通过BlukLoad的方式快速导入海量数据
2017-06-12 22:05
246 查看
http://www.cnblogs.com/MOBIN/p/5559575.html摘要加载数据到HBase的方式有多种,通过HBase API导入或命令行导入或使用第三方(如sqoop)来导入或使用MR来批量导入(耗费磁盘I/O,容易在导入的过程使用节点宕机),但是这些方式不是慢就是在导入的过程的占用Region资料导致效率低下,今天要讲的就是利用HBase在HDFS存储原理及MapReduce的特性来快速导入海量的数据HBase数据在HDFS下是如何存储的?HBase中每张Table在根目录(/HBase)下用一个文件夹存储,Table名为文件夹名,在Table文件夹下每个Region同样用一个文件夹存储,每个Region文件夹下的每个列族也用文件夹存储,而每个列族下存储的就是一些HFile文件,HFile就是HBase数据在HFDS下存储格式,其整体目录结构如下:/hbase/<tablename>/<encoded-regionname>/<column-family>/<filename>HBase数据写路径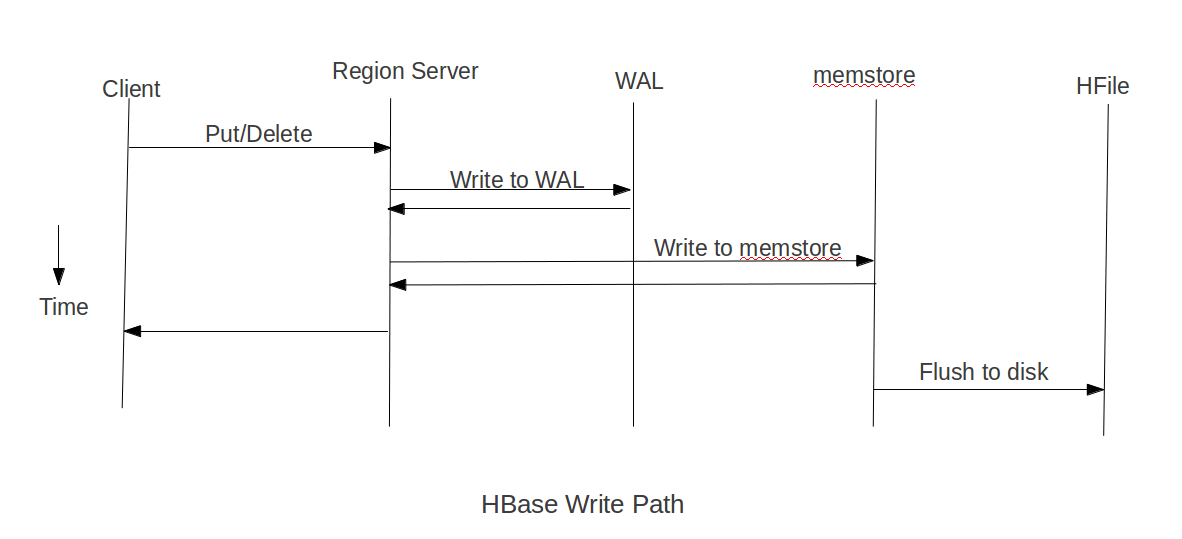 (图来自Cloudera)在put数据时会先将数据的更新操作信息和数据信息写入WAL,在写入到WAL后,数据就会被放到MemStore中,当MemStore满后数据就会被flush到磁盘(即形成HFile文件),在这过程涉及到的flush,split,compaction等操作都容易造成节点不稳定,数据导入慢,耗费资源等问题,在海量数据的导入过程极大的消耗了系统性能,避免这些问题最好的方法就是使用BlukLoad的方式来加载数据到HBase中。原理利用HBase数据按照HFile格式存储在HDFS的原理,使用Mapreduce直接生成HFile格式文件后,RegionServers再将HFile文件移动到相应的Region目录下其流程如下图:
(图来自Cloudera)在put数据时会先将数据的更新操作信息和数据信息写入WAL,在写入到WAL后,数据就会被放到MemStore中,当MemStore满后数据就会被flush到磁盘(即形成HFile文件),在这过程涉及到的flush,split,compaction等操作都容易造成节点不稳定,数据导入慢,耗费资源等问题,在海量数据的导入过程极大的消耗了系统性能,避免这些问题最好的方法就是使用BlukLoad的方式来加载数据到HBase中。原理利用HBase数据按照HFile格式存储在HDFS的原理,使用Mapreduce直接生成HFile格式文件后,RegionServers再将HFile文件移动到相应的Region目录下其流程如下图: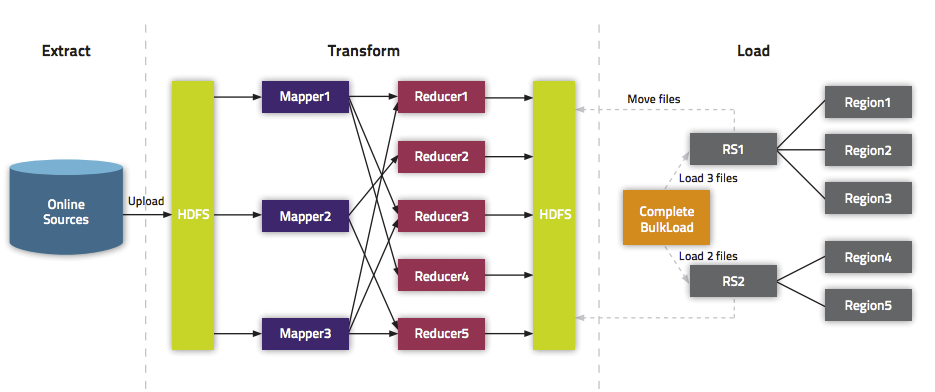 (图来自Cloudera)导入过程1.使用MapReduce生成HFile文件GenerateHFile类
(图来自Cloudera)导入过程1.使用MapReduce生成HFile文件GenerateHFile类
GenerateHFileMain类
注意1.Mapper的输出Key类型必须是包含Rowkey的ImmutableBytesWritable格式,Value类型必须为KeyValue或Put类型,当导入的数据有多列时使用Put,只有一个列时使用KeyValue2.job.setMapOutPutValueClass的值决定了job.setReduceClass的值,这里Reduce主要起到了对数据进行排序的作用,当job.setMapOutPutValueClass的值Put.class和KeyValue.class分别对应job.setReduceClass的PutSortReducer和KeyValueSortReducer3.在创建表时对表进行预分区再结合MapReduce的并行计算机制能加快HFile文件的生成,如果对表进行了预分区(Region)就设置Reduce数等于分区数(Region)4.在多列族的情况下需要进行多次的context.write2.通过BlukLoad方式加载HFile文件
由于BlukLoad是绕过了Write to WAL,Write to MemStore及Flush to disk的过程,所以并不能通过WAL来进行一些复制数据的操作优点:1.导入过程不占用Region资源2.能快速导入海量的数据3.节省内存
(图来自Cloudera)在put数据时会先将数据的更新操作信息和数据信息写入WAL,在写入到WAL后,数据就会被放到MemStore中,当MemStore满后数据就会被flush到磁盘(即形成HFile文件),在这过程涉及到的flush,split,compaction等操作都容易造成节点不稳定,数据导入慢,耗费资源等问题,在海量数据的导入过程极大的消耗了系统性能,避免这些问题最好的方法就是使用BlukLoad的方式来加载数据到HBase中。原理利用HBase数据按照HFile格式存储在HDFS的原理,使用Mapreduce直接生成HFile格式文件后,RegionServers再将HFile文件移动到相应的Region目录下其流程如下图:(图来自Cloudera)导入过程1.使用MapReduce生成HFile文件GenerateHFile类
相关文章推荐
- 通过BlukLoad的方式快速导入海量数据
- 通过BlukLoad的方式快速导入海量数据
- Hbase通过BulkLoad的方式快速导入海量数据
- 通过BulkLoad的方式快速导入海量数据到Hbase
- 通过BulkLoad的方式快速导入海量数据
- hbase通过BulkLoad的方式快速导入海量数据
- Spark上通过BulkLoad快速将海量数据导入到Hbase
- 在Spark上通过BulkLoad快速将海量数据导入Hbase
- 通过在VIOS上 复制lV的方式快速起虚机
- 通过利用VLOOKUP函数实现海量数据里快速获得精确查询
- oracle impdp通过network_link不落地方式导入数据
- 还在等待漫长的iOS构建过程?来试试通过命令行的方式进行iOS应用快速构建和运行吧
- Python 最近因开发项目的需要,有一个需求,就是很多SNS网站都有的通过 Email地址 导入好友列表,不过这次要导入的不是Email 列表,而是QQ的好友列表。 实现方式: 通过goog
- Oracle impdp通过network_link不落地方式导入数据
- 通过Bulk Load导入HBase海量数据
- 通过多种方式将数据导入hive表
- poi sax 方式 导入excel海量数据
- Oracle设计表、批处理方式快速导入到数据库示例
- 通过不同方式往Hive表中导入data
- 通过数据泵方式备份每月发送数据、并导入本地库