基于FEA spk的web日志分析
2017-06-15 21:41
357 查看
数据准备
数据:美国宇航局肯尼迪航天中心WEB日志
数据下载:http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html
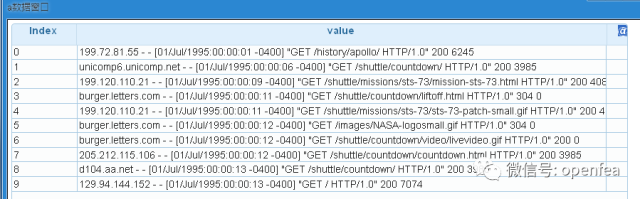
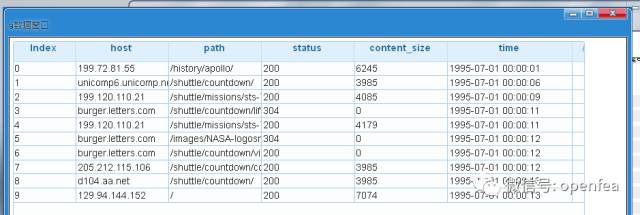
我们先来看看数据:首先将日志加载到df表,并查看前十行
打开fea的界面,运行以下命令
spk= @udf df0@sys by spk.open_spark
#创建spk的连接
df= @udf spk by spk.load_text with (/data/access_log_Jul95)
#加载hdfs目录/data/access_log_Jul95里面的text文件
a= @udf df by spk.dump
dump a
下面给出字段的解释:
df1= @udf df by spk.reg_extract with (regexp_extract('value', r'^([^\s]+\s)', 1).alias("host"),
regexp_extract('value', r'^.*\[(\d\d/\w{3}/\d{4}:\d{2}:\d{2}:\d{2} -\d{4})]', 1).alias('timestamp'),
regexp_extract('value', r'^.*"\w+\s+([^\s]+)\s+HTTP.*"', 1).alias('path'),
regexp_extract('value', r'^.*"\s+([^\s]+)', 1).cast('integer').alias('status'),
regexp_extract('value', r'^.*\s+(\d+)$', 1).cast('integer').alias('content_size'))
#将df表的value字段进行正则表达式提取出第一个匹配的主机名,将其重命名为host列
将df表的value字段进行正则表达式提取出第一个匹配的时间,将其重命名为timestamp列
将df表的value字段进行正则表达式提取出第一个匹配的路径,将其重命名为path列
将df表的value字段进行正则表达式提取出第一个匹配的状态码,将它的类型转化为int类型并将其重命名为status列
将df表的value字段进行正则表达式提取出第一个匹配的状态码,将它的类型转化为int类型并将其重命名为status列
将df表的value字段进行正则表达式提取出第一个匹配的字节数,将它的类型转化为int类型并将其重命名为content_size列
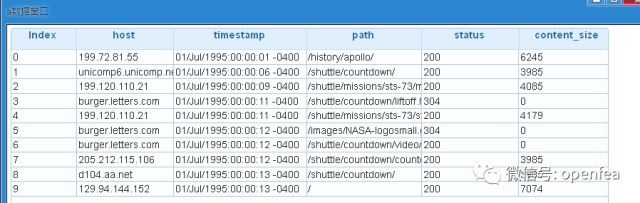
a= @udf df1 by spk.dump
dump a
a= @udf df by spk.df_null_count
dump a
可以看到原始数据没有空行
下面我们统计每列有多少个null值
a= @udf df1 by spk.df_null_count
dump
可以看到status列有一个空值,content_size列有19727个空值
df1= @udf df1 by spk.drop_null with (status)
#对status这列值进行过滤为null的数据
dump a

a= @udf df1 by spk.df_null_count
可以看到已经过滤掉了
df1= @udf df1 by spk.df_fillna with (content_size:0)
#将content_size列为空值的填充为0
a= @udf df1 by spk.df_null_count
dump a


可以看到所有的列没有空值了,下面进行数据的转换
df2= @udf df1 by spk.parse_time with ('timestamp','time')
#将apache服务器的时间格式timestamp列转化为列为time的标准的时间戳格式
a= @udf df2 by spk.dump
dump a
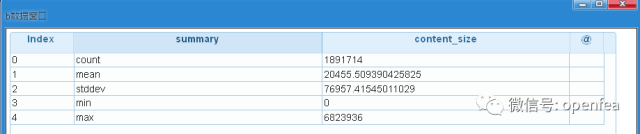
我们先看一下content_size这一列数据的统计值:最大值,最小值,count等
df3= @udf df2 by spk.df_desc with (content_size)
#统计content_size这一列的最大值,最小值等指标
b= @udf df3 by spk.to_DF
dump b
HTTP响应状态统计
下面我们来分析一下HTTP的响应状态,我们把数据按照status分组计数,然后按照status排序
df4= @udf df2 by spk.df_agg_count with (status)
#将status字段进行分组统计计数
df4= @udf df4 by spk.order with (status)
#将统计后的结果按照status字段升序排序
a= @udf df4 by spk.to_DF
dump a
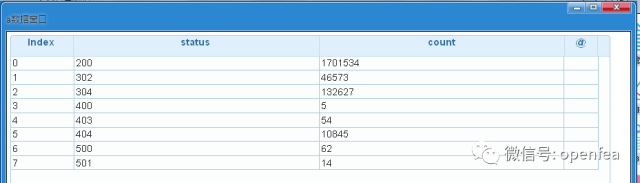
由此可以看到status=200的占据了很大一部分比例
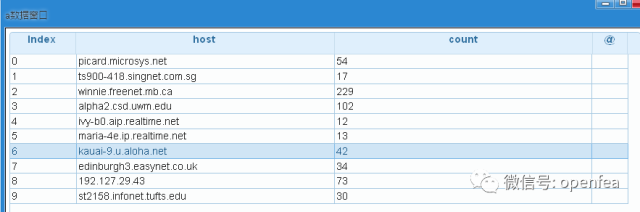
客户端访问频率统计,统计一下访问服务器次数超过10次host
df5= @udf df2 by spk.df_agg_count with (host)
#对host字段进行分组统计次数
df5= @udf df5 by spk.filter with (count>10)
#对次数大于10的进行过滤,保留次数大于10
a= @udf df5 by spk.dump
dump a
URIs访问量统计. 统计服务区资源的访问量,首先按照path进行分组,然后计数
df6= @udf df2 by spk.df_agg_count with (path)
#对path字段进行分组统计计数
df6= @udf df6 by spk.order with (count,desc)
#将统计后的结果按照count字段进行降序排列
a= @udf df6 by spk.dump
dump a
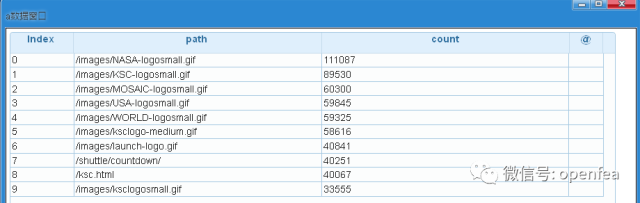
可以看到,图片的url访问量最多
统计HTTP返回状态不是200的十大URL。首先查询所有的 status <> 200 的记录, 然后按照path进行分组统计排序,显示结果
df7= @udf df2 by spk.filter with (status<>200)
#将status不是200的数据保留下来
df7= @udf df7 by spk.df_agg_count with (path)
#对过滤后的path字段进行分组计数
df7= @udf df7 by spk.order with (count,desc)
#将统计后的的表按照count降序排列
a= @udf df7 by spk.dump
#查看前10条数据
dump a
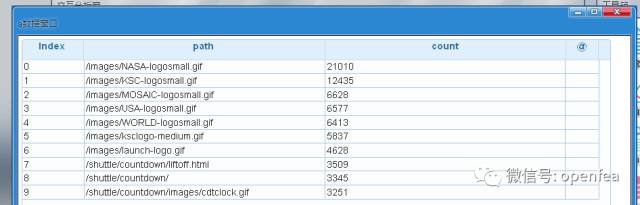
统计host的数量。潜在条件:对host字段进行去重
df8= @udf df2 by spk.loc with (host)
#选择host列
df8= @udf df8 by spk.distinct
#进行去重
b= @udf df8 by spk.count
#统计数量
dump b

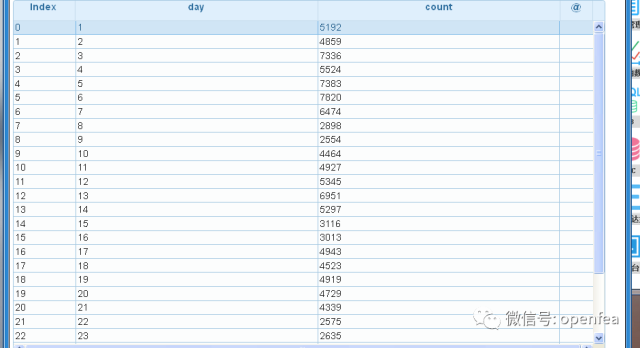
统计每日的访客数(根据host去重)
1, 选择 time 和 host 两列值
2, 将同一天的host相同进行去重
3, 最后按照day进行分组统计每天host访问量.
df9= @udf df2 by spk.extract
a49b
_day with ('host',dayofmonth('time').alias('day') )
#选择host列,从time字段提取出天数并命名为day列
df9= @udf df9 by spk.distinct
#对这2个字段进行去重
df9= @udf df9 by spk.df_agg_count with (day)
#对day字段进行分组统计
df9= @udf df9 by spk.order with (day)
#按照day字段从小到大排序
b= @udf df9 by spk.to_DF
dump b
数据:美国宇航局肯尼迪航天中心WEB日志
数据下载:http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html
我们先来看看数据:首先将日志加载到df表,并查看前十行
打开fea的界面,运行以下命令
spk= @udf df0@sys by spk.open_spark
#创建spk的连接
df= @udf spk by spk.load_text with (/data/access_log_Jul95)
#加载hdfs目录/data/access_log_Jul95里面的text文件
a= @udf df by spk.dump
dump a
下面给出字段的解释:
数据解析
首先我们将数据进行解析,这里会用到正则表达式df1= @udf df by spk.reg_extract with (regexp_extract('value', r'^([^\s]+\s)', 1).alias("host"),
regexp_extract('value', r'^.*\[(\d\d/\w{3}/\d{4}:\d{2}:\d{2}:\d{2} -\d{4})]', 1).alias('timestamp'),
regexp_extract('value', r'^.*"\w+\s+([^\s]+)\s+HTTP.*"', 1).alias('path'),
regexp_extract('value', r'^.*"\s+([^\s]+)', 1).cast('integer').alias('status'),
regexp_extract('value', r'^.*\s+(\d+)$', 1).cast('integer').alias('content_size'))
#将df表的value字段进行正则表达式提取出第一个匹配的主机名,将其重命名为host列
将df表的value字段进行正则表达式提取出第一个匹配的时间,将其重命名为timestamp列
将df表的value字段进行正则表达式提取出第一个匹配的路径,将其重命名为path列
将df表的value字段进行正则表达式提取出第一个匹配的状态码,将它的类型转化为int类型并将其重命名为status列
将df表的value字段进行正则表达式提取出第一个匹配的状态码,将它的类型转化为int类型并将其重命名为status列
将df表的value字段进行正则表达式提取出第一个匹配的字节数,将它的类型转化为int类型并将其重命名为content_size列
a= @udf df1 by spk.dump
dump a
数据清洗
首先我们查看一下原始日志包含多少空行。a= @udf df by spk.df_null_count
dump a

下面我们统计每列有多少个null值
a= @udf df1 by spk.df_null_count
dump

df1= @udf df1 by spk.drop_null with (status)
#对status这列值进行过滤为null的数据
dump a
a= @udf df1 by spk.df_null_count
可以看到已经过滤掉了
df1= @udf df1 by spk.df_fillna with (content_size:0)
#将content_size列为空值的填充为0
a= @udf df1 by spk.df_null_count
dump a
可以看到所有的列没有空值了,下面进行数据的转换
数据转换
现在数据框中的timestamp列并不是实际的时间戳,而是apache服务器的时间格式:[dd/mmm/yyyy:hh:mm:ss (+/-)zzzz],接下来我们将其转换为标准的时间戳格式df2= @udf df1 by spk.parse_time with ('timestamp','time')
#将apache服务器的时间格式timestamp列转化为列为time的标准的时间戳格式
a= @udf df2 by spk.dump
dump a
数据统计
数据总览我们先看一下content_size这一列数据的统计值:最大值,最小值,count等
df3= @udf df2 by spk.df_desc with (content_size)
#统计content_size这一列的最大值,最小值等指标
b= @udf df3 by spk.to_DF
dump b
HTTP响应状态统计
下面我们来分析一下HTTP的响应状态,我们把数据按照status分组计数,然后按照status排序
df4= @udf df2 by spk.df_agg_count with (status)
#将status字段进行分组统计计数
df4= @udf df4 by spk.order with (status)
#将统计后的结果按照status字段升序排序
a= @udf df4 by spk.to_DF
dump a
由此可以看到status=200的占据了很大一部分比例
客户端访问频率统计,统计一下访问服务器次数超过10次host
df5= @udf df2 by spk.df_agg_count with (host)
#对host字段进行分组统计次数
df5= @udf df5 by spk.filter with (count>10)
#对次数大于10的进行过滤,保留次数大于10
a= @udf df5 by spk.dump
dump a
URIs访问量统计. 统计服务区资源的访问量,首先按照path进行分组,然后计数
df6= @udf df2 by spk.df_agg_count with (path)
#对path字段进行分组统计计数
df6= @udf df6 by spk.order with (count,desc)
#将统计后的结果按照count字段进行降序排列
a= @udf df6 by spk.dump
dump a
可以看到,图片的url访问量最多
统计HTTP返回状态不是200的十大URL。首先查询所有的 status <> 200 的记录, 然后按照path进行分组统计排序,显示结果
df7= @udf df2 by spk.filter with (status<>200)
#将status不是200的数据保留下来
df7= @udf df7 by spk.df_agg_count with (path)
#对过滤后的path字段进行分组计数
df7= @udf df7 by spk.order with (count,desc)
#将统计后的的表按照count降序排列
a= @udf df7 by spk.dump
#查看前10条数据
dump a
统计host的数量。潜在条件:对host字段进行去重
df8= @udf df2 by spk.loc with (host)
#选择host列
df8= @udf df8 by spk.distinct
#进行去重
b= @udf df8 by spk.count
#统计数量
dump b
统计每日的访客数(根据host去重)
1, 选择 time 和 host 两列值
2, 将同一天的host相同进行去重
3, 最后按照day进行分组统计每天host访问量.
df9= @udf df2 by spk.extract
a49b
_day with ('host',dayofmonth('time').alias('day') )
#选择host列,从time字段提取出天数并命名为day列
df9= @udf df9 by spk.distinct
#对这2个字段进行去重
df9= @udf df9 by spk.df_agg_count with (day)
#对day字段进行分组统计
df9= @udf df9 by spk.order with (day)
#按照day字段从小到大排序
b= @udf df9 by spk.to_DF
dump b

相关文章推荐
- 基于FEA spk的web日志分析
- 基于MapReduce的海量Web日志分析
- 基于Hive的海量Web日志分析
- AWStats 基于Perl的WEB日志分析工具 在 windows server 2003 安装配置详解
- WEB站点请求耗时分析-基于MongoDB的日志分析系统
- AWStats是一个基于Perl的WEB日志分析工具。
- Web服务器日志统计分析完全解决方案
- 基于web信息管理系统的权限设计分析和总结
- 构建基于Web的分析系统
- 基于web信息管理系统的权限设计分析和总结(数据结构)
- 基于web信息管理系统的权限设计分析和总结(理论)
- Web服务器日志统计分析完全解决方案
- WEB中基于XMLHTTP的简单实例分析
- web 安全实践(1)基于http的架构分析常用工具
- 构建基于Web的分析系统
- web日志分析工具
- 基于.NET 2.0的GIS开源项目SharpMap分析手记(五):WebGIS原理分析及思考
- Web服务器日志统计分析完全解决方案
- AWStats 一个不错的Web/Mail/FTP日志分析工具