java 效率极高的查询数据结构——SkipList 跳表
2017-07-01 11:21
246 查看
前一阵子和朋友聊天,他和我讲在面试中被问到跳表。当时我也很迷从来没听说过跳表,赶快学习了一下,学习了之后才发现这个数据结构不是很难,而且效率非常高,在平均情况下查找的时间复杂度约为O(log n)堪比平衡树。而且具体的数据结构的实现也非常有趣。
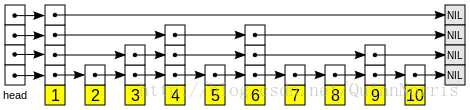
(图片来源于维基百科,图中未表示出指向head最顶层元素的起始结点)
每层中出现的元素都是以常数概率随机存在的,如果当前层出现了该元素,根据”每一层存在的元素都是前一层的存在元素的子集”的特点,该层的前几层都具有该元素,而且每个元素都会维护一个指向下一层该元素的指针。在整个跳跃列表的最高层的头结点处有一个起始指针,当我们要查询某个值时,从起始指针出发,由最高层开始向前查找,如果判断下一个元素大于查找元素则通过当前元素指向下一层的指针进入下一层再向前进行查找。如此往复直到查找到我们需要的元素为止。
由多条链表组成多个层组成,层数以log2N层为宜
第一层包含全部元素
如果元素x最高存在于y层,则y层以下所有层均包含x
每层元素都有一个指向下一层拥有相同值的元素的指针
在每层中都需要包含头结点和尾结点
起始结点指向最高层头结点
在计算时间复杂度之前首先我们要预估出跳表的层数期望,这可能需要一些数学计算,但并不会很复杂。
先设跳表最高层为h层,最底层为第0层,每一层的元素在上一层出现的概率是固定常数p。
在每层出现的元素个数的期望是:Em=ph·N
则:h=logp(Em/N)
即,当Em=1表示跳表最高层时:h=log(1/p)N
所以,跳表的层数期望是O(logN)
时间复杂度——O(logN)
在得出跳表的层数期望后很容易得到时间复杂度也是O(logN)。和平衡树的原理相同,如果我们构建p=1/2的跳表,假设他的布局和二叉树的布局类似如图:

那么他的时间复杂度是O(log2N),同理当概率为p的时候时间复杂度为O(log(1/p)N)。这种时间复杂度是带有随机性的,在平均情况下如此为O(logN)。同理可证,跳表插入、删除、修改的时间复杂度均为O(logN),如果难以证明,可以先将跳表化成类似上图的”二叉树”类型再进行证明。
空间复杂度——O(N)
空间复杂度考虑所有层数上结点相加个数的总和。
每层出现的元素个数的期望是:Em=ph·N
所有层出现元素个数和:Nsum=Em0+Em1+ … + Emh
则,Nsum=p0·N+p1·N+ … +ph·N
则,Nsum=N(p0+p1+ … +ph)
因为固定概率p为常数,所以(p0+p1+ … +ph)也为某常数psum
所以,Nsum=N·psum
因此跳表的空间复杂度为O(N)
抽象的来说,我们可以把二叉平衡树看作是p=1/2的跳表(只是简单的对比,实际上这两种数据结构有很大差异)。相对于跳跃列表而言,我们可以自己规定p的值,选择更加稀疏或是稠密的查找方式,在我们需要查找的数据量不同时,这更具有灵活性。
2.跳跃列表是有序的链表
有的时候堆排序和二叉树之所以不被使用不是因为效率的问题,而是因为这种数据结构很难利用计算机缓存特点,而且这类数据结构没有一个真正意义上的有序的表。我们知道大部分数据库的实现都是采用B+树,B+树优于B树的其中一个原因就是B+树在叶节点拥有串联起来的一份有序的链表。在很多情况下这也是跳表被更多使用的一个原因。
3.跳跃列表比平衡树更容易实现
大部分二叉平衡树的插入删除很难以实现,而且每次插入删除都要做大量的旋转平衡。相比较于二叉平衡树复杂的实现代码,跳跃列表则更加简单,因为概率本来是随机性的值,我们为某个新加入的值设置最高层的时候顾虑要小得多。
SkipList 跳跃列表原理
跳跃列表是一种由多条链表组合而成的允许快速查询有序元素的数据结构。跳跃列表中的每条链表表示一个层,每一层存在的元素都是前一层(前一层是下方的层,从低至高生成跳跃列表)的存在元素的子集,在列表的头和尾有存在于每个层上的起始点和结束点,作为每层链表的头结点和尾结点。(图片来源于维基百科,图中未表示出指向head最顶层元素的起始结点)
每层中出现的元素都是以常数概率随机存在的,如果当前层出现了该元素,根据”每一层存在的元素都是前一层的存在元素的子集”的特点,该层的前几层都具有该元素,而且每个元素都会维护一个指向下一层该元素的指针。在整个跳跃列表的最高层的头结点处有一个起始指针,当我们要查询某个值时,从起始指针出发,由最高层开始向前查找,如果判断下一个元素大于查找元素则通过当前元素指向下一层的指针进入下一层再向前进行查找。如此往复直到查找到我们需要的元素为止。
定义跳表的满足条件
一个正确的跳表应该符合下面的所有条件:由多条链表组成多个层组成,层数以log2N层为宜
第一层包含全部元素
如果元素x最高存在于y层,则y层以下所有层均包含x
每层元素都有一个指向下一层拥有相同值的元素的指针
在每层中都需要包含头结点和尾结点
起始结点指向最高层头结点
时间复杂度&空间复杂度
跳表层数期望——O(logN)在计算时间复杂度之前首先我们要预估出跳表的层数期望,这可能需要一些数学计算,但并不会很复杂。
先设跳表最高层为h层,最底层为第0层,每一层的元素在上一层出现的概率是固定常数p。
在每层出现的元素个数的期望是:Em=ph·N
则:h=logp(Em/N)
即,当Em=1表示跳表最高层时:h=log(1/p)N
所以,跳表的层数期望是O(logN)
时间复杂度——O(logN)
在得出跳表的层数期望后很容易得到时间复杂度也是O(logN)。和平衡树的原理相同,如果我们构建p=1/2的跳表,假设他的布局和二叉树的布局类似如图:
那么他的时间复杂度是O(log2N),同理当概率为p的时候时间复杂度为O(log(1/p)N)。这种时间复杂度是带有随机性的,在平均情况下如此为O(logN)。同理可证,跳表插入、删除、修改的时间复杂度均为O(logN),如果难以证明,可以先将跳表化成类似上图的”二叉树”类型再进行证明。
空间复杂度——O(N)
空间复杂度考虑所有层数上结点相加个数的总和。
每层出现的元素个数的期望是:Em=ph·N
所有层出现元素个数和:Nsum=Em0+Em1+ … + Emh
则,Nsum=p0·N+p1·N+ … +ph·N
则,Nsum=N(p0+p1+ … +ph)
因为固定概率p为常数,所以(p0+p1+ … +ph)也为某常数psum
所以,Nsum=N·psum
因此跳表的空间复杂度为O(N)
相比二叉平衡树跳表的优势
1.跳跃列表的固定概率p由你定义抽象的来说,我们可以把二叉平衡树看作是p=1/2的跳表(只是简单的对比,实际上这两种数据结构有很大差异)。相对于跳跃列表而言,我们可以自己规定p的值,选择更加稀疏或是稠密的查找方式,在我们需要查找的数据量不同时,这更具有灵活性。
2.跳跃列表是有序的链表
有的时候堆排序和二叉树之所以不被使用不是因为效率的问题,而是因为这种数据结构很难利用计算机缓存特点,而且这类数据结构没有一个真正意义上的有序的表。我们知道大部分数据库的实现都是采用B+树,B+树优于B树的其中一个原因就是B+树在叶节点拥有串联起来的一份有序的链表。在很多情况下这也是跳表被更多使用的一个原因。
3.跳跃列表比平衡树更容易实现
大部分二叉平衡树的插入删除很难以实现,而且每次插入删除都要做大量的旋转平衡。相比较于二叉平衡树复杂的实现代码,跳跃列表则更加简单,因为概率本来是随机性的值,我们为某个新加入的值设置最高层的时候顾虑要小得多。

相关文章推荐
- 在一个千万级的数据库查寻中,如何提高查询效率?分别说出在数据库设计、SQL语句、java等层面的解决方案。
- 一步步学习数据结构和算法之折半插入排序效率分析及java实现
- 在一个千万级的数据库查寻中,如何提高查询效率?分别说出在数据库设计、SQL语句、java等层面的解决方案
- 一步步学习数据结构和算法之快速排序效率分析及java实现
- 一步步学习数据结构和算法之冒泡排序效率分析及java实现
- 一步步学习数据结构和算法之选择排序效率分析及java实现
- 在一个千万级的数据库查寻中,如何提高查询效率?分别说出在数据库设计、SQL语句、java等层面的解决方案。【转】
- 一步步学习数据结构和算法之希尔排序效率分析及java实现
- Java数据结构之LinkedList、ArrayList的效率分析
- 一步步学习数据结构和算法之归并排序效率分析及java实现
- Java数据结构之LinkedList、ArrayList的效率分析
- 在一个千万级的数据库查寻中,如何提高查询效率?分别说出在数据库设计、SQL语句、java等层面的解决方案。
- java hashMap 查询效率非常高,看一下根据key找value,根据value找key
- Java 归纳总结 -- 提高SQL查询效率的30种方法
- 一步步学习数据结构和算法之快速排序效率分析及java实现
- 这两个类是java中进行key-value存储、查询的常用类,如果我们学习过哈希算法就会知道key-value查询的效率依赖于如何存储,换句话说,如果存的好,拿出来就容易,存的不好,拿出来就不方便。两
- 一步步学习数据结构和算法之直接插入排序效率分析及java实现
- 一步步学习数据结构和算法之堆排序效率分析及java实现
- 这两个类是java中进行key-value存储、查询的常用类,如果我们学习过哈希算法就会知道key-value查询的效率依赖于如何存储,换句话说,如果存的好,拿出来就容易,存的不好,拿出来就不方便。两
- 参数绑定导致java执行查询sql效率低