编译原理 - 词法分析器
2017-06-29 22:08
477 查看
题目
提供一个包含源代码的source.txt,其内容如下:/example/
b=1\
00
101:a=2*(1+3)
IF ( b > 10 ) THEN a=1
ELSE IF(b>=5) THEN
a=2
ELSE
GOTO 101
要求先将源代码进行预处理,把预处理的结果保存在”预处理.txt”中,然后判断其中的
K:关键字
I:标识符
O:操作符
P:界符
L:标量
C:常数
并且将结果保存在”二元式表.txt”中
思路
一、 观察source.txt如下
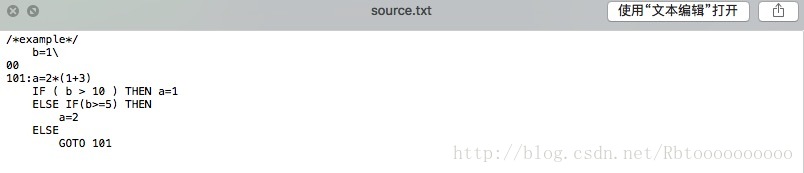
二、进行预处理,
预处理第一步:使整个source.txt内容变成一个字符串,同时去掉连接符符"\"和多多余的空格
预处理第二部:去掉注释得到如下的字符串

三、对”>”, “<”, “<=”, “>=”, “=”, “<>”, “+”, “-“, “*”, “/”:这些符号的两边加空格得到如下内容,以方便后续操作

四、使用split函数,将这个函数的参数设置为空格" "
,得到如下内容
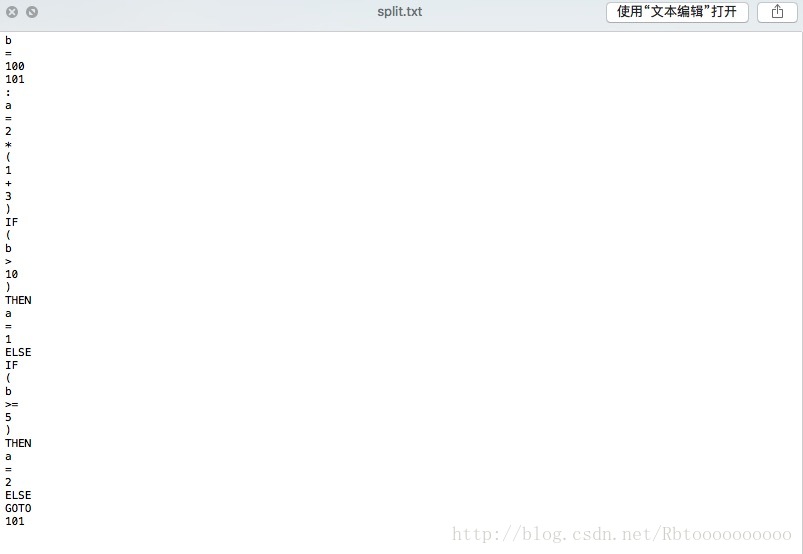
五、判断上图每个字符串的属性——是关键字还是标识符还是巴拉巴拉的(你懂得��),并且将结果输出来,得到如下内容

代码
package 编译原理实验一;
import java.util.Scanner;
import java.io.*;
/**
* Created by luopu on 2017/5/20.
*/
public class A {
static String filePath=new String("");
static String fileContent=new String("");
static String original_str=new String("");
static String[] k_word={"IF", "ELSE", "THEN", "GOTO"};
static String[] c_word={"0", "1", "2", "3", "4", "5", "6", "7", "8", "9"};
static String[] o_word={">", "<", "<=", ">=", "=", "<>", "+", "-", "*", "/"};
static String[] p_word={"(", ")", "{", "}", ";", ":"};
private static Scanner sc=new Scanner(System.in);
public static void main(String args[]) {
System.out.print("请输入文件路径: ");
filePath=sc.next();
readTextFile(filePath); // 读取txt内容,并且预处理第一步:删除连接符和换行符
String pre_str=pretreat(original_str); // 预处理第二步
writeFile(pre_str, "预处理.txt");
String space_str=addSpace(pre_str).replaceAll(" ", " "); // 添加空格 并且把双空格变成单空格
space_str=space_str.trim(); // 去掉首尾空格
writeFile(space_str, "空格串.txt");
String[] str=space_str.split(" "); // 根据空格划分字符串
String[] kind=new String[str.length]; // 储存每个字符串的属性
for (int i = 0; i < str.length; i++) {
kind[i]=panduan(str[i]);
if(str[i].equals(":")) { // 对标量进行判断
kind[i-1]="L";
}
if(str[i].equals("GOTO")) { // 对标量进行判断
kind[i+1]="L";
i++;
}
}
for (int i = 0; i < str.length; i++) {
fileContent=fileContent+"["+kind[i]+", "+str[i]+"]"+"\n";
}
writeFile(fileContent, "二元式表.txt");
fileContent="";
for (int i = 0; i < str.length; i++) {
fileContent=fileContent+str[i]+"\n";
}
writeFile(fileContent, "split.txt");
}
public static void readTextFile(String filePath){ // 读取txt文本内容,保存至original_str
try {
String encoding="GBK";
File file=new File(filePath);
if(file.isFile() && file.exists()){ //判断文件是否存在
InputStreamReader read = new InputStreamReader(
new FileInputStream(file),encoding);//考虑到编码格式
BufferedReader bufferedReader = new BufferedReader(read);
String fileText=new String();
while((fileText = bufferedReader.readLine()) != null){ //预处理第一步:去掉分隔符和回车
if(fileText.charAt(fileText.length()-1)!='\\') {
original_str=original_str+fileText.trim()+" ";
} else {
original_str=original_str+((fileText.substring(0, fileText.indexOf('\\'))).trim());
}
}
read.close();
} else {
System.out.println("找不到指定的文件");
}
} catch (Exception e) {
System.out.println("读取文件内容出错");
e.printStackTrace();
}
}
public static String pretreat(String str) {// 预处理
StringBuffer pre_str;
StringBuffer sb_str = new StringBuffer(); //预处理第二步:删除注释
sb_str.append(str);
int begin=str.indexOf("/*");
int end=str.indexOf("*/")+2;
pre_str=sb_str.delete(begin, end);
return pre_str.toString().trim();
}
public static String addSpace(String str) { // 添加空格
StringBuffer sb=new StringBuffer(); // 便于使用insert函数
sb.append(str);
for(int i=0; i<sb.length(); i++) {
if(isIn(sb.charAt(i))) {
sb.insert(i++, ' ');
i++;
if((sb.charAt(i-1)=='<'||sb.charAt(i-1)=='>')&& // 对"<=",">=","<>"进行特殊处理
sb.charAt(i)=='='||sb.charAt(i)=='>') {
sb.insert(++i, ' ');
} else {
sb.insert(i, ' ');
}
}
}
return sb.toString();
}
public static boolean isIn(char c) { // 判断是否添加空格
char[] words={'(', ')', '{', '}', ';', '=', '>', '<', ':', '+', '-', '*', '/'};
for(int i=0; i<words.length; i++) {
if(c==words[i]) {
return true;
}
}
return false;
}
public static String panduan(String str) { // 判断字符串的属性 但不包括对标量的判断
for(int i=0; i<k_word.length; i++) {
if(str.equals(k_word[i])) {
return "K";
}
}
for(int i=0; i<o_word.length; i++) {
if(str.equals(o_word[i])) {
return "O";
}
}
for(int i=0; i<p_word.length; i++) {
if(str.equals(p_word[i])) {
return "P";
}
}
for(int i=0; i<c_word.length; i++) {
if((str.substring(0, 1)).equals(c_word[i])) {
return "C";
}
}
return "I";
}
public static void writeFile(String content, String fileName) { // 将内容写入txt文件
FileOutputStream fop = null;
File file;
try {
file = new File(fileName);
fop = new FileOutputStream(file, false);
if (!file.exists()) {
file.createNewFile();
}
byte[] contentInBytes = content.getBytes();
fop.write(contentInBytes);
fop.flush();
fop.close();
System.out.println("Done");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fop != null) {
fop.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}对java不熟悉,有什么做的不好的地方,欢迎指正,也欢迎搭讪( ̄▽ ̄)~*,联系方式戳此
学习使我进步,学习使我快乐,我热爱学习:)


相关文章推荐
- [编译原理]词法分析器JLEX使用指南 (Jdk1.5.0 + JLex 1.2.6)
- [编译原理]词法分析器JLEX使用指南 (Jdk1.5.0 + JLex 1.2.6)
- 编译原理上机程序 之 词法分析器
- 编译原理(一)词法分析器
- 【编译原理】:简易的词法分析器
- [编译原理]词法分析器的分析与实现
- 编译原理——词法分析器
- 编译原理手记04-通过状态图设计词法分析器
- 编译原理:第七节 及词法分析器的C++和Python实现
- 编译原理-&gt;词法分析器的分析
- 编译原理—词法分析器
- C++实现编译原理的词法分析器
- 【编译原理】词法分析器
- 词法分析器-2-编译原理
- C#写的一个词法分析器(编译原理)
- [编译原理课程设计] 程序示例一、词法分析器
- 深入浅出编译原理-3-词法分析器
- 编译原理__词法分析器
- 编译原理课程设计之词法分析器
- 编译原理----词法分析器实现(C)