使用batch-import工具向neo4j中导入海量数据
2017-06-25 09:30
183 查看
在开发neo4j的过程中,经常会有同学问如何向neo4j中导入大量的历史数据,而这些数据一般都会存在于关系型数据库中,现在本人就根据自己的导入经历,把导入的过程和一些挖过的坑分享给大家,以便后面的同学少走弯路,废话不多说,直接上干货。
1、batch-import原始项目地址:https://github.com/jexp/batch-import
这个工具是neo4j的作者之一Michael Hunger所编写,是在neo4j自带批量导入工具基础之上做的进一步优化,但是它在导入.gz压缩文件时,会出现关系无法导入的情况,所以如果要使用.gz压缩包进行导入,请使用我修改过的版本:https://github.com/mo9527/batch-import
2、环境准备
jdk:7以上
内存:8G以上,导入数据多的话会非常消耗内存,我自己导入的是将近1.5亿节点,3亿关系,用的是32G内存
3、导入步骤
a)从github上clone下代码,并使用maven进行打包,打完包后的jar文件,与项目本身的依赖jar一起放到lib文件夹下,batch.properties文件和执行导入的脚本放在lib同级目录下,最后的目录结构如下图:
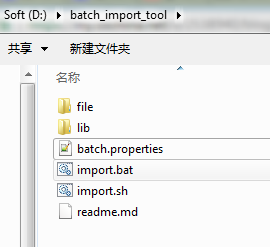
ps:file文件夹是我自己将要导入的csv文件和.gz压缩包。
b)组装csv文件
说起这一步,可能需要你们根据自己的实际业务需求,手动写代码导csv文件了,这里我只讲一下csv文件格式一些要点:
1、节点csv文件
节点csv文件的第一列是固定的,列值为此节点的label名称,第二列是index,它的列头是id:string:indexName 这种格式,解释一下,id是这一列的property名字,可以根据需要自己命名,string为字段的数据类型,indexName是neo4j数据库中将要导入的索引名称,我自己的文件格式如下:
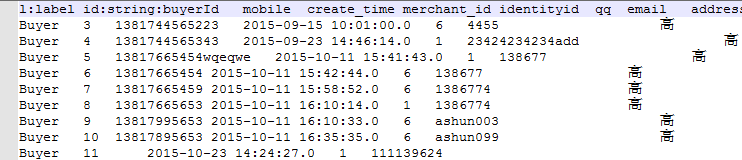
然后,后面的列就是节点的property了,没什么特别的要求
2、关系csv文件
先看下我的关系csv文件:
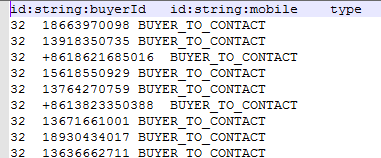
关系的csv文件前两列要特别注意,第一列是关系的起始节点,第二列是关系的结束节点,第三列是关系类型,后面的列是关系的property,可以随意了。他github上的说明没有说出一些注意点,这里要特别标明:
第一列的起始节点的列头,也就是id:string:buyerId这个东西,这个玩意一定要和节点csv文件(上图)中定义的一模一样,第二列也是如此,要和结束节点的csv文件里的一样,不然他会找不到对应的关系。
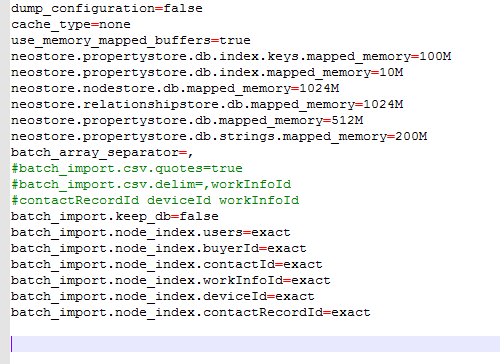
3、修改batch.properties文件
主要修改两个地方,1、如果是在现有的neo4j数据库中进行导入,请设置:
batch_import.keep_db=true
2、将节点csv文件中所有的索引名称加入到文件中,例如上面这个节点csv文件中的索引名称是buyerId,那就在文件中加入batch_import.node_index.buyerId=exact
以下是我本人的配置文件:
3、导入
linux和win环境的导入都差不多,只不过执行的脚本不一样,这里以win环境为例。
文件都准备好了,现在开始导入了。
打开cmd,cd到导入脚本的目录,也就是import.bat所在目录,执行命令:
import.bat test.db node.csv rel.csv
解释一下命令的几个参数:第一个参数是数据库的目录,可以绝对路径指定到任意位置,第二个参数是节点csv文件,多个csv文件用逗号分隔,如果是压缩包,一定要注意,这里有个坑,不能把所有类型的node都放到一个压缩包中,一定要每个类型的node分开压缩,不然它只会导入第一个类型的node节点,同理,关系的压缩包也要分开压缩,然后导入时用逗号分隔.gz文件。
好了,如果你的csv文件没有问题,内存足够用的话,现在就开始等待吧。
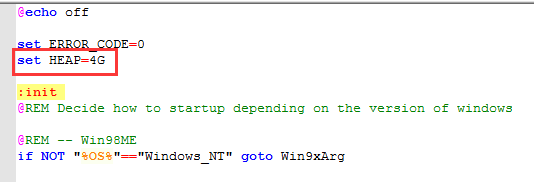
如果想修改导入工具的Heap大小,可以修改脚本文件中的 set HEAP=4G
如果不能正常编译jar包,可使用我已经编译好的工具:
https://github.com/mo9527/batch-import-tool
温馨提示:如果节点文件中有中文的话,win环境csv文件很有可能出现乱码,然后就导致换行出现问题,导入程序就会出现假死的状态,表现为程序一直在吃内存,可是一直导不进去数据,这时候可以用本人改动过的版本去导入,具体改动可见我github上的记录
1、batch-import原始项目地址:https://github.com/jexp/batch-import
这个工具是neo4j的作者之一Michael Hunger所编写,是在neo4j自带批量导入工具基础之上做的进一步优化,但是它在导入.gz压缩文件时,会出现关系无法导入的情况,所以如果要使用.gz压缩包进行导入,请使用我修改过的版本:https://github.com/mo9527/batch-import
2、环境准备
jdk:7以上
内存:8G以上,导入数据多的话会非常消耗内存,我自己导入的是将近1.5亿节点,3亿关系,用的是32G内存
3、导入步骤
a)从github上clone下代码,并使用maven进行打包,打完包后的jar文件,与项目本身的依赖jar一起放到lib文件夹下,batch.properties文件和执行导入的脚本放在lib同级目录下,最后的目录结构如下图:
ps:file文件夹是我自己将要导入的csv文件和.gz压缩包。
b)组装csv文件
说起这一步,可能需要你们根据自己的实际业务需求,手动写代码导csv文件了,这里我只讲一下csv文件格式一些要点:
1、节点csv文件
节点csv文件的第一列是固定的,列值为此节点的label名称,第二列是index,它的列头是id:string:indexName 这种格式,解释一下,id是这一列的property名字,可以根据需要自己命名,string为字段的数据类型,indexName是neo4j数据库中将要导入的索引名称,我自己的文件格式如下:
然后,后面的列就是节点的property了,没什么特别的要求
2、关系csv文件
先看下我的关系csv文件:
关系的csv文件前两列要特别注意,第一列是关系的起始节点,第二列是关系的结束节点,第三列是关系类型,后面的列是关系的property,可以随意了。他github上的说明没有说出一些注意点,这里要特别标明:
第一列的起始节点的列头,也就是id:string:buyerId这个东西,这个玩意一定要和节点csv文件(上图)中定义的一模一样,第二列也是如此,要和结束节点的csv文件里的一样,不然他会找不到对应的关系。
3、修改batch.properties文件
主要修改两个地方,1、如果是在现有的neo4j数据库中进行导入,请设置:
batch_import.keep_db=true
2、将节点csv文件中所有的索引名称加入到文件中,例如上面这个节点csv文件中的索引名称是buyerId,那就在文件中加入batch_import.node_index.buyerId=exact
以下是我本人的配置文件:
3、导入
linux和win环境的导入都差不多,只不过执行的脚本不一样,这里以win环境为例。
文件都准备好了,现在开始导入了。
打开cmd,cd到导入脚本的目录,也就是import.bat所在目录,执行命令:
import.bat test.db node.csv rel.csv
解释一下命令的几个参数:第一个参数是数据库的目录,可以绝对路径指定到任意位置,第二个参数是节点csv文件,多个csv文件用逗号分隔,如果是压缩包,一定要注意,这里有个坑,不能把所有类型的node都放到一个压缩包中,一定要每个类型的node分开压缩,不然它只会导入第一个类型的node节点,同理,关系的压缩包也要分开压缩,然后导入时用逗号分隔.gz文件。
好了,如果你的csv文件没有问题,内存足够用的话,现在就开始等待吧。
如果想修改导入工具的Heap大小,可以修改脚本文件中的 set HEAP=4G
如果不能正常编译jar包,可使用我已经编译好的工具:
https://github.com/mo9527/batch-import-tool
温馨提示:如果节点文件中有中文的话,win环境csv文件很有可能出现乱码,然后就导致换行出现问题,导入程序就会出现假死的状态,表现为程序一直在吃内存,可是一直导不进去数据,这时候可以用本人改动过的版本去导入,具体改动可见我github上的记录

相关文章推荐
- 如何使用batch-import工具向neo4j中导入海量数据
- neo4j的安装及使用neo4j-import导入数据
- mysqlimport工具的使用帮助文档(mysql导入csv数据,mysql备份数据恢复)
- 使用HBase自带的import工具导入数据遇到的两个问题
- Oracle exp/imp导出导入工具的使用
- exp/imp导出导入工具的使用
- exp/imp导出导入工具的使用
- MySQL数据导入导出方法与工具介绍(2-import from sql files)
- exp/imp导出导入工具的使用
- exp/imp导出导入工具的使用(转)
- [导入]如何使用 ASP.NET 实用工具加密凭据和会话状态连接字符串
- Oracle exp/imp导出导入工具的使用
- 使用xml语言自动导入测试需求到开源测试工具testlink
- exp/imp导出导入工具的使用
- 使用xml语言自动导入测试需求到开源测试工具testlink
- Data Import 2007 for MySql,MySql Data Wizard 导入XML到MySql使用经验
- exp/imp导出导入工具的使用 - -
- Asp.net中不需要导入(Import)便可以使用的8种Namespace
- ORACLE数据导出与导入专题(3)——使用exp/imp工具进行数据导入导出
- MySQL数据导入导出方法与工具介绍(1- myslqimport utility)