深度学习基础系列(四)之 sklearn SVM
2017-06-05 17:42
357 查看
1、背景
1.1 最早是由 Vladimir N. Vapnik 和 Alexey Ya. Chervonenkis 在1963年提出
1.2 目前的版本(soft margin)是由Corinna Cortes 和 Vapnik在1993年提出,并在1995年发表
1.3 深度学习(2012)出现之前,SVM被认为机器学习中近十几年来最成功,表现最好的算法
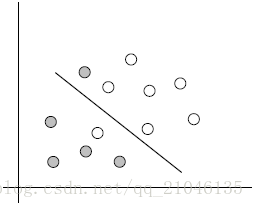
2、举例
2.1 例子
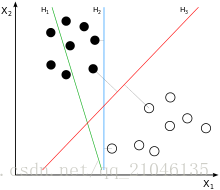
两类?哪条线最好?
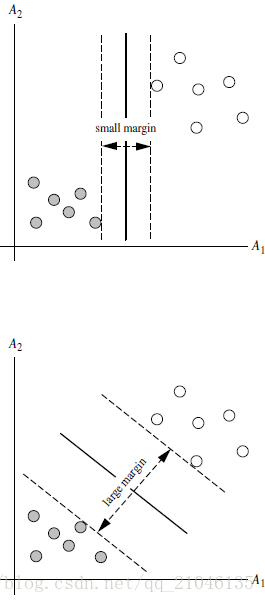
2.2 SVM寻找区分两类的超平面(hyper plane), 使边际(margin)最大
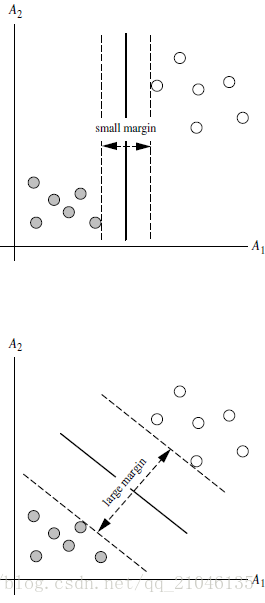
总共可以有多少个可能的超平面?无数条
如何选取使边际(margin)最大的超平面 (Max Margin Hyperplane)?
超平面到一侧最近点的距离等于到另一侧最近点的距离,两侧的两个超平面平行
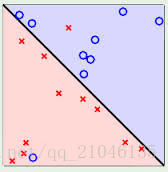
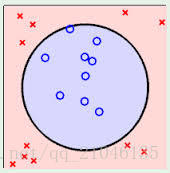
3、线性可区分(linear separable) 和 线性不可区分 (linear inseparable)
4、定义与公式建立
超平面可以定义为:
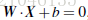
W: weight vectot,
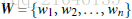
n 是特征值的个数
X: 训练实例
b: bias
4.1 假设2维特征向量:X = (x1, X2)
把 b 想象为额外的 wight
超平面方程变为:
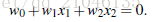
所有超平面右上方的点满足:
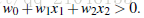
所有超平面左下方的点满足:
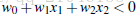
调整weight,使超平面定义边际的两边:
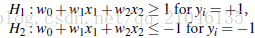
综合以上两式,得到(1):
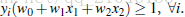
所有坐落在边际的两边的的超平面上的被称作”支持向量(support vectors)
分界的超平面和H1或H2上任意一点的距离为
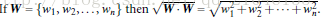
所以,最大边际距离为:2 / || W ||
5、求解
5.1 SVM如何找出最大边际的超平面呢(MMH)?
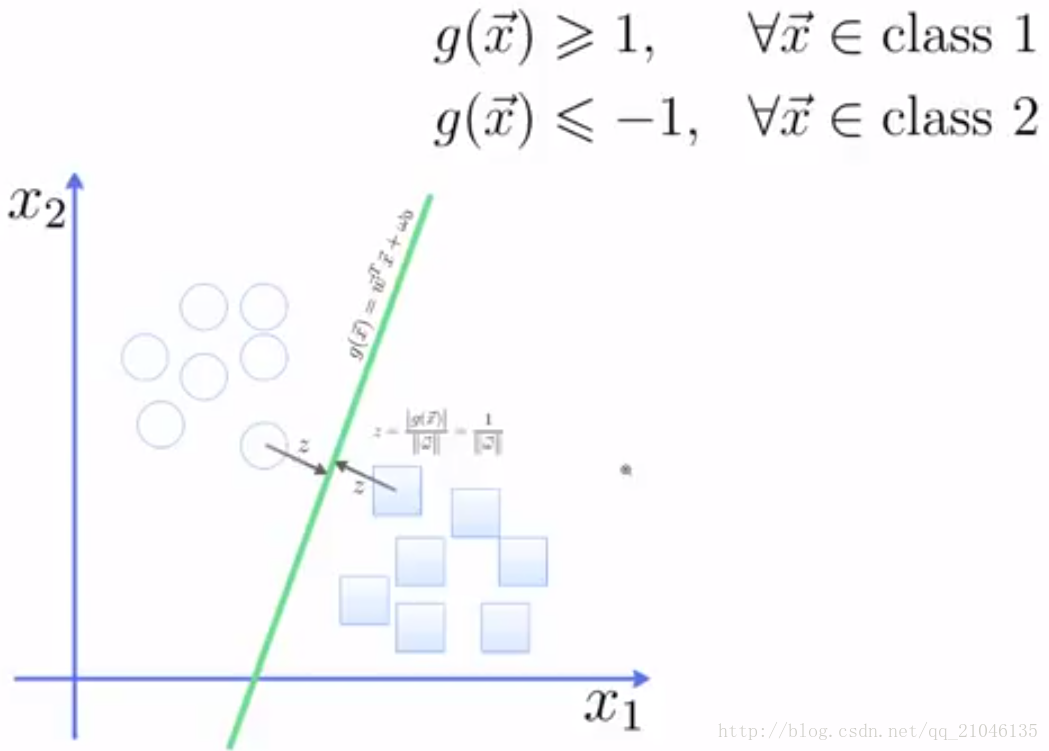
利用一些数学推倒,以上公式 (1)可变为有限制的凸优化问题(convex quadratic optimization) 利用 Karush-Kuhn-Tucker (KKT)条件和拉格朗日公式,可以推出MMH可以被表示为以下“决定边界 (decision boundary)”
其中,
{yi} 是支持向量点{Xi} (support vector)的类别标记(class label)
{X^T}是要测试的实例
{alpha _i} 和 {b0} 都是单一数值型参数,由以上提到的最有算法得出
l 是支持向量点的个数
5.2 对于任何测试(要归类的)实例,带入以上公式,得出的符号是正还是负决定
6、代码:
简单实例:
图例:
输出:
1.1 最早是由 Vladimir N. Vapnik 和 Alexey Ya. Chervonenkis 在1963年提出
1.2 目前的版本(soft margin)是由Corinna Cortes 和 Vapnik在1993年提出,并在1995年发表
1.3 深度学习(2012)出现之前,SVM被认为机器学习中近十几年来最成功,表现最好的算法
2、举例
2.1 例子
两类?哪条线最好?
2.2 SVM寻找区分两类的超平面(hyper plane), 使边际(margin)最大
总共可以有多少个可能的超平面?无数条
如何选取使边际(margin)最大的超平面 (Max Margin Hyperplane)?
超平面到一侧最近点的距离等于到另一侧最近点的距离,两侧的两个超平面平行
3、线性可区分(linear separable) 和 线性不可区分 (linear inseparable)
4、定义与公式建立
超平面可以定义为:
W: weight vectot,
n 是特征值的个数
X: 训练实例
b: bias
4.1 假设2维特征向量:X = (x1, X2)
把 b 想象为额外的 wight
超平面方程变为:
所有超平面右上方的点满足:
所有超平面左下方的点满足:
调整weight,使超平面定义边际的两边:
综合以上两式,得到(1):
所有坐落在边际的两边的的超平面上的被称作”支持向量(support vectors)
分界的超平面和H1或H2上任意一点的距离为
1/|| W ||(其中||W||是向量的范数(norm))
所以,最大边际距离为:2 / || W ||
5、求解
5.1 SVM如何找出最大边际的超平面呢(MMH)?
利用一些数学推倒,以上公式 (1)可变为有限制的凸优化问题(convex quadratic optimization) 利用 Karush-Kuhn-Tucker (KKT)条件和拉格朗日公式,可以推出MMH可以被表示为以下“决定边界 (decision boundary)”
其中,
{yi} 是支持向量点{Xi} (support vector)的类别标记(class label)
{X^T}是要测试的实例
{alpha _i} 和 {b0} 都是单一数值型参数,由以上提到的最有算法得出
l 是支持向量点的个数
5.2 对于任何测试(要归类的)实例,带入以上公式,得出的符号是正还是负决定
6、代码:
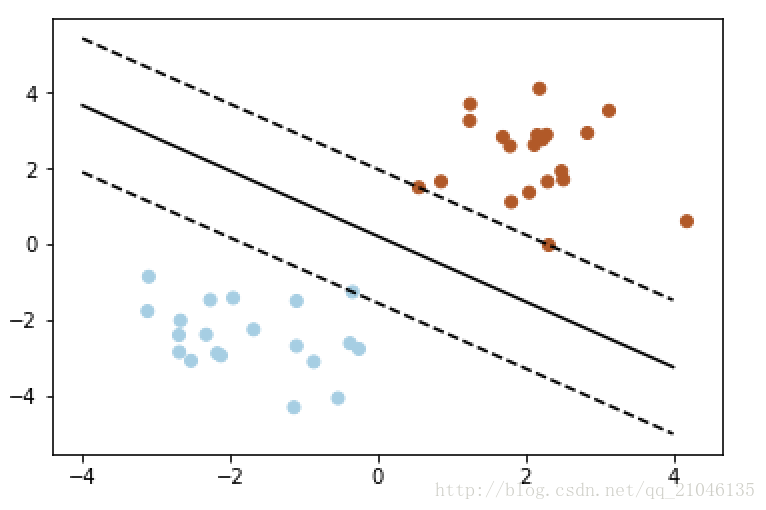
简单实例:
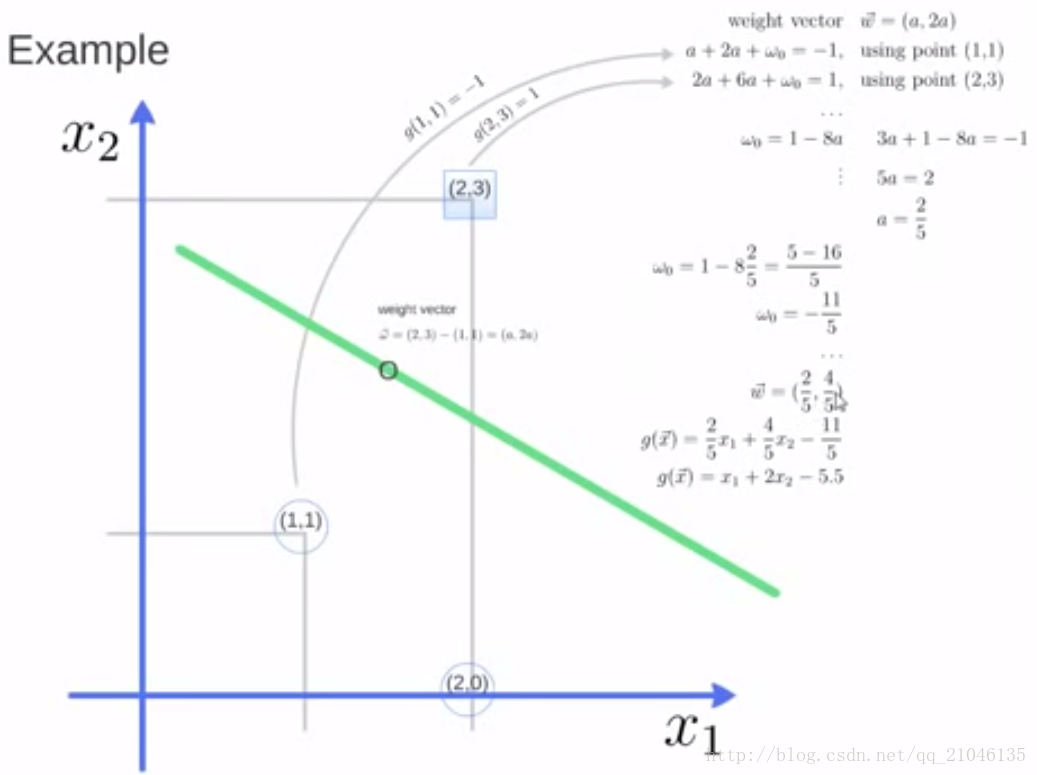
In [65]: from sklearn import svm In [66]: x = [[2, 0], [1, 1], [2, 3]] In [67]: y = [0, 0, 1] In [68]: clf = svm.SVC(kernel = 'linear') In [69]: clf.fit(x, y) Out[69]: SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape=None, degree=3, gamma='auto', kernel='linear', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False) In [70]: print(clf) SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape=None, degree=3, gamma='auto', kernel='linear', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False) In [71]: clf.support_vectors_ Out[71]: array([[ 1., 1.], [ 2., 3.]]) In [72]: clf.support_ Out[72]: array([1, 2], dtype=int32) In [73]: clf.n_support_ Out[73]: array([1, 1], dtype=int32)
图例:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Tue May 30 09:27:21 2017
@author: xiaolian
"""
print(__doc__)
import numpy as np
import pylab as pl
from sklearn import svm
# we create 40 separable points
np.random.seed(1)
X = np.r_[np.random.randn(20, 2) - [2, 2], np.random.randn(20, 2) + [2, 2]]
Y = [0] * 20 + [1] * 20
# fit the model
clf = svm.SVC(kernel='linear')
clf.fit(X, Y)
# get the separating hyperplane
w = clf.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(-4, 4)
yy = a * xx - (clf.intercept_[0]) / w[1]
# plot the parallels to the separating hyperplane that pass through the
# support vectors
b = clf.support_vectors_[0]
yy_down = a * xx + (b[1] - a * b[0])
b = clf.support_vectors_[-1]
yy_up = a * xx + (b[1] - a * b[0])
print("w: ", w)
print("a: ", a)
# print " xx: ", xx
# print " yy: ", yy
print("support_vectors_: ", clf.support_vectors_)
print("clf.coef_: ", clf.coef_)
# In scikit-learn coef_ attribute holds the vectors of the separating hyperplanes for linear models. It has shape (n_classes, n_features) if n_classes > 1 (multi-class one-vs-all) and (1, n_features) for binary classification.
#
# In this toy binary classification example, n_features == 2, hence w = coef_[0] is the vector orthogonal to the hyperplane (the hyperplane is fully defined by it + the intercept).
#
# To plot this hyperplane in the 2D case (any hyperplane of a 2D plane is a 1D line), we want to find a f as in y = f(x) = a.x + b. In this case a is the slope of the line and can be computed by a = -w[0] / w[1].
# plot the line, the points, and the nearest vectors to the plane
pl.plot(xx, yy, 'k-')
pl.plot(xx, yy_down, 'k--')
pl.plot(xx, yy_up, 'k--')
pl.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
s=80, facecolors='none')
pl.scatter(X[:, 0], X[:, 1], c=Y, cmap=pl.cm.Paired)
pl.axis('tight')
pl.show()输出:

相关文章推荐
- 深度强化学习系列(二):强化学习基础
- 深度学习与计算机视觉系列(1)_基础介绍
- 深度学习与计算机视觉系列(1)_基础介绍
- 深度学习与计算机视觉系列(1)_基础介绍
- 深度学习与计算机视觉系列(1)_基础介绍
- 深度学习基础系列(六)| 权重初始化的选择
- 深度学习DeepLearning.ai系列课程学习总结:2. 神经网络基础
- 深度学习基础系列(三)之用 sklearn 实现 KNN算法
- 深度学习基础系列 (二) 用 sklearn 实现 ID3 算法
- 深度学习与计算机视觉系列(1)_基础介绍
- 深度学习与计算机视觉系列(1)_基础介绍
- 深度学习框架Keras学习系列(一):线性代数基础与numpy使用(Linear Algebra Basis and Numpy)
- 福利 | Intel发布AI免费系列课程3部曲:机器学习基础、深度学习基础以及TensorFlow基础
- 深度学习与计算机视觉系列(1)_基础介绍
- 深度学习与计算机视觉系列(1)_基础介绍
- 深度学习基础系列 (一) 之基础概念
- 深度学习与计算机视觉系列(1)_基础介绍
- 深度学习与计算机视觉系列(1)_基础介绍
- caffe+神经网络+深度学习全零基础系列学习链接
- 深度学习与计算机视觉系列(1)_基础介绍