KMP算法及字符串匹配学习
2017-06-09 19:46
302 查看
KMP算法是一个效率很高的字符串匹配算法。
我们先看一下朴素的字符串匹配算法,将模式串的每一位与原串进行匹配,如果发生失配现象,则要将原串向前挪一位,以此类推,直到匹配成功为止,设模式串的长度为n,原串的长度为m,则匹配的时间复杂度为O(nm),KMP算法改进了失配后的操作,引进了next数组,加速了匹配,使字符串匹配的速度变成了线性O(n+m)。
假设我们匹配的过程中出现了这么一种情况,
在KMP算法中,此时会调用next数组,那么next数组是记录什么的呢?
next数组是记录模式串前i位前缀和后缀的最长公共长度。
假设我们现在匹配到了第i位,我们分析移位前后的模式串f有什么变化,得到如下结论。
A段字符串是f的一个前缀。
B段字符串是f的一个后缀。
A段字符串和B段字符串相等。
所以前移k位之后,可以继续比较位置i的前提是f的前i-1个位置满足:长度为i-k-1的前缀A和后缀B相同。只有这样,我们才可以前移k位后从新的位置继续比较。
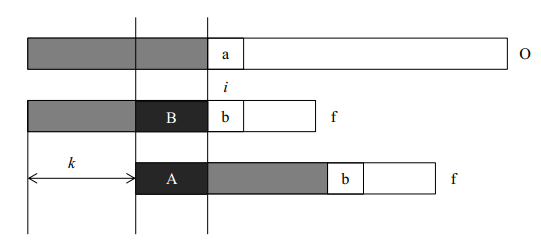
所以KMP算法的核心是计算字符串f每一个位置之前的前缀和后缀最长公共部分(不计算字符串本身),获得模式串f每一个位置的最大公共长度后,就可以利用该最大长度与原串O进行比较,当每次比较到两个字符串的字符不同时,我们就可以根据最大公共长度将字符串f向前移动(已匹配长度-最大公共长度)位,接着继续比较下一个位置。事实上,字符串f的前移只是概念上的前移,只要我们在比较的时候从最大公共长度之后比较f和O即可达到字符串f前移的目的。
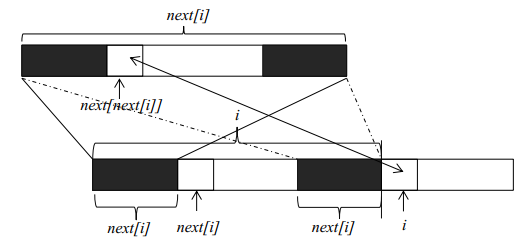
next[1],next[2],next[3]...next[i],分别表示长度为1到i的字符串的前缀和后缀最长公共部分的长度现在要求next[i+1],如果位置i和位置next[i]处的两个字符相同(下标从零开始),则next[i+1]等于next[i]加1。如果两个位置的字符不相同,我们可以将长度为next[i]的字符串继续分割,获得其最大公共长度next[next[i]],然后再和位置i的字符比较。这是因为长度为next[i]前缀和后缀都可以分割成上部的构造,如果位置next[next[i]]和位置i的字符相同,则next[i+1]就等于next[next[i]]加1。如果不相等,就可以继续分割长度为next[next[i]]的字符串,直到字符串长度为0为止。
如果匹配上了,就往后推一位,否则挪动公共的前缀到后缀处再进行匹配
我们先看一下朴素的字符串匹配算法,将模式串的每一位与原串进行匹配,如果发生失配现象,则要将原串向前挪一位,以此类推,直到匹配成功为止,设模式串的长度为n,原串的长度为m,则匹配的时间复杂度为O(nm),KMP算法改进了失配后的操作,引进了next数组,加速了匹配,使字符串匹配的速度变成了线性O(n+m)。
假设我们匹配的过程中出现了这么一种情况,
在KMP算法中,此时会调用next数组,那么next数组是记录什么的呢?
next数组是记录模式串前i位前缀和后缀的最长公共长度。
假设我们现在匹配到了第i位,我们分析移位前后的模式串f有什么变化,得到如下结论。
A段字符串是f的一个前缀。
B段字符串是f的一个后缀。
A段字符串和B段字符串相等。
所以前移k位之后,可以继续比较位置i的前提是f的前i-1个位置满足:长度为i-k-1的前缀A和后缀B相同。只有这样,我们才可以前移k位后从新的位置继续比较。
所以KMP算法的核心是计算字符串f每一个位置之前的前缀和后缀最长公共部分(不计算字符串本身),获得模式串f每一个位置的最大公共长度后,就可以利用该最大长度与原串O进行比较,当每次比较到两个字符串的字符不同时,我们就可以根据最大公共长度将字符串f向前移动(已匹配长度-最大公共长度)位,接着继续比较下一个位置。事实上,字符串f的前移只是概念上的前移,只要我们在比较的时候从最大公共长度之后比较f和O即可达到字符串f前移的目的。
Next数组求解:
理解了kmp算法的基本原理,下一步就是要获得字符串f每一个位置的最大公共长度。这个最大公共长度在算法导论里面被记为next数组。在这里要注意一点,next数组表示的是长度,下标从1开始;但是在遍历原字符串时,下标还是从0开始。 假设我们现在已经求得next[1],next[2],next[3]...next[i],分别表示长度为1到i的字符串的前缀和后缀最长公共部分的长度现在要求next[i+1],如果位置i和位置next[i]处的两个字符相同(下标从零开始),则next[i+1]等于next[i]加1。如果两个位置的字符不相同,我们可以将长度为next[i]的字符串继续分割,获得其最大公共长度next[next[i]],然后再和位置i的字符比较。这是因为长度为next[i]前缀和后缀都可以分割成上部的构造,如果位置next[next[i]]和位置i的字符相同,则next[i+1]就等于next[next[i]]加1。如果不相等,就可以继续分割长度为next[next[i]]的字符串,直到字符串长度为0为止。
void cal_next(char str[],int next[],int len)
{
int i , j ;
next[0] = -1;
for(int i = 1; i <= len; ++i)
{
j = next[ i - 1];
while(str[j+1] != str[i] && (j >= 0))
j = next[j];
if( str[i] == str[j+1])
next[i] = j + 1;
else
next[i] = -1;
}
}字符串匹配:
计算完next数组后,我们可以利用next数组在字符串O中找到字符串F出现的位置,匹配的代码和求next数组非常相似。如果匹配上了,就往后推一位,否则挪动公共的前缀到后缀处再进行匹配
int KMP( char str[], int slen, char ptr[], int plen, int next[] )
{
int s_i = 0, p_i = 0;
while( s_i < slen && p_i < plen )
{
if( str[ s_i ] == ptr[ p_i ] )
{
s_i++;
p_i++;
}
else
{
if( p_i == 0 )
s_i++;
else
p_i = next[ p_i - 1 ] + 1;
}
}
return ( p_i == plen ) ? ( s_i - plen ) : -1;
}

相关文章推荐
- 字符串匹配算法——KMP算法学习
- 字符串匹配算法之KMP算法的学习
- 字符串匹配-KMP算法学习笔记
- 字符串匹配-KMP算法学习笔记
- 【字符串匹配】KMP算法之道
- 字符串匹配之KMP算法
- KMP算法:字符串匹配
- 【字符串匹配】KMP算法之道
- 字符串---字符串匹配KMP算法
- 字符串匹配——KMP算法
- kmp算法实现的字符串匹配
- 字符串匹配KMP算法初探
- 最长字符串匹配算法(KMP算法)
- 字符串匹配算法之Sunday算法的学习笔记
- 字符串匹配KMP算法中Next[]数组求法
- 字符串匹配之有限自动机&kmp算法
- 字符串匹配算法:KMP学习心得
- 字符串匹配(KMP算法)
- KMP算法 字符串匹配
- KMP算法---处理字符串匹配