机器学习笔记(1)---监督学习之梯度下降
2017-07-02 13:41
477 查看
前言
笔记主要内容
基本概念
线性回归
梯度下降法
正文部分公式推导
公式2推导
公式7推导
笔记都是按照本人的理解去写的,给出的数学基础知识也只是本人薄弱的地方,并不适合所有人。如有问题欢迎给我留言。
数学公式使用Letex编辑,原文博客http://blog.csdn.net/rosetta
监督学习(supervised learning)
回归问题 (regression problem)连续的
分类问题(classification problem) 离散的
无限维空间的问题,使用支持向量机(support vector)算法,可以把数据映射到无限维空间中。
学习理论
如何保证学习算法是有效的?训练数据集要达到多少才可以?
无监督学习(unsupervised learning)
给定一组数据,能发现这些数据的特点,能把相同特点的归类。也就是聚类(clustering)问题。
聚类可以做图像识别,可以使用一张照片建议3D场景,可以从杂吵声中提取出感兴趣的人的声音。
强化学习(Reinforcemnet Learning)
回报函数,
视频中举了个使用强化学习算法控制小型直升机的例子。做的好就奖励它,做的不好就惩罚它,但是如何去定义一个好的形为和坏的形为?
还可以用在网页爬取方面。
最后再提出一个关键问题,如何使用机器学习一个工具就解决实际问题?我想这也是我为什么选择去学机器学习的原因之一。
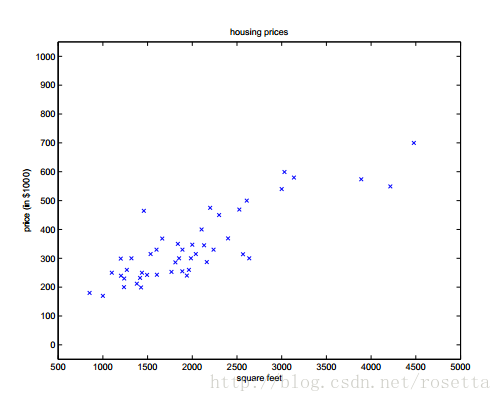
如下是房子面积和房价的关系。
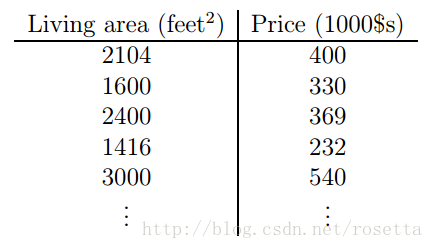
在坐标平面画出相应的点的:
使用x(i)x(i)表示输入,其中ii表示第几个样本,使用y(i)y(i)表示输出。{(x(i),y(i)),i=1,2,…,m}{(x(i),y(i)),i=1,2,…,m}表示训练集。或者使用XX表示输入数据空间,YY表示输出数据空间,本次例子中X=Y=RX=Y=R。
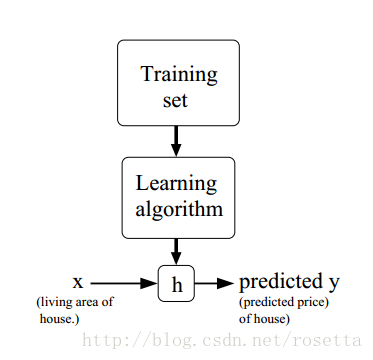
给定训练集,学习函数h:X↦Yh:X↦Y,h(x)h(x)为yy的预测函数,其处理过程如下图显示:
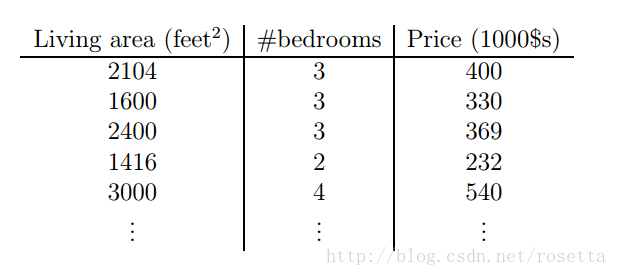
此时xx变成了二维的向量,x(i)1x1(i)表示面积,x(i)2x2(i)表示屋子数量,ii表示第ii条房子的数据.
为了完成监督学习(supervised learning),需要决定预测函数hh,可以给定一个关于xx的线性函数:hθ(x)=θ0+θ1x1+θ2x2(1)(1)hθ(x)=θ0+θ1x1+θ2x2
其中θiθi称为参数,或者权重,它用于确认从XX映射到YY的参数,得到合适的参数θθ是学习算法的任务。当不会发生混淆的时候可以把hθ(x)hθ(x)中的θθ去掉,简写成h(x)h(x)。为了简化符号,可令x0=1x0=1,这样公式就变成:h(x)=∑i=0mθixi=θTx(2)(2)h(x)=∑i=0mθixi=θTx
那么θθ如何确定呢?一种可行的方法是选择一组θθ和训练数据XX一起算出hθ(x)hθ(x)(此时由于xx是已知的,所以可以把hh看成是关于θθ的函数,一旦后续把θθ学到后,xx是将要预测的数据,那么那时hh就要看成是关于xx的函数),让hθ(x)hθ(x)尽可能的接近yy,那么如何描述这个接近呢?数学中描述接近常用的方法是求两者差的绝对值,课程中给出的公式稍稍有点不同。J(θ)=12∑i=1m(hθ(x(i))−y(i))2(3)(3)J(θ)=12∑i=1m(hθ(x(i))−y(i))2
其中的1212是为了后续的求导简便加上去的,此公式目前只有θθ是未知的,所以此时的任务就是去找一组θθ,使得J(θ)J(θ)最小,这样就学到了参数θθ,参数θθ定了以后,等要预测一套未在训练集中的房子数据时(即知道了x(i)x(i)的各项参数x1,x2x1,x2),我们就可以用上面的公式hθ(x)=θ0+θ1x1+θ2x2hθ(x)=θ0+θ1x1+θ2x2,求出hθ(x)hθ(x),这个hθ(x)hθ(x)即这套房子的价格。
下面的问题是如何求出θθ,能使得J(θ)J(θ)最小。这类问题称为无约束最优化问题。梯度下降法就是其中的一种方法。
θi:=θi−α∂∂θiJ(θ)(4)(4)θi:=θi−α∂∂θiJ(θ)
其中αα为学习速度,它决定每次迭代的步长,此值需要手动调整。ii表示某条数据的第ii个属性。
当只有一组训练数据时
∂∂θiJ(θ)===12∂∂θi(hθ(x)−y)212⋅2(hθ(x)−y)⋅∂∂θi(hθ(x)−y)(hθ(x)−y)⋅xi(5)(6)(7)(5)∂∂θiJ(θ)=12∂∂θi(hθ(x)−y)2(6)=12⋅2(hθ(x)−y)⋅∂∂θi(hθ(x)−y)(7)=(hθ(x)−y)⋅xi
带入44式得:θi:=θi−α(hθ(x)−y)⋅xi(8)(8)θi:=θi−α(hθ(x)−y)⋅xi
88式这表示一条数据的某个属性前的权重θθ求法。
当考虑mm组训练数据时:
θi:=θi−α∑j=0m(hθ(x(j))−y(j))⋅x(j)i(9)(9)θi:=θi−α∑j=0m(hθ(x(j))−y(j))⋅xi(j)
其中jj表示第几条数据,ii表示每条数据中的第几个属性。
运用此式迭代直到收敛,这就是批梯度下降(Batch Gradient Descent)算法。梯度下降法很容易被局部最小值影响,而我们要求得的全局最优解,也就是说应该收敛于全局最小值。由于此次函数J实际上是凸二次函数,它只有一个全局最小值(视频中展示像一个碗状的图),所以不需要考虑那么复杂。
以下是梯度下降的一个例子,它对二次函数求最小值。

这个椭圆是二次函数JJ函数的轮廓图(contours of a quadratic function),图中那条蓝线是梯度下降法生成的轨迹,它的初始值是(48,30)。图中的xx标记了梯度下降过程中所经过的θθ可用值。
用之前的训练集使用批梯度下降法来拟合θθ,把面积作为学习和预测房屋的价格的函数,学得θ0=71.27,θ1=0.1345θ0=71.27,θ1=0.1345。假如把hθ(x)hθ(x)看作是面积xx的函数,并使用房屋数据集,可得到如下图形:

假如把屋子数量也作为一个输入特征的话,可以学得θ0=89.60,θ1=0.1392,θ2=−8.738θ0=89.60,θ1=0.1392,θ2=−8.738。上述结果就是使用批梯度下降算法得到的。但是上面的算法每一次迭代都要使用所有mm个样本,如果样本成千上万甚至上亿,那么效率就很低。
下面使用随机梯度下降算法(或叫增量梯度下降法),算每个θ时不需要对所有的样本就和,其公式如下:

θTxθTx是向量表示方法,把向量展开成矩阵,则其表示的含义如下:θTx====⎧⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪θ0θ1⋮θi⎫⎭⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪T⎧⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪x0x1⋮xi⎫⎭⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⟮θ0,θ1,…,θi⟯⎧⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪x0x1⋮xi⎫⎭⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪θ0x0+θ1x1+⋯+θixi∑i=0mθixi(1)(2)(3)(4)(1)θTx=⟮θ0θ1⋮θi⟯T⟮x0x1⋮xi⟯(2)=⟮θ0,θ1,…,θi⟯⟮x0x1⋮xi⟯(3)=θ0x0+θ1x1+⋯+θixi(4)=∑i=0mθixi
所以∑i=0mθixi=θTx(2)(2)∑i=0mθixi=θTx
这里主要用到高等数学里的导数、偏导数和复合函数求导,
5到6式,主要是复合函数求偏导。
6到7式,主要是红色部分的计算,这里是对θiθi求偏导,偏导数和导数其实是类似的,只不过在多个自变量的情况下有一个偏向,当对其中一个变量做偏导时,其它变量看作常数即可。比如上述公式自变量有x,y,θx,y,θ三个,如果对θθ做偏导,那么把x,yx,y看成常量即可。
因为66式中的hθ(x)hθ(x)由公式11知hθ(x)=θ0+θ1x1+θ2x2hθ(x)=θ0+θ1x1+θ2x2,所以如果对θiθi做编导的话,只对θixiθixi做即可,其它不带θiθi的项看成常数,常数求导为00,所以求导结果就是xixi。
如有疑问之处欢迎加我微信交流,请备注“CSDN博客”

笔记主要内容
基本概念
线性回归
梯度下降法
正文部分公式推导
公式2推导
公式7推导
前言
本机器学习笔记是跟着原斯坦福大学吴恩达老师cs229课程学习后做的课后笔记。每次课程都会涉及到很多数学知识,我在记录课程核心内容的同时,会把数学基础知识在其它博文中单独记下,并在《机器学习笔记》系列博文中用到时给出链接。笔记都是按照本人的理解去写的,给出的数学基础知识也只是本人薄弱的地方,并不适合所有人。如有问题欢迎给我留言。
数学公式使用Letex编辑,原文博客http://blog.csdn.net/rosetta
笔记主要内容
本课程主要涉及四方面内容:监督学习、学习理论、无监督学习和强化学习,所以笔记主要也是记录这四块内容,当然还有相关的数学知识。监督学习(supervised learning)
回归问题 (regression problem)连续的
分类问题(classification problem) 离散的
无限维空间的问题,使用支持向量机(support vector)算法,可以把数据映射到无限维空间中。
学习理论
如何保证学习算法是有效的?训练数据集要达到多少才可以?
无监督学习(unsupervised learning)
给定一组数据,能发现这些数据的特点,能把相同特点的归类。也就是聚类(clustering)问题。
聚类可以做图像识别,可以使用一张照片建议3D场景,可以从杂吵声中提取出感兴趣的人的声音。
强化学习(Reinforcemnet Learning)
回报函数,
视频中举了个使用强化学习算法控制小型直升机的例子。做的好就奖励它,做的不好就惩罚它,但是如何去定义一个好的形为和坏的形为?
还可以用在网页爬取方面。
最后再提出一个关键问题,如何使用机器学习一个工具就解决实际问题?我想这也是我为什么选择去学机器学习的原因之一。
基本概念
一个关于房价的例子,目前是使用现有的数据来预测房子的价格,首先约定一些数学符号及其表示的含义。如下是房子面积和房价的关系。
在坐标平面画出相应的点的:
使用x(i)x(i)表示输入,其中ii表示第几个样本,使用y(i)y(i)表示输出。{(x(i),y(i)),i=1,2,…,m}{(x(i),y(i)),i=1,2,…,m}表示训练集。或者使用XX表示输入数据空间,YY表示输出数据空间,本次例子中X=Y=RX=Y=R。
给定训练集,学习函数h:X↦Yh:X↦Y,h(x)h(x)为yy的预测函数,其处理过程如下图显示:
线性回归
在本次课程中线性回归主要讲两种方法:梯度下降和正规方程。本篇笔记主要写梯度下降法,正规方程见下次笔记。梯度下降法
在刚才房子的例子上增加一个屋子数量的特征。此时xx变成了二维的向量,x(i)1x1(i)表示面积,x(i)2x2(i)表示屋子数量,ii表示第ii条房子的数据.
为了完成监督学习(supervised learning),需要决定预测函数hh,可以给定一个关于xx的线性函数:hθ(x)=θ0+θ1x1+θ2x2(1)(1)hθ(x)=θ0+θ1x1+θ2x2
其中θiθi称为参数,或者权重,它用于确认从XX映射到YY的参数,得到合适的参数θθ是学习算法的任务。当不会发生混淆的时候可以把hθ(x)hθ(x)中的θθ去掉,简写成h(x)h(x)。为了简化符号,可令x0=1x0=1,这样公式就变成:h(x)=∑i=0mθixi=θTx(2)(2)h(x)=∑i=0mθixi=θTx
那么θθ如何确定呢?一种可行的方法是选择一组θθ和训练数据XX一起算出hθ(x)hθ(x)(此时由于xx是已知的,所以可以把hh看成是关于θθ的函数,一旦后续把θθ学到后,xx是将要预测的数据,那么那时hh就要看成是关于xx的函数),让hθ(x)hθ(x)尽可能的接近yy,那么如何描述这个接近呢?数学中描述接近常用的方法是求两者差的绝对值,课程中给出的公式稍稍有点不同。J(θ)=12∑i=1m(hθ(x(i))−y(i))2(3)(3)J(θ)=12∑i=1m(hθ(x(i))−y(i))2
其中的1212是为了后续的求导简便加上去的,此公式目前只有θθ是未知的,所以此时的任务就是去找一组θθ,使得J(θ)J(θ)最小,这样就学到了参数θθ,参数θθ定了以后,等要预测一套未在训练集中的房子数据时(即知道了x(i)x(i)的各项参数x1,x2x1,x2),我们就可以用上面的公式hθ(x)=θ0+θ1x1+θ2x2hθ(x)=θ0+θ1x1+θ2x2,求出hθ(x)hθ(x),这个hθ(x)hθ(x)即这套房子的价格。
下面的问题是如何求出θθ,能使得J(θ)J(θ)最小。这类问题称为无约束最优化问题。梯度下降法就是其中的一种方法。
θi:=θi−α∂∂θiJ(θ)(4)(4)θi:=θi−α∂∂θiJ(θ)
其中αα为学习速度,它决定每次迭代的步长,此值需要手动调整。ii表示某条数据的第ii个属性。
当只有一组训练数据时
∂∂θiJ(θ)===12∂∂θi(hθ(x)−y)212⋅2(hθ(x)−y)⋅∂∂θi(hθ(x)−y)(hθ(x)−y)⋅xi(5)(6)(7)(5)∂∂θiJ(θ)=12∂∂θi(hθ(x)−y)2(6)=12⋅2(hθ(x)−y)⋅∂∂θi(hθ(x)−y)(7)=(hθ(x)−y)⋅xi
带入44式得:θi:=θi−α(hθ(x)−y)⋅xi(8)(8)θi:=θi−α(hθ(x)−y)⋅xi
88式这表示一条数据的某个属性前的权重θθ求法。
当考虑mm组训练数据时:
θi:=θi−α∑j=0m(hθ(x(j))−y(j))⋅x(j)i(9)(9)θi:=θi−α∑j=0m(hθ(x(j))−y(j))⋅xi(j)
其中jj表示第几条数据,ii表示每条数据中的第几个属性。
运用此式迭代直到收敛,这就是批梯度下降(Batch Gradient Descent)算法。梯度下降法很容易被局部最小值影响,而我们要求得的全局最优解,也就是说应该收敛于全局最小值。由于此次函数J实际上是凸二次函数,它只有一个全局最小值(视频中展示像一个碗状的图),所以不需要考虑那么复杂。
以下是梯度下降的一个例子,它对二次函数求最小值。
这个椭圆是二次函数JJ函数的轮廓图(contours of a quadratic function),图中那条蓝线是梯度下降法生成的轨迹,它的初始值是(48,30)。图中的xx标记了梯度下降过程中所经过的θθ可用值。
用之前的训练集使用批梯度下降法来拟合θθ,把面积作为学习和预测房屋的价格的函数,学得θ0=71.27,θ1=0.1345θ0=71.27,θ1=0.1345。假如把hθ(x)hθ(x)看作是面积xx的函数,并使用房屋数据集,可得到如下图形:
假如把屋子数量也作为一个输入特征的话,可以学得θ0=89.60,θ1=0.1392,θ2=−8.738θ0=89.60,θ1=0.1392,θ2=−8.738。上述结果就是使用批梯度下降算法得到的。但是上面的算法每一次迭代都要使用所有mm个样本,如果样本成千上万甚至上亿,那么效率就很低。
下面使用随机梯度下降算法(或叫增量梯度下降法),算每个θ时不需要对所有的样本就和,其公式如下:
正文部分公式推导
公式2推导
∑i=0mθixi=θ0x0+θ1x1+⋯+θixi∑i=0mθixi=θ0x0+θ1x1+⋯+θixiθTxθTx是向量表示方法,把向量展开成矩阵,则其表示的含义如下:θTx====⎧⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪θ0θ1⋮θi⎫⎭⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪T⎧⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪x0x1⋮xi⎫⎭⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⟮θ0,θ1,…,θi⟯⎧⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪x0x1⋮xi⎫⎭⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪θ0x0+θ1x1+⋯+θixi∑i=0mθixi(1)(2)(3)(4)(1)θTx=⟮θ0θ1⋮θi⟯T⟮x0x1⋮xi⟯(2)=⟮θ0,θ1,…,θi⟯⟮x0x1⋮xi⟯(3)=θ0x0+θ1x1+⋯+θixi(4)=∑i=0mθixi
所以∑i=0mθixi=θTx(2)(2)∑i=0mθixi=θTx
公式7推导
∂∂θiJ(θ)===12∂∂θi(hθ(x)−y)212⋅2(hθ(x)−y)⋅∂∂θi(hθ(x)−y)(hθ(x)−y)⋅xi(5)(6)(7)(5)∂∂θiJ(θ)=12∂∂θi(hθ(x)−y)2(6)=12⋅2(hθ(x)−y)⋅∂∂θi(hθ(x)−y)(7)=(hθ(x)−y)⋅xi这里主要用到高等数学里的导数、偏导数和复合函数求导,
5到6式,主要是复合函数求偏导。
6到7式,主要是红色部分的计算,这里是对θiθi求偏导,偏导数和导数其实是类似的,只不过在多个自变量的情况下有一个偏向,当对其中一个变量做偏导时,其它变量看作常数即可。比如上述公式自变量有x,y,θx,y,θ三个,如果对θθ做偏导,那么把x,yx,y看成常量即可。
因为66式中的hθ(x)hθ(x)由公式11知hθ(x)=θ0+θ1x1+θ2x2hθ(x)=θ0+θ1x1+θ2x2,所以如果对θiθi做编导的话,只对θixiθixi做即可,其它不带θiθi的项看成常数,常数求导为00,所以求导结果就是xixi。
如有疑问之处欢迎加我微信交流,请备注“CSDN博客”

相关文章推荐
- 【斯坦福---机器学习】复习笔记之监督学习应用.梯度下降
- 机器学习笔记二:监督学习应用:梯度下降
- 【机器学习-斯坦福】学习笔记2 - 监督学习应用与梯度下降
- 【机器学习-斯坦福】学习笔记2 - 监督学习应用与梯度下降
- 机器学习-斯坦福:学习笔记2-监督学习应用与梯度下降
- Andrew Ng 机器学习 第一课 监督学习应用.梯度下降 笔记
- [笔记]监督学习·梯度下降
- 机器学习第一篇(stanford大学公开课学习笔记) —机器学习的概念和梯度下降
- 【机器学习】1 监督学习应用与梯度下降
- [机器学习]监督学习应用.梯度下降
- 机器学习--监督学习应用(梯度下降)
- 【学习笔记】斯坦福大学公开课(机器学习) 之一:线性回归、梯度下降
- 斯坦福大学机器学习笔记(3)--梯度下降及学习速度
- 斯坦福大学公开课 :机器学习课程笔记-[第2集] 监督学习应用.梯度下降
- 监督学习之梯度下降——Andrew Ng机器学习笔记(一)
- Stanford机器学习---第一周.监督学习与梯度下降
- Ng深度学习笔记 1-线性回归、监督学习、成本函数、梯度下降
- 机器学习--监督学习应用(梯度下降)
- 斯坦福大学公开课机器学习课程(Andrew Ng)二监督学习应用 梯度下降
- 机器学习深度学习基础笔记(2)——梯度下降之手写数字识别算法实现