UFLDL(1)Sparse Autoencoder
2017-06-14 17:53
211 查看
1. The second term is a regularization term (also called a weight
decay term) that tends to decrease the magnitude of the weights, and helps prevent
overfitting. you may also recognize this weight decay as essentially a variant of the Bayesian regularization method you saw there, where we placed a
Gaussian prior on the parameters and did MAP (instead of maximum likelihood) estimation.
2.To train our neural network, we will initialize each parameter
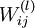
and
each
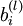
to a small random
value near zero (say according to a Normal(0,ε2) distribution
for some small ε, say 0.01。Finally,
note that it is important to initialize the parameters randomly, rather than to all 0's. If all the parameters start off at identical values, then all the hidden layer units will end up learning the same function of the input
(more formally,
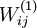
will
be the same for all values of i, so that
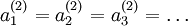
for
any input x).
3.we would like to compute an "error term"
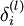
that
measures how much that node was "responsible" for any errors in our output. 。
4.But
if there is structure in the data, for example, if some of the input features are correlated, then this algorithm will be able to discover some of those correlations. In fact, this simple autoencoder often ends up learning
a low-dimensional representation very similar to PCAs.
练习题中有一点感觉不明白,经过lbfgs学习之后,我以后每个隐藏节点的平均激活值应该跟sparsityParam差不多大小,这里sparsityParam为0.01,但是训练完毕后,我才发现每个隐藏节点的平均激活值为0.4左右。差距太大了。不知道是什么原因。
decay term) that tends to decrease the magnitude of the weights, and helps prevent
overfitting. you may also recognize this weight decay as essentially a variant of the Bayesian regularization method you saw there, where we placed a
Gaussian prior on the parameters and did MAP (instead of maximum likelihood) estimation.
2.To train our neural network, we will initialize each parameter
and
each
to a small random
value near zero (say according to a Normal(0,ε2) distribution
for some small ε, say 0.01。Finally,
note that it is important to initialize the parameters randomly, rather than to all 0's. If all the parameters start off at identical values, then all the hidden layer units will end up learning the same function of the input
(more formally,
will
be the same for all values of i, so that
for
any input x).
3.we would like to compute an "error term"
that
measures how much that node was "responsible" for any errors in our output. 。
4.But
if there is structure in the data, for example, if some of the input features are correlated, then this algorithm will be able to discover some of those correlations. In fact, this simple autoencoder often ends up learning
a low-dimensional representation very similar to PCAs.
练习题中有一点感觉不明白,经过lbfgs学习之后,我以后每个隐藏节点的平均激活值应该跟sparsityParam差不多大小,这里sparsityParam为0.01,但是训练完毕后,我才发现每个隐藏节点的平均激活值为0.4左右。差距太大了。不知道是什么原因。

相关文章推荐
- 【UFLDL-exercise1-Sparse Autoencoder】
- UFLDL 学习笔记——稀疏自动编码机(sparse autoencoder)
- UFLDL教程Exercise答案(1):Sparse Autoencoder
- 【UFLDL】Ex1-SparseAutoencoder 稀疏自编码器
- UFLDL编程练习——Sparse Autoencoder
- UFLDL教程之一 (Sparse Autoencoder练习)
- UFLDL——Exercise: Sparse Autoencoder 稀疏自动编码
- Deep Learning 1_深度学习UFLDL教程:Sparse Autoencoder练习(斯坦福大学深度学习教程)
- UFLDL Exercise:Sparse Autoencoder
- UFLDL教程: Exercise: Sparse Autoencoder
- UFLDL教程 Exercise:Sparse Autoencoder(答案)
- UFLDL实验报告2:Sparse Autoencoder
- SparseAutoEncoder 稀疏编码详解(Andrew ng课程系列)
- Deep Learning 练习一:Sparse Autoencoder
- UFLDL教程: Exercise:Learning color features with Sparse Autoencoders
- sparse coding VS autoencoder
- 熵、交叉熵、相对熵和sparse autoencoder
- sparse autoencoder
- sparse Autoencoder(3)---自编码算法与稀疏性
- (六)6.5 Neurons Networks Implements of Sparse Autoencoder