成 sed 's/abc/(&)/' filename
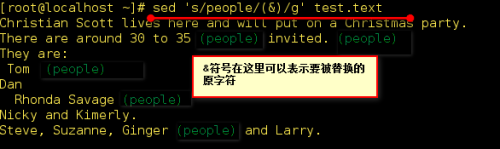
下面是更复杂的例子 :
取得eno16777736网卡IP地址:

3)、删除行:d命令
从某个文件当中删除包含关键字符的所有行:
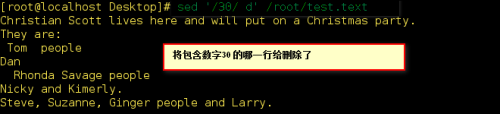
将/etc/passwd的内容显示并找印行号,同时将2~5删除

不知道大家对正则表达式有没有认识和了解,今天就为大家带来这些,另外这些东西是看不会的,要多实操才可以帮助大家加深印象和理解的。如果有什么地方需要和本人交流请留言。
下次为大家带来更加复杂的awk命令
定义:
正则表达式说白了就是有普通字符、以及特殊字符组成的文子模式。{匹配模式标准}
正则表达式将会作为一个模板与所搜索的字符串进行匹配。可以让使用者轻易达到搜寻/删除/取代某些特定字符的处理程序。此外vim、grep、find、awk、sed等命令都支持正则表达式
注:在这里希望大家搞明白一件事,那就是通配符和正则表达式的区别与关系:
1、正则表达式是用来匹配字符串的,这个就不解释了
2、通配符是用来通配的,也就是shell在做Pathname Expansion时用到的
那么在什么情况下使用呢?
在什么地方使用通配符?答案是只要是shell命令行或者shell脚本中,你都可以使用通配符
在什么地方使用正则表达式?当你使用能够支持正则表达式的工具软件进行字符串处理时你就可以使用正则表达式
一、常用的正则表达式:
1)、 . 代表任意单个字符;如要查看某行中的put,可以使用p.t 文件名与之相互匹配。
2)、 ^号代表开始;如以T开头的行进行匹配.
3)、$代表行的结束;如以tty结束的行进行匹配:
4)、[...]匹配括号中的字符之一。但是只要有和方括号内的字符相同将会全部匹配:
如[tty] 匹配包含tty其中之一字符或者全部包括
注:数字或者大小写字符和上面的都是相同的道理这里不在演示,有兴趣大家可以自己进行测试。
5)、[^xx]这个表示把某个字符或者数字排除在外的匹配,类似与取反的操作:
6)、 * 用于修饰前导字符,表示前导字符出现0次或任意多次,*代表所有和前导字符相同的字符。如:
7)、\?同样用于修饰前导字符,表示前导字符出现0次或者1次
8)、\+修饰前导字符,表示前导字符出现1次或者多次
这三种方式的使用方式基本一样,但就是前导字符出现的次数有所不同,上面已经标明了次数
9)、\{n,m\}同样用于修饰前导字符,但是在这里的n和m表示的是出现的次数,而不是个数,希望大家千万不要混淆。比如匹配连续2到4个a
注意了:在这里换可以使用其他的两种方式进行显示结果:
方式一:
方式二:
这里使用的三种方式进行显示,但是呢,都是进行了转译之后才可以的到想要的结果。egrep就属于转译,另外grep -E也是转译,最后a\{2,4\}也是转译,不管使用那种方式,都可以得到想要的结果,
\ 用于转义紧跟其后的单个特殊字符,使该特殊字符成为普通字符
在这里这个不做深入的研究。
另外还有其他的几种形式:
\{n\} 连续的n个前导字符
\{n,\} 连续的至少n个前导字符
不知道上面的大家伙有没有看明白,如果要是没有看明白的话这里将会为大家继续讲解一个综合的例子希望大家可以看的更加明白一些:
Christian Scott lives here and will put on a Christmas party.There are around 30 to 35 people invited. They are: TomDan Rhonda SavageNicky and Kimerly.Steve, Suzanne, Ginger and Larry.
搜索行以A至Z的一个字母开头,然后跟两个任意字母,然后跟一个换行符的行。将找到第5行。
搜索以一个大写字母开头,后跟0个或多个小写字母,再跟数字3,再跟0—5之间的一个数字。
搜索以0个或多个空格开头,跟一个大写字母,两个小写字母和一个换车符
将查找以0个或多个大写或小写字母开头,不跟逗号,然后跟0个或多个大写或小写字母,然后跟一个换车符。
二、grep命令的用法:
相信大家之前多多少少之前对grep都有过了解和使用,比如截取,再或者结合管道符、重定向符号进行使用,那么今天就让大家对grep有一个更深如层次的了解;
grep(全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来.
大家可以通过grep --help帮助来查看关于grep的更多参数命令,在这里就为大家介绍其中常用的几种:
-A NUM,--after-context=NUM 除了列出符合行之外,并且列出后NUM行。
-B NUM,--before-context=NUM 与 -A NUM 相对,但这此参数是显示除符合行之外并显示在它之前的NUM行
-C [NUM], -NUM, --context[=NUM] 列出符合行之外并列出上下各NUM行,默认值是2
-i,--ignore-case 忽略大小写差别
-n,--line-number 在匹配的行前面打印行号
-v,--revert-match 反检索,只显示不匹配的行
要用好grep这个工具,其实就是要写好正则表达式,所以这里不对grep的所有功能进行实例讲解,只列几个例子,讲解一个正则表达式的写法。
$ ls -l | grep '^d'
通过管道过滤ls -l输出的内容,只显示以d开头的行。
$grep '\.$' filename显示以.为结尾的所有行。
总结grep:
这几个参数不在进行演示了相信大家已经明白了grep的基本用法了,但是grep的参数选项可不止这一点点,如果想要掌握更多的参数,就要学会查看帮助--help再或者查看man手册
三、sed的用法:
sed是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。
注意:虽然sed把处理的内容发送到了屏幕之上,但是文件本身的内容却并没有改变,如果要想改变最简单的方法就是使用参数【-i】即可。另外也可以重定向到其他文件之下。
sed的基本命令:
1)、替换:s命令
这是最为常用的命令
比如:
为啥有一个people没有被替换掉呢?
那是因为sed 's/people/aaaaa/g' test.text没有加g
2)用 & 表示匹配的字符串有时可能会想在匹配到的字符串周围或附近加上一些字符 .
如: sed 's/abc/(abc)/' filename
该例子在找到的 abc 前后加上括号 .
该例子还可以写成 sed 's/abc/(&)/' filename
下面是更复杂的例子 :
取得eno16777736网卡IP地址:
3)、删除行:d命令
从某个文件当中删除包含关键字符的所有行:
将/etc/passwd的内容显示并找印行号,同时将2~5删除
不知道大家对正则表达式有没有认识和了解,今天就为大家带来这些,另外这些东西是看不会的,要多实操才可以帮助大家加深印象和理解的。如果有什么地方需要和本人交流请留言。
下次为大家带来更加复杂的awk命令

相关文章推荐
- 30分钟玩转Shell-shell printf命令
- 30分钟教你玩转SAMBA
- 30分钟玩转Blog定制
- 30分钟玩转Shell-Shell if else语句
- 正则表达式30分钟入门教程 (转)
- 30分钟玩转Blog定制 (转)
- 30分钟玩转Shell-Shell case esac语句
- 30分钟玩转Shell-Shell for循环
- 30分钟玩转Docker系列课程1---初识Docker
- 30分钟玩转Blog定制 (转)
- 30分钟玩转Shell-Shell while循环
- 30分钟玩转Markdown
- 30分钟玩转Docker系列课程2---Docker核心概念
- 30分钟玩转Blog定制 (转)
- 30分钟玩转Shell-Shell until循环
- 30分钟玩转Shell-Shell break和continue命令
- 30分钟玩转Shell-第一个Shell脚本
- 学习笔记之Linux Shell脚本教程:30分钟玩转Shell脚本编程
- 正则表达式教程:30分钟让你精通正则表达式语法
- “玩转”Java系列—正则表达式学习手册