【Machine Learning notes(机器学习笔记-001)】
2017-06-15 21:04
417 查看
coursera:
【1】https://www.coursera.org/learn/machine-learning/home/welcome
【2】http://cs229.stanford.edu/
【3】http://open.163.com/movie/2008/1/M/C/M6SGF6VB4_M6SGHFBMC.html
1)机器学习定义
机器学习的定义
Arthur Samuel (1959). Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed.
Tom Mitchell (1998) Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P,
improves with experience E.
2)本节课程学习重点:
机器学习的动机与应用;Logistics类;机器学习的定义;监督学习概述;学习理论概述;非监督学习概述;强化学习概述
本课内容主要分为四个部分:Supervised Learning(监督学习)、Learning Theory(学习理论)、Unsupervised Learning(非监督式学习)、Reinforcement Learning(强化学习)
3)监督学习(Supervised Learning)
之所以被称为”监督学习”,是因为我们在“监督”问题的算法,换句话说,会给出一组“标准答案”。
下面给出两个监督学习的实例。
首先是一个房子价格预测的例子,收集的部分数据集如下:
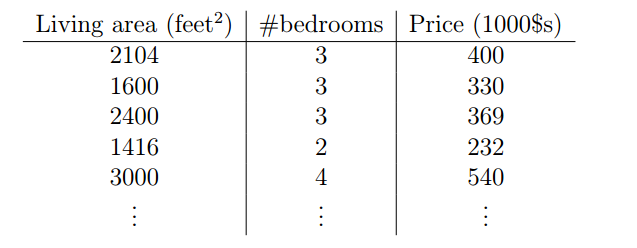
通过上面的数据集,可以绘出一个图,横坐标是占地面积,纵坐标是价格,根据这些数据,可以根据不同的方法拟合出不同的直线。
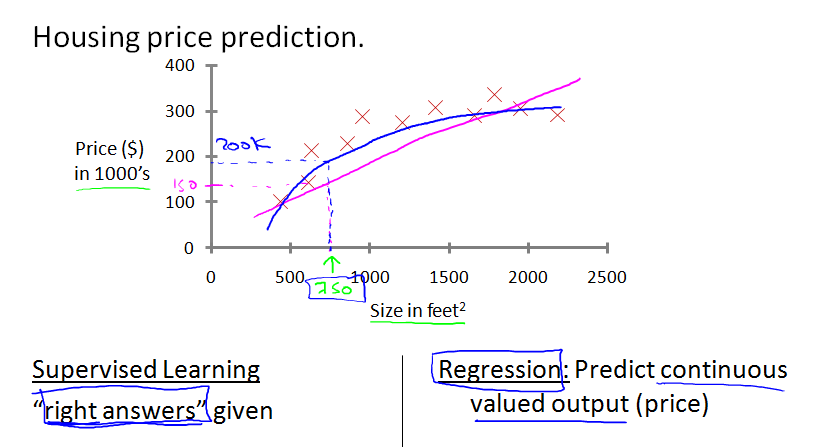
然后可以根据一直的房子占地大小,来预测房屋的价格。
下面是一个分类的问题,根据肿瘤的大小来预测乳腺癌的良性或劣性。
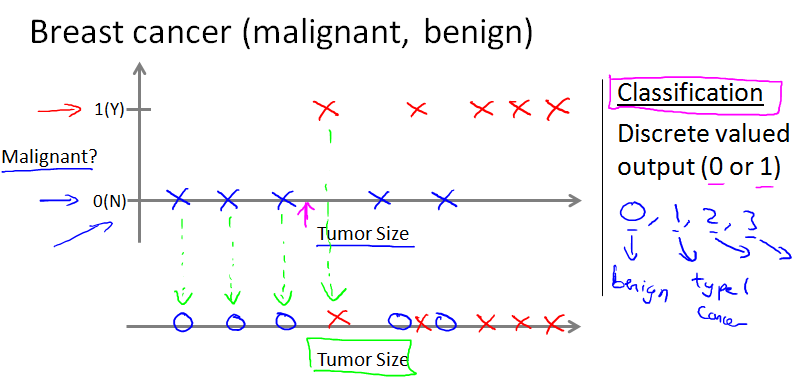
说明:“X”表示肿瘤为良性,“O”表示肿瘤为劣性。
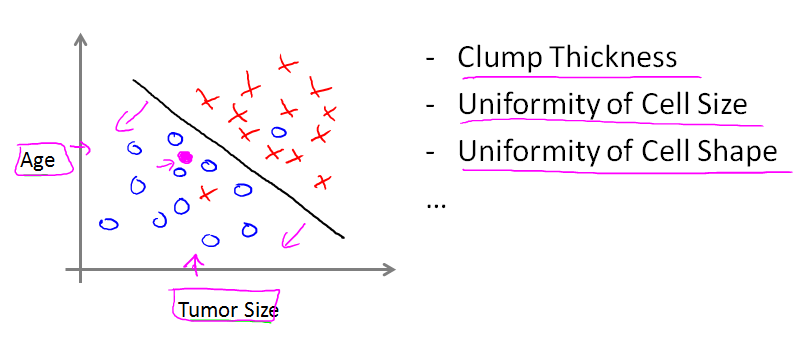
表示不同年龄的人和不同肿瘤大小组成的数据,“X”表示肿瘤为良性,“O”表示肿瘤为劣性。可以通过一个算法将其分成两类。
这只是一个线性二维的问题,如果有多维数据呢?后面说的SVM(支持向量机)就可以用来处理高维数据。
首先看看下面这个图
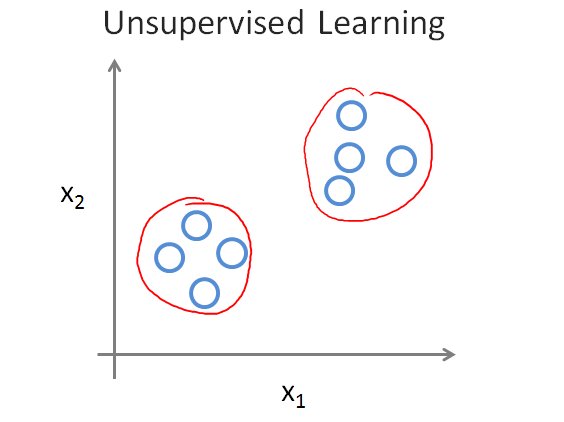
非监督学习事实上就是聚类,将许多的数据或是杂乱无章划分成相似的多个类别。
例如:将鸡尾酒会上混乱无章的多种声音区分出来。
5)Reinforcement Learning(强化学习)
是一种评价式的学习方式,基于回报函数。
参考:http://blog.csdn.net/Dream_angel_Z/article/details/45932185
【1】https://www.coursera.org/learn/machine-learning/home/welcome
【2】http://cs229.stanford.edu/
【3】http://open.163.com/movie/2008/1/M/C/M6SGF6VB4_M6SGHFBMC.html
1)机器学习定义
机器学习的定义
Arthur Samuel (1959). Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed.
Tom Mitchell (1998) Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P,
improves with experience E.
2)本节课程学习重点:
机器学习的动机与应用;Logistics类;机器学习的定义;监督学习概述;学习理论概述;非监督学习概述;强化学习概述
本课内容主要分为四个部分:Supervised Learning(监督学习)、Learning Theory(学习理论)、Unsupervised Learning(非监督式学习)、Reinforcement Learning(强化学习)
3)监督学习(Supervised Learning)
之所以被称为”监督学习”,是因为我们在“监督”问题的算法,换句话说,会给出一组“标准答案”。
下面给出两个监督学习的实例。
首先是一个房子价格预测的例子,收集的部分数据集如下:
通过上面的数据集,可以绘出一个图,横坐标是占地面积,纵坐标是价格,根据这些数据,可以根据不同的方法拟合出不同的直线。
然后可以根据一直的房子占地大小,来预测房屋的价格。
下面是一个分类的问题,根据肿瘤的大小来预测乳腺癌的良性或劣性。
说明:“X”表示肿瘤为良性,“O”表示肿瘤为劣性。
表示不同年龄的人和不同肿瘤大小组成的数据,“X”表示肿瘤为良性,“O”表示肿瘤为劣性。可以通过一个算法将其分成两类。
这只是一个线性二维的问题,如果有多维数据呢?后面说的SVM(支持向量机)就可以用来处理高维数据。
4 )非监督学习(UnSupervised
Learning)
首先看看下面这个图 非监督学习事实上就是聚类,将许多的数据或是杂乱无章划分成相似的多个类别。
例如:将鸡尾酒会上混乱无章的多种声音区分出来。
5)Reinforcement Learning(强化学习)
是一种评价式的学习方式,基于回报函数。
参考:http://blog.csdn.net/Dream_angel_Z/article/details/45932185

相关文章推荐
- Machine Learning Foundations(机器学习基石)笔记 第一节
- 机器学习_论文笔记_1: A few useful things to know about machine learning
- Andrew NG 机器学习 笔记-week10-大规模机器学习(Large Scale Machine Learning)
- 笔记: 斯坦福大学机器学习第十课“应用机器学习的建议(Advice for applying machine learning)”
- Machine Learning Foundations(机器学习基石)笔记 第二节
- building machine learning system with Python 学习笔记--从零开始机器学习(1)搭建环境
- 机器学习笔记1 - Hello World In Machine Learning
- 【李宏毅老师机器学习课程笔记】第一课:What is Machine Learning, Deep Learning and Structured Learning?
- Machine Learning Foundations(机器学习基石) By Hsuan-Tien Lin (林轩田) week1 笔记
- [机器学习基础] Notes on Machine Learning
- Stanford 机器学习笔记 Week6 Advice for Applying Machine Learning
- 李宏毅机器学习自己的笔记(一)----------Introduction of MachineLearning
- Coursera公开课笔记: 斯坦福大学机器学习第十课“应用机器学习的建议(Advice for applying machine learning)”
- 吴恩达 机器学习 笔记 some tips on applying machine Learning
- Stanford 机器学习笔记 Week10 Large Scale Machine Learning
- Stanford机器学习笔记-7. Machine Learning System Design
- 李宏毅机器学习笔记(二)-------Why we need learn Machine Learning?
- 【deeplearning.ai笔记第二课】1.3 机器学习基本方法(Basic recipe for machine learning)
- building machine learning system with Python 学习笔记--从零开始机器学习(2)第一章
- Stanford 机器学习笔记 Week6 Machine Learning System Design