后缀数组——51nod 1732 51nod婚姻介绍所
2017-06-08 22:29
204 查看
https://www.51nod.com/onlineJudge/questionCode.html#!problemId=1732
很好的后缀数组练习题;
关于后缀数组我转载一篇博文
http://blog.csdn.net/yxuanwkeith/article/details/50636898
为什么学后缀数组
后缀数组是一个比较强大的处理字符串的算法,是有关字符串的基础算法,所以必须掌握。
学会后缀自动机(SAM)就不用学后缀数组(SA)了?不,虽然SAM看起来更为强大和全面,但是有些SAM解决不了的问题能被SA解决,只掌握SAM是远远不够的。
……
而下面是我对后缀数组的一些理解
构造后缀数组——SA
先定义一些变量的含义
Str :需要处理的字符串(长度为Len)
Suffix[i] :Str下标为i ~ Len的连续子串(即后缀)
Rank[i] : Suffix[i]在所有后缀中的排名
SA[i] : 满足Suffix[SA[1]] < Suffix[SA[2]] …… < Suffix[SA[Len]],即排名为i的后缀为Suffix[SA[i]] (与Rank是互逆运算)
好,来形象的理解一下
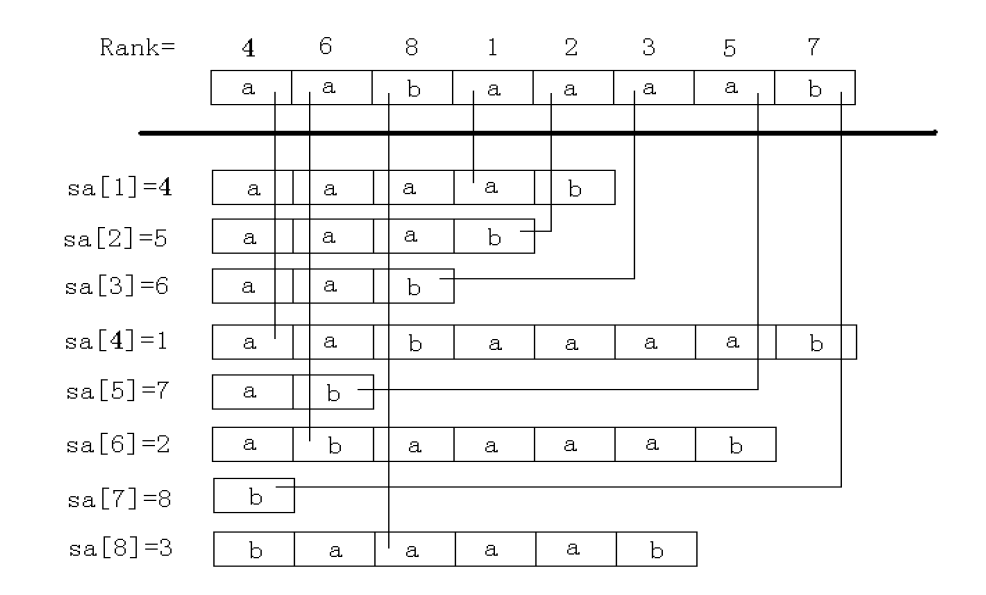
这就是Rank和SA
后缀数组指的就是这个SA[i],有了它,我们就可以实现一些很强大的功能(如不相同子串个数、连续重复子串等)。如何快速的到它,便成为了这个算法的关键。而SA和Rank是互逆的,只要求出任意一个,另一个就可以O(Len)得到。
现在比较主流的算法有两种,倍增和DC3,在这里,就主要讲一下稍微慢一些,但比较好实现以及理解的倍增算法(虽说慢,但也是O(Len logLen))的。
进入正题——倍增算法
倍增算法的主要思想 :对于一个后缀Suffix[i],如果想直接得到Rank比较困难,但是我们可以对每个字符开始的长度为2k的字符串求出排名,k从0开始每次递增1(每递增1就成为一轮),当2k大于Len时,所得到的序列就是Rank,而SA也就知道了。O(logLen)枚举k
这样做有什么好处呢?
设每一轮得到的序列为rank(注意r是小写,最终后缀排名Rank是大写)。有一个很美妙的性质就出现了!第k轮的rank可由第k - 1轮的rank快速得来!
为什么呢?为了方便描述,设SubStr(i, len)为从第i个字符开始,长度为len的字符串我们可以把第k轮SubStr(i, 2k)看成是一个由SubStr(i, 2k−1)和SubStr(i + 2k−1, 2k−1)拼起来的东西。类似rmq算法,这两个长度而2k−1的字符串是上一轮遇到过的!当然上一轮的rank也知道!那么吧每个这一轮的字符串都转化为这种形式,并且大家都知道字符串的比较是从左往右,左边和右边的大小我们可以用上一轮的rank表示,那么……这不就是一些两位数(也可以视为第一关键字和第二关键字)比较大小吗!再把这些两位数重新排名就是这一轮的rank。
我们用下面这张经典的图理解一下:
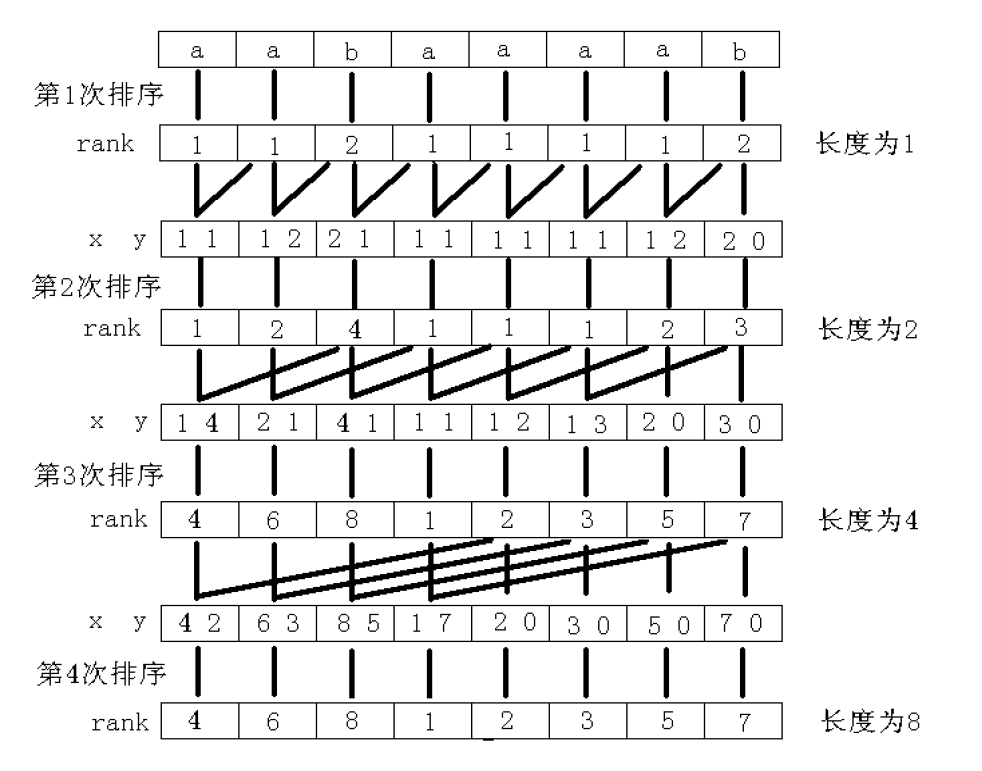
就像一个两位数的比较
相信只要理解字符串的比较法则(跟实数差不多),理解起来并不难。#还有一个细节就是
4000
怎么把这些两位数排序?这种位数少的数进行排序毫无疑问的要用一个复杂度为长度*排序数的个数的优美算法——基数排序(对于两位数的数复杂度就是O(Len)的)。
基数排序原理 : 把数字依次按照由低位到高位依次排序,排序时只看当前位。对于每一位排序时,因为上一位已经是有序的,所以这一位相等或符合大小条件时就不用交换位置,如果不符合大小条件就交换,实现可以用”桶”来做。(叙说起来比较奇怪,看完下面的代码应该更好理解,也可以上网查有关资料)
好了SA和Rank(大写R)到此为止就处理好了。(下面有详解代码!)。但我们发现,只有这两样东西好像没什么用,为了处理重复子串之类的问题,我们就要引入一个表示最长公共前缀的新助手Height数组!
构造最长公共前缀——Height
同样先是定义一些变量
Heigth[i] : 表示Suffix[SA[i]]和Suffix[SA[i - 1]]的最长公共前缀,也就是排名相邻的两个后缀的最长公共前缀
H[i] : 等于Height[Rank[i]],也就是后缀Suffix[i]和它前一名的后缀的最长公共前缀
而两个排名不相邻的最长公共前缀定义为排名在它们之间的Height的最小值。
跟上面一样,先形像的理解一下:
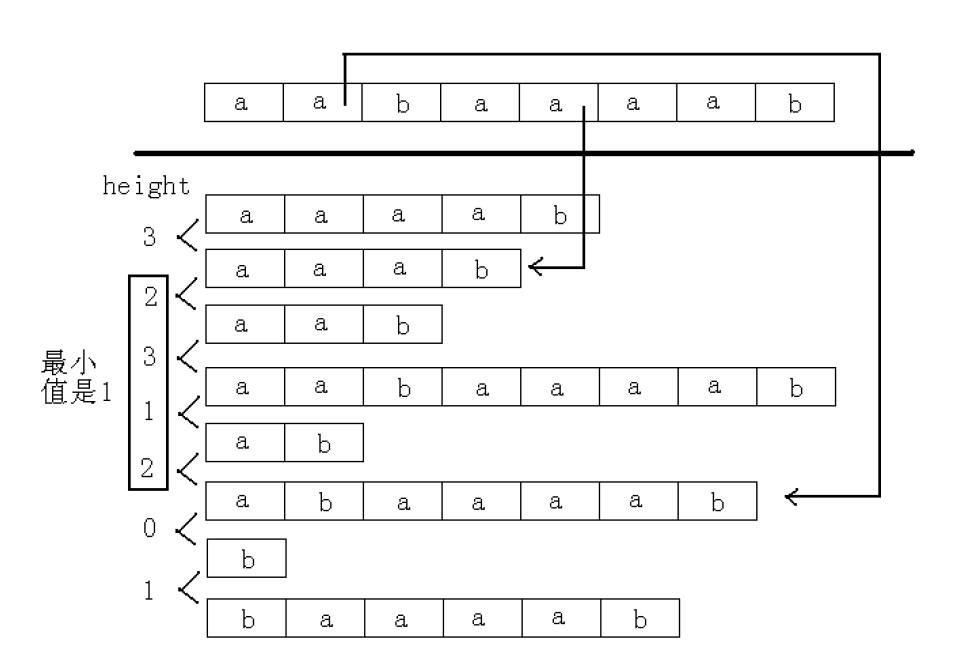
这就是Height
高效地得到Height数组
如果一个一个数按SA中的顺序比较的话复杂度是O(N2)级别的,想要快速的得到Height就需要用到一个关于H数组的性质。
H[i] ≥ H[i - 1] - 1!
如果上面这个性质是对的,那我们可以按照H[1]、H[2]……H[Len]的顺序进行计算,那么复杂度就降为O(N)了!
让我们尝试一下证明这个性质 : 设Suffix[k]是排在Suffix[i - 1]前一名的后缀,则它们的最长公共前缀是H[i - 1]。都去掉第一个字符,就变成Suffix[k + 1]和Suffix[i]。如果H[i - 1] = 0或1,那么H[i] ≥ 0显然成立。否则,H[i] ≥ H[i - 1] - 1(去掉了原来的第一个,其他前缀一样相等),所以Suffix[i]和在它前一名的后缀的最长公共前缀至少是H[i - 1] - 1。
仔细想想还是比较好理解的。H求出来,那Height就相应的求出来了,这样结合SA,Rank和Height我们就可以做很多关于字符串的题了!
这篇博客是极好;
尤其是图片;
我补充两点;
而两个排名不相邻的最长公共前缀定义为排名在它们之间的Height的最小值。
这个东西我们可以这么去理解;
我们可以看着那张图片,一列一列往下看,一单发现某列的char不是同一个,就无法在匹配了;
2.H[i] ≥ H[i - 1] - 1!
我来详细则证明一遍,这个是最难的;
如果H[i-1]<=1,则显然成立
不然
我们设sa[k]=rank[i-1]-1;
那么H[i-1]=lcp(i-1,k);
∵H[i-1]>=1
∴s[i-1]==s[k] (s为字符串)
∴lcp(i,k+1)=H[i-1]-1;
i和k+1=H[i-1]-1
i-1和k=H[i-1]
s[i-1]=s[k]
所以H[i]>=H[i-1]-1;
ok
代码里的H[]对应文章的Height数组
很好的后缀数组练习题;
关于后缀数组我转载一篇博文
http://blog.csdn.net/yxuanwkeith/article/details/50636898
为什么学后缀数组
后缀数组是一个比较强大的处理字符串的算法,是有关字符串的基础算法,所以必须掌握。
学会后缀自动机(SAM)就不用学后缀数组(SA)了?不,虽然SAM看起来更为强大和全面,但是有些SAM解决不了的问题能被SA解决,只掌握SAM是远远不够的。
……
而下面是我对后缀数组的一些理解
构造后缀数组——SA
先定义一些变量的含义
Str :需要处理的字符串(长度为Len)
Suffix[i] :Str下标为i ~ Len的连续子串(即后缀)
Rank[i] : Suffix[i]在所有后缀中的排名
SA[i] : 满足Suffix[SA[1]] < Suffix[SA[2]] …… < Suffix[SA[Len]],即排名为i的后缀为Suffix[SA[i]] (与Rank是互逆运算)
好,来形象的理解一下
这就是Rank和SA
后缀数组指的就是这个SA[i],有了它,我们就可以实现一些很强大的功能(如不相同子串个数、连续重复子串等)。如何快速的到它,便成为了这个算法的关键。而SA和Rank是互逆的,只要求出任意一个,另一个就可以O(Len)得到。
现在比较主流的算法有两种,倍增和DC3,在这里,就主要讲一下稍微慢一些,但比较好实现以及理解的倍增算法(虽说慢,但也是O(Len logLen))的。
进入正题——倍增算法
倍增算法的主要思想 :对于一个后缀Suffix[i],如果想直接得到Rank比较困难,但是我们可以对每个字符开始的长度为2k的字符串求出排名,k从0开始每次递增1(每递增1就成为一轮),当2k大于Len时,所得到的序列就是Rank,而SA也就知道了。O(logLen)枚举k
这样做有什么好处呢?
设每一轮得到的序列为rank(注意r是小写,最终后缀排名Rank是大写)。有一个很美妙的性质就出现了!第k轮的rank可由第k - 1轮的rank快速得来!
为什么呢?为了方便描述,设SubStr(i, len)为从第i个字符开始,长度为len的字符串我们可以把第k轮SubStr(i, 2k)看成是一个由SubStr(i, 2k−1)和SubStr(i + 2k−1, 2k−1)拼起来的东西。类似rmq算法,这两个长度而2k−1的字符串是上一轮遇到过的!当然上一轮的rank也知道!那么吧每个这一轮的字符串都转化为这种形式,并且大家都知道字符串的比较是从左往右,左边和右边的大小我们可以用上一轮的rank表示,那么……这不就是一些两位数(也可以视为第一关键字和第二关键字)比较大小吗!再把这些两位数重新排名就是这一轮的rank。
我们用下面这张经典的图理解一下:
就像一个两位数的比较
相信只要理解字符串的比较法则(跟实数差不多),理解起来并不难。#还有一个细节就是
4000
怎么把这些两位数排序?这种位数少的数进行排序毫无疑问的要用一个复杂度为长度*排序数的个数的优美算法——基数排序(对于两位数的数复杂度就是O(Len)的)。
基数排序原理 : 把数字依次按照由低位到高位依次排序,排序时只看当前位。对于每一位排序时,因为上一位已经是有序的,所以这一位相等或符合大小条件时就不用交换位置,如果不符合大小条件就交换,实现可以用”桶”来做。(叙说起来比较奇怪,看完下面的代码应该更好理解,也可以上网查有关资料)
好了SA和Rank(大写R)到此为止就处理好了。(下面有详解代码!)。但我们发现,只有这两样东西好像没什么用,为了处理重复子串之类的问题,我们就要引入一个表示最长公共前缀的新助手Height数组!
构造最长公共前缀——Height
同样先是定义一些变量
Heigth[i] : 表示Suffix[SA[i]]和Suffix[SA[i - 1]]的最长公共前缀,也就是排名相邻的两个后缀的最长公共前缀
H[i] : 等于Height[Rank[i]],也就是后缀Suffix[i]和它前一名的后缀的最长公共前缀
而两个排名不相邻的最长公共前缀定义为排名在它们之间的Height的最小值。
跟上面一样,先形像的理解一下:
这就是Height
高效地得到Height数组
如果一个一个数按SA中的顺序比较的话复杂度是O(N2)级别的,想要快速的得到Height就需要用到一个关于H数组的性质。
H[i] ≥ H[i - 1] - 1!
如果上面这个性质是对的,那我们可以按照H[1]、H[2]……H[Len]的顺序进行计算,那么复杂度就降为O(N)了!
让我们尝试一下证明这个性质 : 设Suffix[k]是排在Suffix[i - 1]前一名的后缀,则它们的最长公共前缀是H[i - 1]。都去掉第一个字符,就变成Suffix[k + 1]和Suffix[i]。如果H[i - 1] = 0或1,那么H[i] ≥ 0显然成立。否则,H[i] ≥ H[i - 1] - 1(去掉了原来的第一个,其他前缀一样相等),所以Suffix[i]和在它前一名的后缀的最长公共前缀至少是H[i - 1] - 1。
仔细想想还是比较好理解的。H求出来,那Height就相应的求出来了,这样结合SA,Rank和Height我们就可以做很多关于字符串的题了!
这篇博客是极好;
尤其是图片;
我补充两点;
而两个排名不相邻的最长公共前缀定义为排名在它们之间的Height的最小值。
这个东西我们可以这么去理解;
我们可以看着那张图片,一列一列往下看,一单发现某列的char不是同一个,就无法在匹配了;
2.H[i] ≥ H[i - 1] - 1!
我来详细则证明一遍,这个是最难的;
如果H[i-1]<=1,则显然成立
不然
我们设sa[k]=rank[i-1]-1;
那么H[i-1]=lcp(i-1,k);
∵H[i-1]>=1
∴s[i-1]==s[k] (s为字符串)
∴lcp(i,k+1)=H[i-1]-1;
i和k+1=H[i-1]-1
i-1和k=H[i-1]
s[i-1]=s[k]
所以H[i]>=H[i-1]-1;
ok
代码里的H[]对应文章的Height数组
#include<bits/stdc++.h>
#define rank fuck
#define Ll long long
using namespace std;
const int N=1e3+5;
inline Ll read(){ Ll x=0;char ch=getchar(); while(ch<'0'||ch>'9') ch=getchar(); while(ch>='0'&&ch<='9'){x=x*10+ch-'0';ch=getchar();} return x; }
inline void write(Ll x){ if (x>=10) write(x/10); putchar(x%10+'0'); }
inline void writeln(Ll x){ write(x); puts(""); }
struct zz{int id,x,y;}a
;
int rank
,sa
,h
;
int n,m,x,y,z;
char c
;
bool cmp(zz a,zz b){if(a.x!=b.x)return a.x<b.x;return a.y<b.y;}
void make(){
for(int i=1;i<=n;i++)rank[i]=c[i];
for(int i=0;(1<<i)<=n;i++){
for(int j=1;j<=n;j++){
a[j].id=j;
a[j].x=rank[j];
a[j].y=(j+(1<<i))<=n?rank[j+(1<<i)]:0;
}
sort(a+1,a+n+1,cmp);
int num=0;
for(int j=1;j<=n;j++){
num+=(a[j].x!=a[j-1].x||a[j].y!=a[j-1].y);
rank[a[j].id]=num;
}
}
for(int i=1;i<=n;i++)sa[rank[i]]=i;
for(int i=1,k=0;i<=n;h[rank[i]]=k,i++)
for(k?k--:k;c[i+k]==c[sa[rank[i]-1]+k];k++);
}
int main()
{
scanf("%d",&n);
scanf("%s",c+1);
make();
scanf("%d",&m);
while(m--){
x=read();y=read();int xx=x;
x=rank[x+1];
y=rank[y+1];
if(y<x)swap(x,y);
if(x==y)writeln(n-xx);else{
int mi=1e9;
for(int i=x+1;i<=y;i++)mi=min(mi,h[i]);
writeln(mi);
}
}
}

相关文章推荐
- 51nod 1732 51nod婚姻介绍所
- 51nod-1732 婚姻介绍所(后缀数组)
- 51nod 1732 51nod婚姻介绍所
- 【51nod】1732 51nod婚姻介绍所
- 51nod 1732 51nod婚姻介绍所
- 51nod 1732 51nod婚姻介绍所 后缀数组 + rmq
- 51nod 1732 51nod婚姻介绍所(LCS变形)
- 51Nod-1732-51Nod婚姻介绍所
- 51Nod 1732 51nod婚姻介绍所
- 51nod 1732 LCS变形
- 51nod 1440 迈克打电话 后缀数组+可持久化线段树+二分
- 后缀数组(入门)——51nod1732 51nod婚姻介绍所
- 51 nod 1732 51nod婚姻介绍所(后缀数组||DP)
- 51nod 1133【贪心】
- 51Nod 1137 矩阵乘法
- 51nod-1275 连续子段的差异(单调队列)
- 51nod 1076 2条不相交的路径(Tarjan,边双连通分量)
- 51nod 1264 线段相交
- 51Nod 1384 全排列(next-permutation)
- 51nod 1242 斐波那契数列的第N项(O(logn)求递推式)