IDEA 远程调试 Hadoop
2017-06-07 13:27
309 查看
一、创建maven下项目
二、pom引用
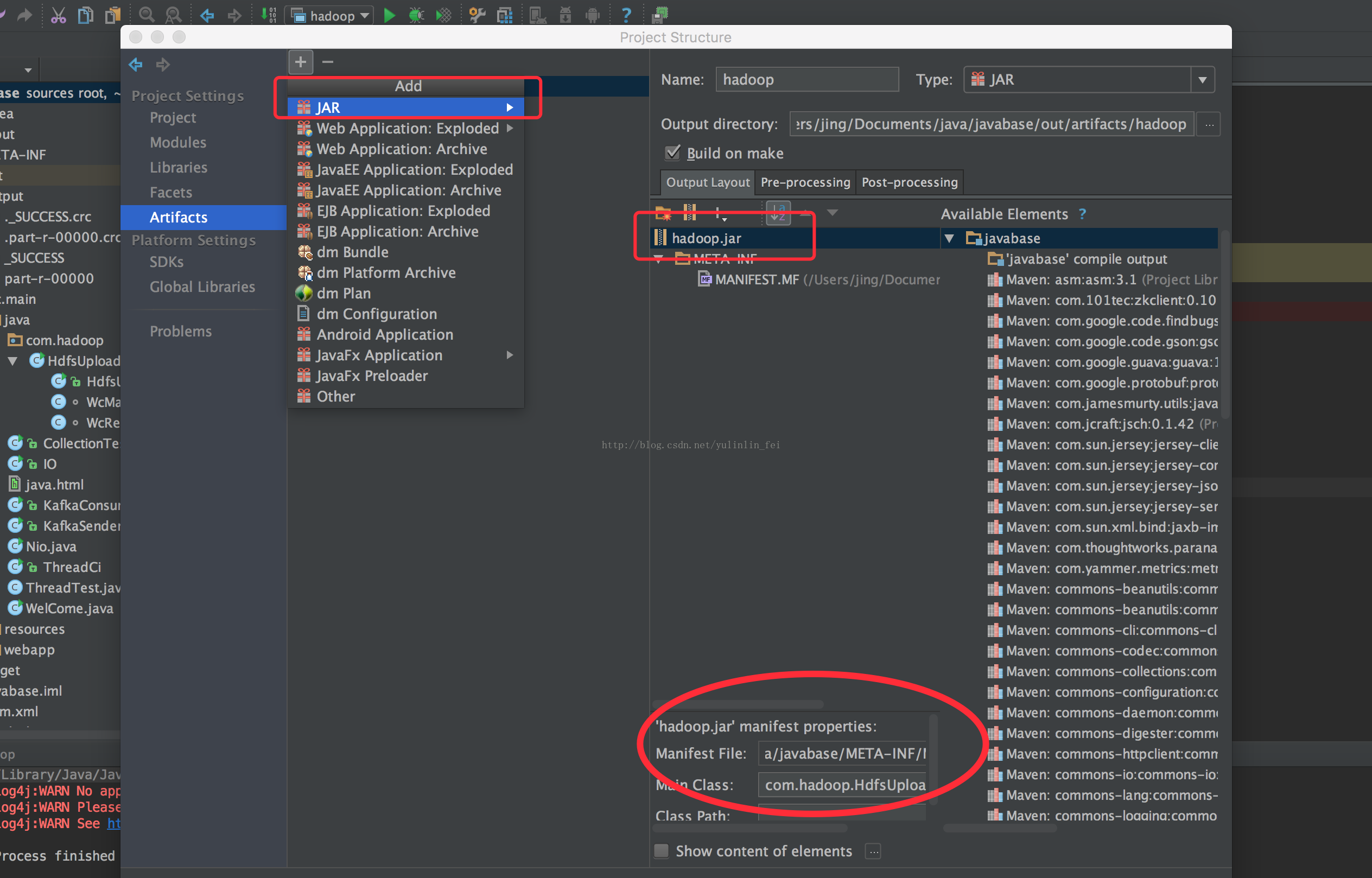
四、本地调式
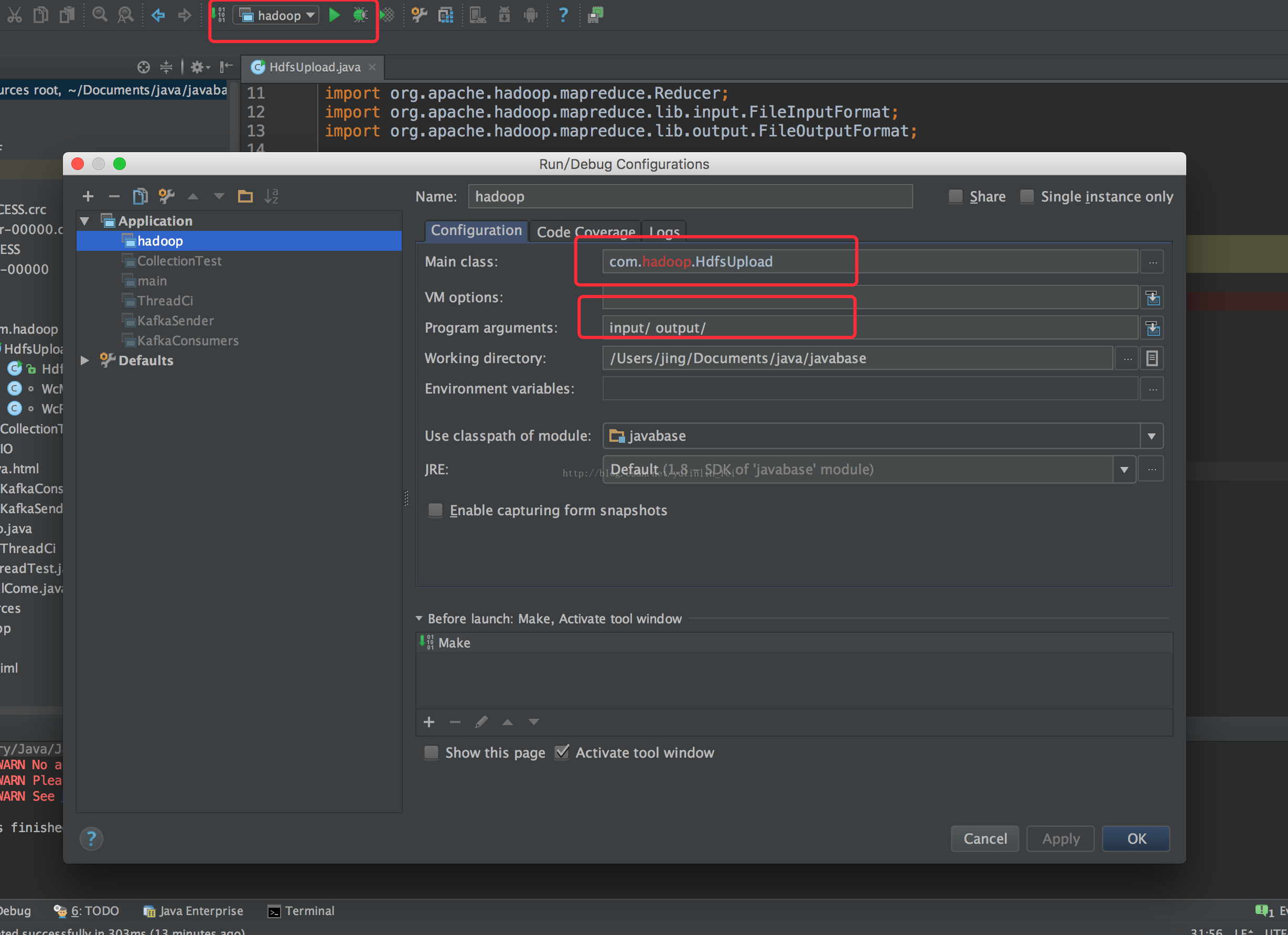
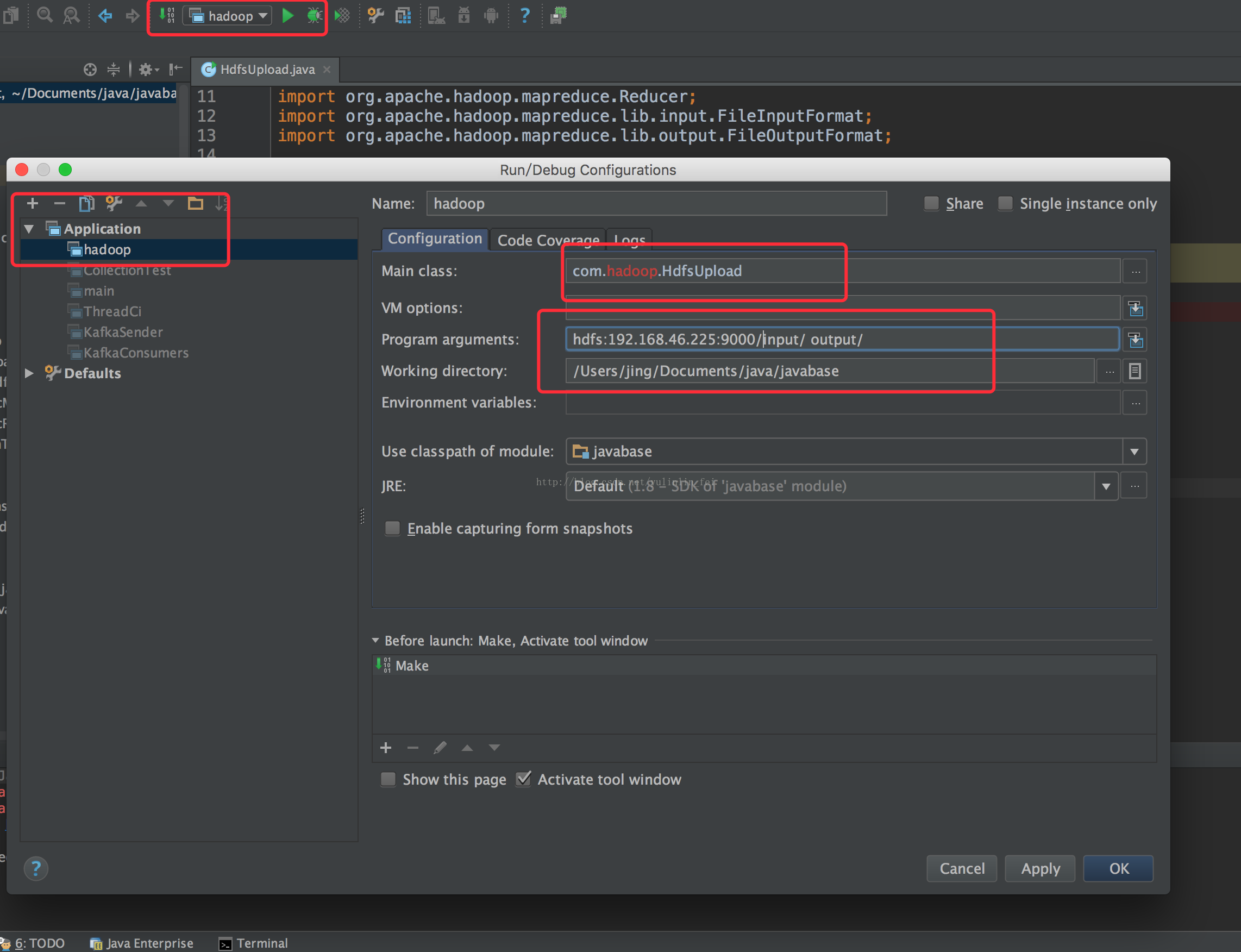
5、远程调式
示例代码:
package com.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Iterator;
import java.util.StringTokenizer;
import java.io.IOException;
/**
* Created by jing on 17/6/6.
*/
public class HdfsUpload {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("参数无效");
System.exit(-1);
}
Configuration conf = new Configuration();
//主要设置
conf.set("fs.defaultFS","hdfs://192.168.46.225:9000");
Job job = Job.getInstance();
job.setJarByClass(HdfsUpload.class);
job.setJobName("HdfsUpload");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
class WcReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Mapper.Context context)
throws IOException, InterruptedException {
int sum= 0;
Iterator<IntWritable> iterator=values.iterator();
while (iterator.hasNext()){
sum +=iterator.next().get();
}
context.write(key,new IntWritable(sum));
}
}
class WcMapper
extends Mapper<LongWritable, Text, Text, IntWritable> { //注1
private static final int MISSING = 9999;
private final static IntWritable one =new IntWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line= value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()){
word.set(tokenizer.nextToken());
context.write(word,one);
}
}
}
二、pom引用
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.1</version> </dependency>三、如图
四、本地调式
5、远程调式
示例代码:
package com.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Iterator;
import java.util.StringTokenizer;
import java.io.IOException;
/**
* Created by jing on 17/6/6.
*/
public class HdfsUpload {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("参数无效");
System.exit(-1);
}
Configuration conf = new Configuration();
//主要设置
conf.set("fs.defaultFS","hdfs://192.168.46.225:9000");
Job job = Job.getInstance();
job.setJarByClass(HdfsUpload.class);
job.setJobName("HdfsUpload");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
class WcReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Mapper.Context context)
throws IOException, InterruptedException {
int sum= 0;
Iterator<IntWritable> iterator=values.iterator();
while (iterator.hasNext()){
sum +=iterator.next().get();
}
context.write(key,new IntWritable(sum));
}
}
class WcMapper
extends Mapper<LongWritable, Text, Text, IntWritable> { //注1
private static final int MISSING = 9999;
private final static IntWritable one =new IntWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line= value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()){
word.set(tokenizer.nextToken());
context.write(word,one);
}
}
}

相关文章推荐
- Win下用idea远程在hadoop上调试spark程序及读取hbase
- IDEA远程调试hadoop
- windows10下使用idea远程调试hadoop集群
- eclipse/intellij idea 远程调试hadoop 2.6.0
- IDEA远程调试Hadoop步骤及出错解决整理
- win7安装Hadoop2.7.1 ,IDEA本地远程调试
- IDEA远程调试Hadoop步骤及出错解决整理
- Macbook Intellij idea与Eclipse远程调试Hadoop应用程序
- Spark源码IDEA远程调试
- 建立可使用与远程调试的伪分布式Hadoop集群
- [大数据入门-hadoop基础]eclipse远程调试出现Exception in thread "main" java.lang.UnsatisfiedLinkError
- idea中hadoop本地debug调试以及本地提交模式(不需要打jar包上传)
- hadoop远程调试
- 使用Windows上Eclipse远程调试Linux上的Hadoop
- 使用Idea远程部署调试tomcat
- idea中对springboot进行远程调试
- idea 远程调试 tomcat web应用
- Spark基础随笔:Spark1.6 Idea下远程调试的2种方法
- IDEA远程调试
- Eclipse、IntelliJ IDEA远程断点调试